
1.ロボットが地形を見て適切な歩き方を選択できるようになる(1/2)まとめ
・4足歩行ロボットの能力は大幅に向上したが不整地を対象とした研究は少ない
・不整地では地形特性の推定が重要だが既存の知覚運動システムでは困難
・階層的な学習フレームワークを設計し環境の状況に注目した手法を新規に開発
2.人間の操作デモを元にロボットが適切な速度を学習
以下、ai.googleblog.comより「Learning to Walk in the Wild from Terrain Semantics」の意訳です。元記事は2022年9月9日、Yuxiang Yangさんによる投稿です。
アイキャッチ画像はstable diffusionによる生成で山道を登るメカトトロ
四足歩行ロボット(quadrupedal robots)の重要な将来性は、人間にとって困難またはアクセスできない複雑な屋外環境で活動できる可能性があることです。山奥で天然資源を探すにも、甚大な被害を受けた地震現場で生命信号を探すにも、堅牢で汎用性の高い四足歩行ロボットがあれば非常に役立つでしょう。
そのためには、ロボットが環境を知覚し、現在状況での運動に関する課題を理解し、それに応じて運動スキルを適応させることが必要です。近年の知覚型ロボットの進歩により、4足歩行ロボットの能力は大幅に向上しましたが、ほとんどの研究は屋内や都市環境を対象としており、不整地の複雑な地形に効果的に対処することはできません。
このような環境では、地形の形状(傾斜角、平滑度など)だけでなく、接触特性(摩擦、復元、変形性など)を理解する必要があります。これらは、ロボットが運動能力を決定する上で重要な要素です。既存の知覚運動システムでは、深度カメラやLiDARの利用が主流であるため、このような地形特性を正確に推定することが困難である場合があります。
論文「Learning Semantics-Aware Locomotion Skills from Human Demonstrationsでは、複雑な不整地環境におけるロボットの踏破能力を向上させるために、階層的な学習フレームワークを設計します。地形の形状や障害物の位置などの環境内の位置に注目した従来のアプローチとは異なり、私達は、地形の種類(草、泥など)や接触特性などの環境の状況に注目し、不整地環境で有用な情報を補完的に提供します。
ロボットが歩行する際、フレームワークは知覚した状況に基づいてロボットの速度や歩行(脚の動きの形状やタイミング)などの移動技能を決定し、岩、小石、深い草、泥など様々な不整地地形でロボットが頑健に歩行できるようにします。

本フレームワークは、カメラのRGB画像からロボットのスキル(歩行パターンと速度)を選択します。まず、地形状況から速度を計算し、その速度に基づいて歩行パターンを選択します。
概要
階層型フレームワーク(hierarchical framework)は、上位のスキルポリシーと下位のモータコントローラで構成されます。スキルポリシーはカメラ映像から運動スキルを選択し、モータコントローラは選択されたスキルをモータコマンドに変換します。
高レベルのスキルポリシーは、さらに学習型の速度ポリシーと経験則に基づいた歩行スタイル選択器に分解されます。スキルの決定には、まず速度ポリシーがオンボードRGBカメラからの意味的情報に基づいて、望ましい前進速度を計算します。
四足歩行ロボットはエネルギー効率と堅牢性の観点から、通常、速度ごとに異なる歩行スタイルを選択するため、歩行スタイル選択器は前進速度に基づいて望ましい歩行スタイルを計算するよう設計しました。最後に、低レベルの凸型モデル予測コントローラ(MPC:Model-Predictive Controller)が、所望の運動スキルをモータの出力コマンドに変換し、実ハードウェア上で実行します。
速度制御は、標準的な強化学習アルゴリズムに比べて学習データが少ない模倣学習を用いて、実世界で直接学習させます。
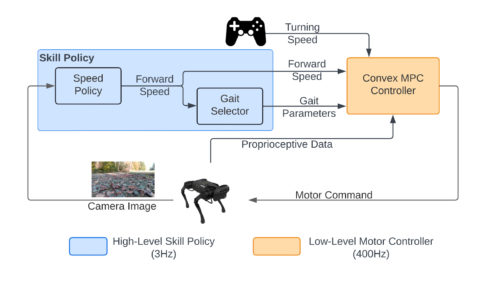
このフレームワークは、高レベルのスキルポリシーと低レベルのモーターコントローラで構成されています。
人間が行ったデモから適切な速度指令を学習
本パイプラインの中心的なコンポーネントである速度ポリシーは、搭載カメラのRGB画像からロボットの望ましい前進速度を出力します。
多くのロボット学習タスクは、シミュレーションを活用することで低コストでデータ収集が可能ですが、複雑で多様な不整地環境の正確なシミュレーションがまだ利用できないため、実世界で速度ポリシーの学習を行います。実世界での学習は時間がかかり、安全性にも問題があるため、データ効率と安全性を向上させるために2つの重要な設計上の選択を行いました。
1つ目は、人間が行ったデモンストレーションから学習することです。標準的な強化学習アルゴリズムは通常、エージェントが環境中で様々な行動を試み、受け取った報酬に基づいて環境設定を構築する探索によって学習します。
しかし、このような探索は、特に不整地環境では、ロボットの故障がロボットのハードウェアや周辺環境の両方を損傷する可能性があるため、潜在的に安全でない可能性があります。そこで、安全性を確保するために、人間のデモンストレーションを用いた模倣学習により、速度制御の学習を行います。
まず、人間のオペレータに様々な不整地でロボットを遠隔操作してもらい、オペレータは遠隔ジョイスティックでロボットの速度と方位を制御します。次に、動作記録(画像と前進速度のペア)を保存することで学習データを収集します。そして、標準的な教師あり学習を用いて、人間の操作者の速度指令を予測する速度ポリシーを学習します。その結果、人間のデモは安全かつ高品質であり、ロボットが異なる地形に対して適切な速度選択を学習できるようになりました。
3.ロボットが地形を見て適切な歩き方を選択できるようになる(1/2)関連リンク
1)ai.googleblog.com
Learning to Walk in the Wild from Terrain Semantics
2)arxiv.org
Learning Semantics-Aware Locomotion Skills from Human Demonstration

