
1.ByteQRNN:BERTの1/300のサイズで同等性能なオンデバイスモデル(2/2)まとめ
・ByteQRNNはマージAttentionサブレイヤーと量子化ビーム探索で計算を効率化している
・事前学習済みのByteQRNNの性能は、300倍小さいにもかかわらず、BERTと同等だった
・ByteQRNNに加えてByteTransformerとByteFunnelTransformerの2つのモデルも公開
2.ByteQRNNの性能
以下、ai.googleblog.comより「Efficient Sequence Modeling for On-Device ML」の意訳です。元記事は2022年8月3日、Arun Kandoorさんによる投稿です。
アイキャッチ画像はlatent diffusionでプロンプトはByteQRNN
入力のembeddings(つまり、前述のembeddingsレイヤーからの出力)に加えて、私達はさらに一歩進んで、効果的なシーケンス間(seq2seq)モデルを構築します。これはByteQRNNにTransformerベースのデコーダモデルと量子化ビーム探索(または木探索)を追加することで実現します。
量子化ビーム探索モジュールは、デコーダ出力生成時の推論待ち時間を低減します。前と現在の確率の対数和を用いて最も可能性の高いビーム(すなわち、可能な出力シーケンス)を計算し、その結果得られたトップビームを返す事でこれを行います。ここでは、一般的な単精度浮動小数点形式(float32)モデルに対して、より効率的な8ビット整数(uint8)形式を使用しています。
デコーダTransformerモデルは、マージAttentionサブレイヤー(MAtt:Merged Attention sublayer)を用いて、デコーダの自己Attentionの計算の複雑さを2次関数的な増加から線形な増加に減らし、待ち時間を減らしています。デコードステップごとに、従来のTransformerデコーダーのキャッシュサイズが増加するのに比べ、MAttはデコーダーの自己Attentionに固定サイズのキャッシュを使用します。次の図は、エッジデバイス(携帯電話、タブレットなど)を使って出力トークンをオンデバイスで生成するために、ビームサーチモジュールがデコーダレイヤーとどのように相互作用するかを示しています。

クラウドサーバ上のデコーディングとオンデバイス(エッジデバイス実装)の比較
左:クラウドサーバー上のビームサーチは、float32で2次関数的に計算時間が増加する自己Attentionを持つTransformerベースのデコーダモデルを採用し、デコードステップごとにキャッシュサイズが増加します。
右:エッジデバイスの実装では、量子化ビームサーチモジュールと固定サイズのキャッシュ、線形に計算時間が増加する自己Attention計算を採用しています。
評価方法
ByteQRNNの開発後、civil_commentsデータセットでの性能を曲線下面積(AUC:Area Under the Curve)を指標として評価し、事前学習したByteQRNNやBERT(下図)と比較しました。微調整されたByteQRNNは、300倍小さいにもかかわらず、全体の品質を向上させ、その性能をBERTモデルに近づけていることを実証しています。
SeqFlowLiteモデルは、モデルサイズを1/4に縮小する学習中量子化(in-training quantization)をサポートしているため、結果として得られるモデルは低コンピュータデバイスによく適応します。
可能な限り最高の性能を達成するため、BERTモデルとバイトストリームモデルの両方をタスクに関連する多言語データソースを使用して事前学習させました。
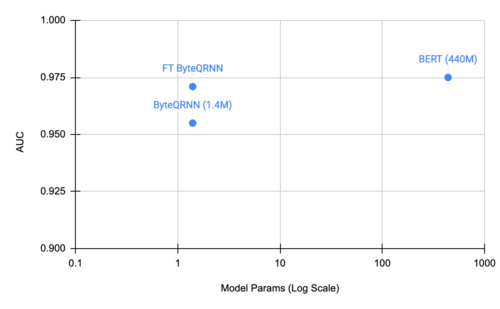
civil_commentsデータセットにおけるByteQRNNと微調整したByteQRNN、BERTの比較
まとめ
pQRNNを用いた前回の研究に続き、私達は、事前学習を可能にし、それによってオンデバイス展開のためのモデル性能を向上させるために、オンデバイス用のバイトストリームモデルを評価しました。事前学習あり/なしのByteQRNNの評価を行い、事前学習済みのByteQRNNの性能は、300倍小さいにもかかわらず、BERTと同等であることを実証しました。
ByteQRNNに加え、異なるエンコーダを使用するByteTransformerとByteFunnelTransformerの2つのモデル、および、マージしたAttention デコーダモデル、SeqFlowLiteライブラリを通して推論を実行するビームサーチドライバもリリースしています。これらのモデルが、研究者や製品開発者にとって、将来のオンデバイス展開のための貴重なリソースとなることを期待しています。
謝辞
モデルのオープンソース化と評価にご協力いただいたKhoa Trinh, Jeongwoo Ko, Peter Young and Yicheng Fanに感謝します。Prabhu Kaliamoorthiには、ブレインストーミングとアイデア出しを手伝ってもらいました。Vinh Tran、Jai Gupta、Yi Tayには、バイトストリームモデルの事前学習を手伝ってもらいました。Ruoxin Sang、Haoyu Zhang、Ce Zheng、Chuanhao Zhuge、Jieying Luoには、TPUのトレーニングに協力してもらいました。このプロジェクトを後援し、サポートと励ましをいただいたErik Vee、Ravi Kumar、Learn2Compressのリーダーシップに感謝します。最後に、この投稿で使用したアニメーションの図を提供してくれたTom Smallに感謝します。
3.ByteQRNN:BERTの1/300のサイズで同等性能なオンデバイスモデル(2/2)関連リンク
1)ai.googleblog.com
Efficient Sequence Modeling for On-Device ML
2)github.com
google-research / byt5
models/research/seq_flow_lite/models/

