
1.LOLNeRF:1枚の画像から3次元構造を学ぶ(1/2)まとめ
・2次元画像から3次元形状を理解する手法は複数視点のデータに依存している
・1枚の画像から3次元構造を知ることができると便利だが解決困難とされている
・LOLNeRFは単一視点画像の集まりから3D構造と外観を学習するフレームワーク
2.LOLNeRFとは?
以下、ai.googleblog.comより「LOLNeRF: Learn from One Look」の意訳です。元記事の投稿は2022年9月13日、Daniel RebainさんとMark Matthewsさんによる投稿です。
アイキャッチ画像はstable diffusionで三次元モデル化されたトトロ
人間の視覚の重要な側面は、観察した2次元画像から3次元形状を理解する能力です。このような理解をコンピュータ視覚システムで実現することは、この分野の根本的な課題でした。
多くの成功したアプローチは、マルチビューデータに依存しています。マルチビューデータは、同じ風景を異なる視点から撮影した2つ以上の画像であり、これがあれば画像内の物体の3次元形状を推測することが非常に容易になります。
しかしながら、1枚の画像から3次元構造を知ることができれば便利な場面も多く、そして、この問題は一般に解決困難、あるいは不可能とされています。
例えば、本当の海岸を撮影した画像と、同じ海岸が掲載されている平面ポスターの画像を見分けることは必ずしも可能ではありません。しかし、どのような立体物が通常存在するか、また、同じような立体物を別の視点から見るとどのように見えるか、といった情報をもとに、立体構造を推定することは可能です。
CVPR 2022で発表した「LOLNeRF: Learn from One Look」では、単一視点画像のコレクションから3D構造と外観のモデルを学習するフレームワークを提案します。LOLNeRFは、自動車、人間の顔、猫などの物体のクラスの典型的な3D構造を学習しますが、任意の1つの物体については単一の視点からのみであり、同じ物体を他の視点から2度以上見ることはありません。
私達は、Generative Latent Optimization(GLO)とNeural Radiance Field(NeRF)を組み合わせるこの手法を構築し、新規視点合成で最先端の結果を、奥行き推定で競争力のある結果を達成します。
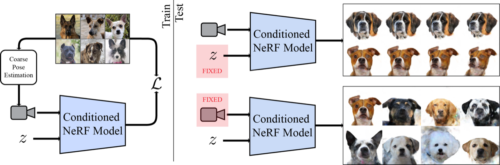
潜在ベクトルz(左)で条件付けするニューラルネットワークを用いて、大量の単一視点画像を再構成することで、3次元物体モデルを学習します。これにより、画像から3次元モデルを抽出し、新たな視点からレンダリングすることができます。カメラを固定したまま、新しいアイデンティティを補間したり、サンプリングしたりすることができます(右)
GLOとNeRFの組み合わせ
GLOは、ニューラルネットワーク(デコーダ)と、デコーダの入力でもある(潜伏的な)コードテーブルを協調学習することで、データセット(2次元画像群など)の再構成を学習する汎用的な手法です。
潜在的なコードはそれぞれ、データセットから1つの要素(画像など)を再作成します。潜在コードはデータ要素よりも次元数が少ないため、ネットワークは一般化を余儀なくされ、データ内の共通構造(例えば犬の鼻の一般的な形状)を学習します。
NeRFは、2次元画像から静的な3次元物体の復元を得意とする技術です。3次元空間の各点について、色と密度を出力するニューラルネットワークで物体を表現します。色と密度の値はカメラ射線に沿って蓄積され、2次元画像の各画素に1本の線が割り当てられます。そして、これらを標準的なコンピュータグラフィックスのボリュームレンダリングで合成し、最終的な画素の色を計算します。
重要なのは、これらの演算はすべて微分可能であるため、直接の教師が可能であることです。レンダリングされた各画素(3D特徴表現)が、真実の画素(二次元)の色と一致することを強制することで、ニューラルネットワークは3D特徴表現を作成します。これにより、ニューラルネットワークは、どのような視点からもレンダリング可能な3D表現を作成します。
各物体に潜在的なコードを割り当て、それを標準的なNeRFの入力と連結することで、NeRFとGLOを組み合わせ、複数の物体を再構築する能力を持たせています。
GLOに続き、学習時にこれらの潜在コードとネットワークの重みを協調して最適化し、入力画像の再構成を行います。
同じ物体の複数の視点を必要とする標準的なNeRFとは異なり、本手法は1つの物体につき単一視点(ただし同じタイプの物体の複数のサンプル)のみを用いて教師とします。
NeRFは本質的に3次元であるため、任意の視点から対象物をレンダリングすることが可能です。NeRFとGLOを組み合わせることで、データセットの特定の実体を再現する能力を維持したまま、単一視点のみから実体間で共通の3D構造を学習することができます。
3.LOLNeRF:1枚の画像から3次元構造を学ぶ(1/2)関連リンク
1)ai.googleblog.com
LOLNeRF: Learn from One Look
2)ubc-vision.github.io
LOLNeRF: Learn from One Look

