
1.2018年の機械学習とAIの主な進歩と2019年の主な傾向(2/2)まとめ
・ELMoやBERTなどの自然言語処理分野におけるトランスファーラーニングの成功
・プライバシー問題やAIのディストピアに繋がる利用が注目を集めた事
・オンラインコースなど教育を受ける機会の増加と研究から実務への役割移行
2.2018年のAIとデータサイエンスの進歩のまとめ
以下、www.kdnuggets.comより「Machine Learning & AI Main Developments in 2018 and Key Trends for 2019」の意訳です。元記事は2018年12月、Matthew Mayoさんの投稿です。立場によって注目ポイントがまるで違うところが興味深いですがELMoやBERTは注目度が高いですね。前半からの続きです。
7)Matthew Mayo (@mattmayo13) KDnuggetsの編集者
私にとって、2018年の機械学習(ML)は主に洗練が行われた年と思います。例えば、特にfast.aiのULMFiT(Universal Language Model Fine-tuning for Text Classification)やGoogleのBERT(Bidirectional Encoder Representations from Transformers)のような技術のおかげで、自然言語処理分野でトランスファーラーニング(転送学習)がより広く応用されて関心を集めました。
そして、これらが昨年の自然言語処理における唯一の進歩ではありません。更に注目すべきは、Allen研究所のELMo(Embeddings from Language Models)です。深く文脈を理解して単語特徴表現を作り出すモデルであり、ELMoを採用した全てのタスクに対してかなりの改善をもたらしました。 また、今年の他のブレークスルーとしては、BigGANなどの既存のテクノロジの改良が中心であったようです。
更に、非技術的な事では、多数のコミュニティメンバーの声のおかげで包含と多様性への配慮をする事が機械学習分野でも主流なりました。(一例としてNeurIPSを参照してください)。
訳注:昨年の自然言語処理における進歩についてはニューヨークタイムズの記事「遂に機械は文脈を理解し始めました」がわかりやすいです。NeurIPSの件は「NIPSがNeurIPSへ略称の変更を実施」にまとまっています。
2019年には、潜在的なアプリケーションがますます実現されているので、研究の注目は、教師あり学習から強化学習や半教師つき学習のような分野に移ると考えています。私たちは今、画像認識と画像生成を「解決」したところです。そして、その過程で学んだことが、機械学習のより複雑な応用の追求において研究者を助けることができます。
アマチュアのAutoMLの伝道師として。私たちは、最新の教師付き学習で、アルゴリズムの選択やハイパーパラメーターの最適化ができるようになるまで、AutoMLの漸進的な進歩を見続ける事になるでしょう。
AutoMLは、「実務家達の仕事を奪う」事から「実務家達を強化する事」に認識が広範に変わると思います。(またはすでに転換点に達しているかもしれません)。AutoMLは、もはや機械学習ツールボックスの代わりになるのではなく、ツールボックスの中に含めるべきもう1つのツールとして恐れられなくなります。逆に、実務家が日常的なシナリオでこれらのツールを選択肢の一つとして定期的に使用し、その方法を知っている事が期待されるようになるのは、当然の結論と思います。
8)Brandon Rohrer (@_brohrer_) FaceBookのデータサイエンティスト
2018年の1つの重要な傾向は、データサイエンスの教育を受ける機会の急増と成熟です。特にオンラインコースは、オリジナルのデータサイエンス教育の場で、毎年、より多くの学生、多様なコースとトピック、あらゆるレベルで人気を博しています。
学術の世界では、新しいデータサイエンスの修士課程が年間1ダースの割合で開始されています。私が関わっている高等教育機関は、企業や学生の要望に応えて、データ関連分野に特化したプログラムを提供しています。(今年、18人の業界共著者と11人の学術的貢献者とともに、この爆発的な成長を支えるための仮想業界アドバイザリーボードを結成しました。)
その一方で非公式なチュートリアルブログの投稿もいたるところにあります。彼らは、彼らの読者と彼らの作家の両方にとって、データサイエンスの共同理解に大いに貢献しています。
2019年以降、学術データサイエンスプログラムは、最初のデータサイエンスの仕事を獲得するために必要なベースラインスキルを身に着けるためのより一般的な方法になります。これはいいことです。認定の対象となる機関は、長年の格差を埋めます。これまでのところ、データサイエンス資格は、大部分は以前の実務的経験を通して実証されていました。これにより仕事を得たいが実務経験がないので仕事を得る事ができないと言う板挟み状態が発生していました。新しいデータサイエンティストは、データサイエンスの仕事をしたことがないため実績を示すことができず、実績を示すことができないためデータサイエンスの仕事を得ることができません。教育機関からの認定情報は、このサイクルを打破する1つの方法です。
しかし、オンラインコースはどこにも移動しません。大学教育の時間と金銭的なコミットメントによって入学を断念している人は沢山います。オンラインコースが確立された今、データサイエンス教育は常に実用的な道をたどるでしょう。プロジェクト作業の実証、関連する経験、およびオンライントレーニングを通じて、新しいデータサイエンティストは学位なしでも自分のスキルを実証することができます。オンラインコースやチュートリアルは、データサイエンス教育にとって、より一般的で洗練された、そしてより重要なものとなり続けるでしょう。実際、いくつかの著名なデータサイエンスおよび機械学習プログラムは、コースをオンラインにすることを目的としており、未入学の学生でも登録可能になるオプションを提供しています。私はデータサイエンス大学の学位とオンライントレーニングカリキュラムの間の境界線が曖昧になり続けることを期待しています。私の考えでは、これが「データサイエンスの民主化」の真の形です。
9)Elena Sharova ITVのデータサイエンティスト
Q:2018年の機械学習(ML)と人工知能(AI)の主な出来事は何ですか?
私の見解では、2018年は次の3つの出来事によってAIとMLのコミュニティに記憶されるでしょう。
第一に、個人データの使用の公平性と透明性を高めることを目的としたGDPR(EUグローバルデータ保護規則)の開始です。この規制により、個人データを管理し、その使用方法に関する情報にアクセスする個人の権利が明らかになりましたが、法の解釈に多少の混乱が生じました。今日までの最終結果は、多くの会社が自らはGDPRを準拠していると解釈してデータ処理にいくつかの表面的な変更を加えるだけに留め、データストレージとデータ処理のためにインフラストラクチャを再設計する必要性を無視しています。
次に、Cambridge Analyticaスキャンダルがありました。これは、データサイエンス(DS)コミュニティ全体に暗い影を落としました。以前の議論が主にAIとMLの「製品の公正」さを保証することに関するものであったならば、このスキャンダルはより深い倫理的性質の問題を引きつけましたた。Facebookの関与についての最新の調査は、この問題がすぐには解決しないことを意味しています。データサイエンスの分野が成熟するにつれて、こうした発展は政治を超えて多くの業界で起こります。
訳注:Cambridge Analytica社がFaceBookから入手した数千万人分の個人情報を元にイギリスの欧州連合離脱是非を問う国民投票や2016年のアメリカ合衆国大統領選挙において、世論に影響を及ぼしたとされる問題です。
アリゾナ州のUber自動運転車の事故のように、より悲劇的なケースもあり、そういった事件後には世間からの非難が続くでしょう。技術は力であり、力には責任があります。 ノアム・チョムスキーが言ったように、「悪を破壊するために力が賢くそして上手に使われるのは民話、おとぎ話、そして知的な日記の中だけです。現実の世界はまるで異なる事例がある事を教えてくれます。それらに気付かないためには、見て見ないふりをするか完全に無知である事が必要です。」
最後に、より肯定的な事は、Amazonによる独自サーバープロセッサチップの開発は、クラウドコンピューティングへの一般的なアクセスがもはやコストの問題ではなくなる日が近づいていることを意味しています。
Q:2019年にはどのような主な傾向が予想されますか?
データサイエンティストの役割と責任は、正確な予測を達成するモデルを構築することを超えて拡大していきます。ML、AI、およびデータサイエンティストの実務家にとっての2019年の主な傾向は、特にテストと保守に関して、確立されたソフトウェア開発実務に従う責任が高まることです。
データサイエンスの最終製品は、企業内の他のテクノロジー群と共存する必要があります。商用ソフトウェアの効率的な運用とメンテナンスのための要件は、データサイエンティストが構築するモデルとソリューションにも適用されます。これは、ソフトウェア開発のベストプラクティスが、私たちが従う必要がある機械学習のルールにも関わる事を意味します。
10)Rachel Thomas(@math_rachel)fast.aiの創設者
2018年の2つの主なAI開発は次のとおりです。
1.NLPへのトランスファーラーニング(転移学習)の適用の成功
2.ディストピア(訳注:ユートピアの逆。暗黒郷)に繋がるAIの誤用への関心の高まり(ヘイトグループおよび権力者による監視や操作を含みます)
トランスファーラーニングは、事前学習させたモデルを新しいデータセットに適用する方法です。トランスファーラーニングはコンピュータビジョンの進歩の急増における重要な要素であり、2018年にはfast.aiとSebastian Ruder氏によるULMFiT、Allen研究所のELMo、OpenAIのトランスフォーマーアーキテクチャを用いた研究、そしてGoogleのBertなどでトランスファーラーニングが自然言語処理にうまく適用できました。前述のNY Timesの記事で説明したように、これらの進歩は興奮と懸念の両方の原因となっています。
ミャンマーでの大虐殺におけるFacebookの決定的役割、YouTubeは陰謀論を不当に推薦しており(その多くは白人の優越性を主張しています)、政府や法執行機関による監視のためのAIの使用はようやく2018年に主流メディアの注目を集め始めました。AIのこれらの誤用は深刻で怖いものですが、より多くの人々がそれらを認識し、徐々に押し戻しているのは良い傾向です。
訳注:ミャンマーのイスラム教徒ロヒンギャに対するヘイトを広める為にFaceBookが広く活用されていると2018年3月に国連のミャンマー調査団が指摘しました
2019年もこれらの傾向が続くと予想されます。NLPの急速な進歩(Sebastian Ruderがこの夏に書いたように、「NLPのImageNetの瞬間がやってきています」)と同様に、危険な政治運動によってディストピア利用(監視、暴力の誘惑、および世論操作など)のためのAI開発も続くでしょう。
11)Daniel Tunkelang(@dtunkelang)ML/AIを専門とする独立系コンサルタント
2018年には、自然言語処理と理解のための単語埋め込み表現(word embeddings)の高度化において2つの大きな進歩がありました。
最初の動きは3月にありました。Allen研究所とワシントン大学の研究者は論文「Deep contextualized word representations」の中でELMo(Embeddings from Language Models)を発表しました。
これは、word2vecやGloVeのような文脈を無視(context-free)するモデルを改善する、オープンソースの深く文脈化(contextual)されたモデルです。著者らは、単にELMoで事前訓練したモデルからのベクトルを代用することによって、既存のNLPシステムが大きく改善される事を実証しました。
訳注:ちなみにELMOはセサミストリートに登場する好奇心旺盛な真っ赤な毛むくじゃらのモンスターの名前でもあります。

そして、「ELMoによって既存のNLPシステムが大きく改善された結果」として引用される事があるMatthew Petersさん作成のグラフは下記です。驚くほど印象に残るグラフで、インフォグラッフィクスの好例です。
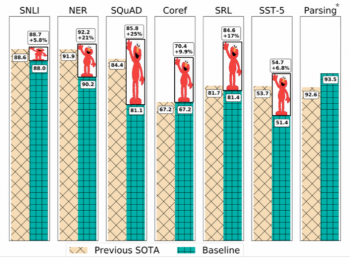
2番目は11月でした。Googleが公開したオープンソースのBERT(Bidirectional Encoder Representations from Transformers)、双方向の教師なし言語特徴表現はウィキペディアで事前にトレーニングされました。著者等が論文「BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding」で示したように、彼らはELMoと比較しても、幅広いNLPベンチマークで大幅な改善を達成しました。
訳注:ちなみにBERTもセサミストリートに登場するキャラクターです。遊んでるなぁーっと。
スマートスピーカーの急速な普及(2018年末までに最大で1億)とスマートフォンでのデジタルアシスタントのため、自然言語理解の進歩は研究所から現実世界の製品へと瞬時に移行しています。現在は自然言語処理の研究と実践のための刺激的な時代です。
しかし、まだまだ先は長いのです。
2018年、Allen研究所の研究者たちは、常識的な理解を必要とする文章完成問題のためのデータセットである「Swag:A Large-Scale Adversarial Dataset for Grounded Commonsense Inference」を公開しました。彼らの実験は、最先端のNLPがまだ人間のパフォーマンスよりはるかに遅れていることを示しました。
しかし、うまくいけば、私たちは2019年にもっと自然言語処理がブレークスルーする事を見ることになるでしょう。コンピュータサイエンスの最高の精神の多くがそれに取り組んでいます、そして、業界は彼らの成果を実用化することに熱心です。
(2018年の機械学習とAIの主な進歩と2019年の主な傾向(1/2)からの続きです)
3.2018年の機械学習とAIの主な進歩と2019年の主な傾向(2/2)関連リンク
1)www.kdnuggets.com
Machine Learning & AI Main Developments in 2018 and Key Trends for 2019
2)thegradient.pub
NLP’s ImageNet moment has arrived

コメント