
1.LocoProp:レイヤー毎に最適化を行いバックプロパゲーションを効率化(2/2)まとめ
・LocoProp はレイヤー単位に正則化、出力目標、損失関数を使用してネットワークを分解
・重み更新はシンプルなオプティマイザーを使用するが性能は複雑なオプティマイザーに迫る
・レイヤーごとの正則化、ターゲット、および損失関数を選択する柔軟性も備えている
2.LocoPropの性能
以下、ai.googleblog.comより「Enhancing Backpropagation via Local Loss Optimization」の意訳です。元記事は2022年7月29日、Ehsan AmidさんとRohan Anilさんによる投稿です。
アイキャッチ画像はlatent diffusionでプロンプトはLocoProp。
おそらく、あるレイヤーに対して考えられる最も単純な損失関数は、二乗損失(squared loss)です。二乗損失は損失関数として有効な選択ですが、LocoPropはレイヤーの活性化関数が非線形である可能性を考慮し、各レイヤーの活性化関数に合わせたレイヤー別損失を適用します。これにより、モデル予測にとってより重要な入力の領域を強調し、出力にあまり影響を与えない領域を軽視することができます。以下に、tanhとReLU活性化関数に合わせた損失の例を示します。
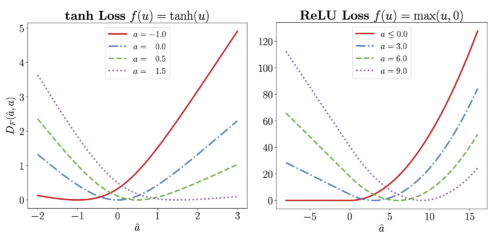
tanh(左)とReLU(右)活性化関数に起因する損失関数
それぞれの損失は、出力予測に影響を与える領域に対してより敏感です。例えば、予測値(â)と目標値(a)の両方が負である限り、ReLU損失はゼロです。これは、負の数に適用されるReLU関数が0に等しいためです。
LocoProp は各レイヤーで目的を形成した後、その目的に対して勾配降下ステップを繰り返し適用して、レイヤーの重みを更新します。この更新は通常、(RMSPropのような)一次オプティマイザーを用います。
しかし、私達は、組み合わせた更新の全体的な振る舞いが、高次の更新に酷似していることを示します。(以下に示します)。そのため、LocoPropは高次最適化器が達成する性能に近い学習性能を、行列逆行列演算のような高次手法に必要な多いメモリや計算量なしに提供することができます。
LocoPropはよく知られたアルゴリズムを復元し、損失、ターゲット、正則化の異なる選択により新しいアルゴリズムを構築することができる柔軟な枠組みであることを示します。また、LocoPropのニューラルネットワークのレイヤー別の考え方は、レイヤーを超えて並列に重みを更新することを可能にします。
実験内容
本論文では、最適化アルゴリズムの性能評価によく用いられるベースラインであるディープオートエンコーダモデルについての実験を説明します。SGD、SGD with momentum、AdaGrad、RMSProp、Adamといった一般的に用いられる複数の一次最適化器、および高次最適化器であるShampooとK-FACに対して大規模なチューニングを行い、LocoPropと比較しました。 その結果、シングルGPUで実行した場合、LocoProp法は一次最適化器よりも大幅に性能が高く、高次と同等であり、さらに著しく高速であることが示されました。
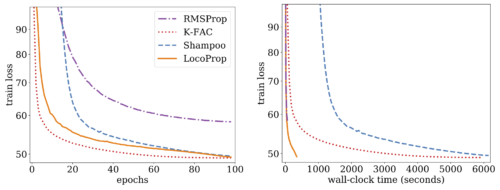
ディープ オートエンコーダー モデルの RMSProp、Shampoo、K-FAC、および LocoProp のトレーニング 損失とエポック数(左)および壁時計時間(つまり、トレーニング中に経過した現実の時間)(右)。
まとめと今後の方向性
ディープ ニューラル ネットワークをより効率的に最適化するために、LocoProp と呼ばれる新しい枠組みを導入しました。 LocoProp は、ニューラル ネットワークを独自の正則化器、出力目標、および損失関数を使用して個別のレイヤーに分解し、ローカル更新を並行して適用して、ローカル目標を最小化します。局所最適化問題に一次更新を使用していますが、結合された更新は、理論的にも経験的にも、高次更新によく似ています。
LocoProp は、レイヤーごとの正則化、ターゲット、および損失関数を選択する柔軟性を提供します。したがって、これらの選択に基づいて新しい更新ルールを開発できます。 LocoProp のコードは、GitHub でオンラインで入手できます。私たちは現在、LocoProp によって誘発されたアイデアをより大きなスケール モデルにスケールアップすることに取り組んでいます。乞うご期待!
謝辞
共著者である Manfred K. Warmuth の重要な貢献と刺激的なビジョンに感謝します。複合関数の観点からこの研究を考察する議論をしてくれた Sameer Agarwal、Shampoo の議論と開発を行ってくれた Vineet Gupta、K-FAC の Zachary Nado、このブログ投稿で使用されるアニメーションの開発を行った Tom Small、そして最後にGoogle Brain チームの育成研究環境を提供してくれたYonghui WuとZoubin Ghahramaniに感謝します。
3.LocoProp:レイヤー毎に最適化を行いバックプロパゲーションを効率化(2/2)関連リンク
1)ai.googleblog.com
Enhancing Backpropagation via Local Loss Optimization
2)proceedings.mlr.press
LocoProp: Enhancing BackProp via Local Loss Optimization
3)github.com
google-research/locoprop/

