
1.FILM:2つの異なる写真の間を補完して動画を生成(1/2)まとめ
・フレーム補間とは与えられた画像セットから中間画像を合成する事
・写真間を補間することで臨場感のある魅力的な映像にしたり応用範囲が広い
・FILMは複製に近い写真から高画質のスローモーション動画を作成する手法
2.Filmとは?
以下、ai.googleblog.comより「Large Motion Frame Interpolation」の意訳です。元記事の投稿は2022年10月4日、Fitsum RedaさんとJanne Kontkanenさんによる投稿です。
アイキャッチ画像はstable diffusionの生成でフィルムに写っているトトロ
2022年10月追記)FILMを使ったサンプルを「stable diffusionで生成した画像から動画を生成する」として掲載しました。
フレーム補間(Frame interpolation)は、与えられた画像セットから中間画像を合成するプロセスです。この技術は、動画のリフレッシュレートを上げるための時間軸のアップサンプリングや、スローモーション効果を生み出すためによく利用されます。
今日のデジタルカメラやスマートフォンでは、数秒間に何枚もの写真を撮影し、ベストショットを狙うことが多くなっています。このような「わずかに違う複製に近い写真」間を補間することで、撮影風景の動きを表現し、元の写真よりもさらに臨場感のある魅力的な映像にすることができます。
動画像のフレーム補間は、動きの少ない連続したフレームを補間することが広く研究されています。しかし、動画と異なり、複製された写真間の時間的間隔は数秒に及ぶことがあり、それに伴い写真間の動きも大きくなるため、既存のフレーム補間手法の大きな欠点となっています。最近の手法では、動きが激しいデータセットで学習することで大きな動きを処理することを試みていますが、小さな動きに対する効果は限定的です。
ECCV2022で発表された論文「FILM: Frame Interpolation for Large Motion」では、複製に近い写真から高画質のスローモーション動画を作成する手法を紹介します。FILMは、大きな動きで最先端の結果を達成しながら、小さな動きもうまく処理する新しいニューラルネットワークアーキテクチャです。

FILM 複製に近い2枚の写真の間を補間して、スローモーション動画を作成します。
FILMモデルの概要
FILMモデルは2枚の画像を入力とし、中間画像を出力します。推論時に、このモデルを再帰的に呼び出して中間画像を出力します。
FILMは3つの要素から構成されています。
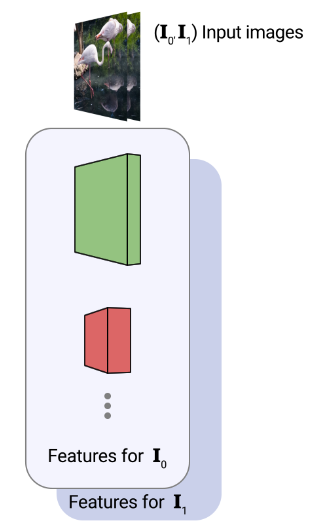
(1)各入力画像を深いマルチスケール(ピラミッド)特徴で要約する特徴抽出器
(2)各ピラミッドレベルにおける画素単位の動き(すなわちフロー)を計算する双方向動き推定器
(3) 最終補間画像を出力するフュージョン・モジュール。
FILMの学習は、通常のビデオフレーム3枚組で行い、中央のフレームを教師用の検証済データとして使用します。
スケールに依存しない特徴抽出
大きな動きに対しては、多解像度特徴ピラミッド(multi-resolution feature pyramids)を用いた階層的な動き推定が一般的です。(上図)
しかし、この方法は、小さくて動きの速い物体がピラミッドの最深部で消えてしまうことがあるため、苦労しています。また、最深部での教師を行うための画素数が圧倒的に少なくなります。
そこで、スケールによらず重みを共有する特徴抽出器を採用し、「スケールによらない」特徴ピラミッドを作成します。この特徴抽出器により、(1)浅いレベルの大きな動きと深いレベルの小さな動きを同一視することで、ピラミッドレベル間で共有する動き推定器(次節)の使用が可能となり、(2)少ない重みを持つコンパクトなネットワークが構築されます。
具体的には、まず、2枚の入力画像が与えられた場合、各画像を順次ダウンサンプリングして画像ピラミッドを作成します。
次に、共有のU-Net畳み込みエンコーダを用いて、画像ピラミッドの各レベル(下で説明する各行)から、より小さな特徴ピラミッドを抽出します。
最後の第3ステップとして、同じ空間次元を持つ異なる畳み込み層からの特徴を水平方向に連結することで、スケールに依存しない特徴ピラミッドを構築します。
3階層目以降は、共通の畳み込み重みのセット(同じ色で表示)で特徴スタックを構成している事に着目してください。これにより、すべての特徴が類似していることが保証され、後続の動き推定器において重みを共有し続けることができるようになります。下図では、4つのピラミッドレベルを用いてこのプロセスを描いていますが、実際には7つのレベルを用いています。
双方向のフロー推定
特徴抽出後、FILMはピラミッドベースの残差フロー推定を行い、まだ予測されていない中間画像から2つの入力へのフローを計算します。フロー推定は各入力に対して1回ずつ行われ、最も深いレベルから順に、畳み込みのスタックを用いて行われます。
次に深いレベルからのアップサンプル推定値に残差補正を加えることで、そのレベルのフローを推定します。この方法は、(1)そのレベルの最初の入力の特徴量、(2)アップサンプルされた推定値でワープした後の2番目の入力の特徴量を入力とするものです。
同じ畳み込みの重みが、2つの最も細かいレベルを除くすべてのレベルにわたって共有されます。
重みの共有により、深いレベルの小さな動きも浅いレベルの大きな動きと同じように解釈できるようになり、大きな動きの監視に利用できる画素数が増加します。さらに、重みの共有は、より高いピーク信号対雑音比(PSNR:Peak Signal-to-Noise Ratio)に達する可能性のある強力なモデルの学習を可能にするだけでなく、実用的なアプリケーションのためにモデルがGPUメモリに収まるようにするためにも必要です。

重みの共有が画質に与える影響
左:共有なし、右:共有あり
このアブレーション研究には、私達のモデルの小型版(論文内ではFILM-medと呼んでいます)を使用しました。なぜなら、重み共有なしの完全モデルでは、重み共有の正則化の利点が失われるため、発散してしまうからです。
融合とフレーム生成
双方向フローを推定した後、2つの特徴ピラミッドをワープして位置合わせを行います。そして、各ピラミッドレベルにおいて、位置合わせされた2つの特徴マップ、双方向フロー、入力画像を積み重ね、連結した特徴ピラミッドを得ます。最後に、U-Netデコーダが、位置合わせされ、積み重ねた特徴ピラミッドから補間された出力画像を合成します。

FILMの概要
特徴抽出: スケールに依存しない特徴を抽出します。共有重みを用いて、色が一致する特徴を抽出します。
フローの推定:より深いピラミッドレベルにまたがる共有重みを用いて双方向のフローを計算します。そして、その特徴を整列させるためにワープさせます。
融合:U-Netデコーダが最終的に補間されたフレームを出力します。
3.FILM:2つの異なる写真の間を補完して動画を生成(1/2)関連リンク
1)ai.googleblog.com
Large Motion Frame Interpolation
2)arxiv.org
FILM: Frame Interpolation for Large Motion
3)film-net.github.io
FILM: Frame Interpolation for Large Motion

