
1.Plex:何をすればディープラーニングの信頼性を高める事が出来るのか?(1/2)まとめ
・機械学習は学習データから分離したテストデータに適用した場合に最も精度が高くなる
・しかし、現実世界で直面するデータが学習データと一致している事はほとんどない
・信頼性を高めるためには不確実性への対処、堅牢な汎化、新データへの適応能力が必要
2.Plexとは?
以下、ai.googleblog.comより「ai.googleblog.com」の意訳です。元記事は2022年7月14日、Dustin TranさんとBalaji Lakshminarayananさんによる投稿です。
アイキャッチ画像はlatent diffusionでプロンプトはPlex。短い単語でもロゴやポスター的な画像を生成してくれる傾向がありますね。
ディープラーニングモデルは、特に大規模な事前学習の台頭により、視覚、言語、その他のモダリティで目覚ましい進歩を遂げています。
このようなモデルは、トレーニングセットと同じ分布から抽出されたテストデータに適用した場合に最も精度が高くなります。しかし、実際にモデルが直面するデータは、学習分布と一致することはほとんどありません。また、予測が方程式の一部であるようなアプリケーションには適していないかもしれません。モデルの信頼性を高めるには、データ分布の変化に対応し、さまざまなシナリオで有用な判断を下すことができなければなりません。
論文「Plex: Towards Reliability Using Pre-trained Large Model Extensions」では、モデルの能力に関する新しい視点として、信頼性の高い深層学習のためのフレームワークを提示します。
これには、モデルの信頼性をストレステストするための具体的なタスクとデータセットが多数含まれています。また、多くの異なるアーキテクチャに適用可能な、事前学習済みの大規模モデル拡張のセットであるPlexを紹介します。
視覚と言語の領域におけるPlex(Pre-trained Large Model Extensions)の有効性を、現在最先端のVision TransformerとT5モデルにこれらの拡張機能を適用し、その信頼性を大幅に向上させることで実証しています。また、このアプローチのさらなる研究を促進するために、コードのオープンソース化も行っています。
不確実性(Uncertainty):犬と猫の分類器。Plexは猫でも犬でもない入力に対して「わからない」と言うことができます。
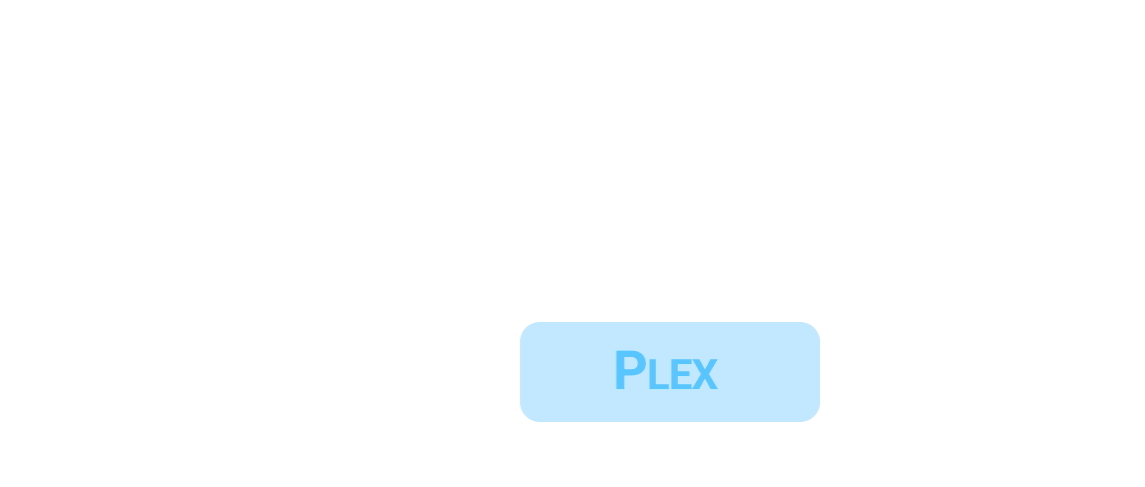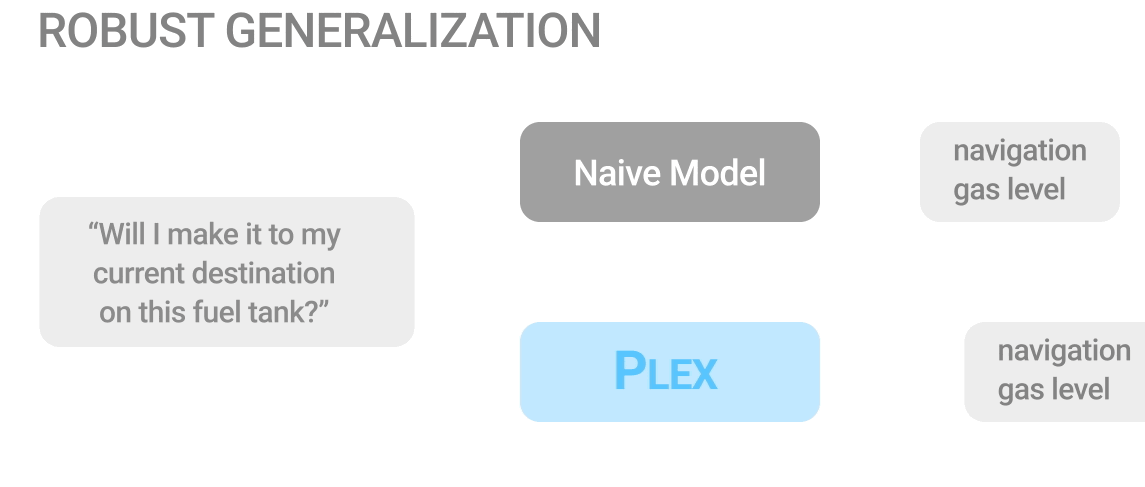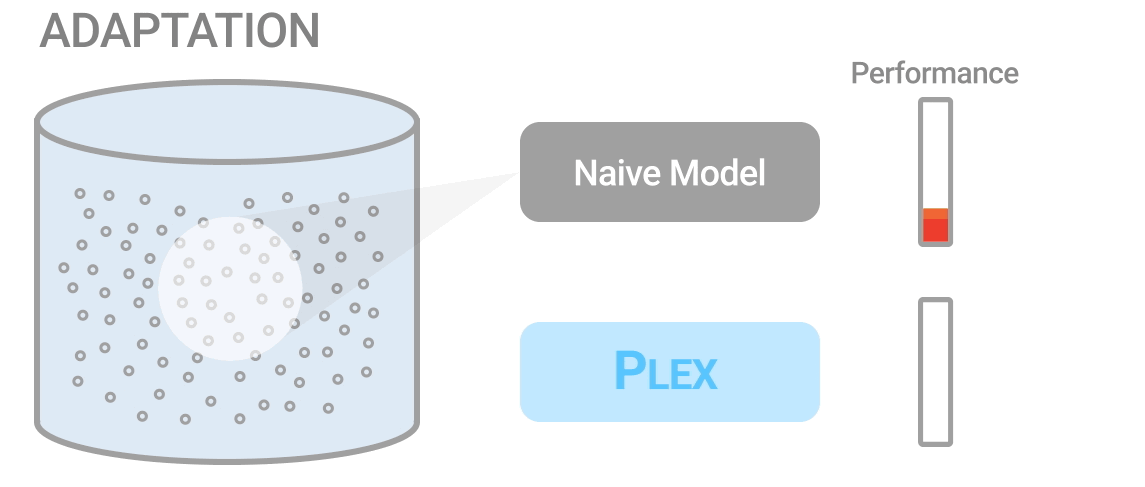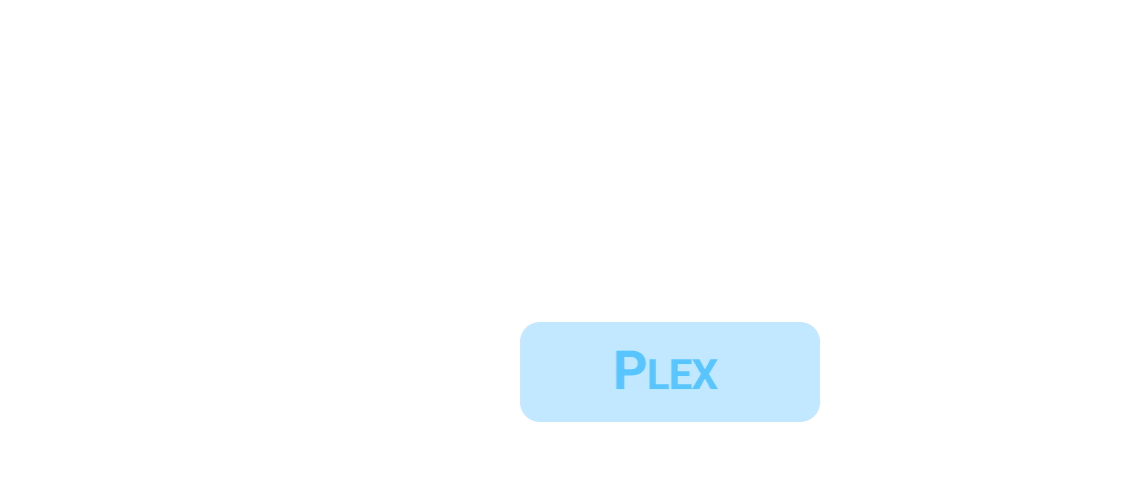
堅牢な汎化(Robust Generalization):ナイーブモデルは偽の相関関係(destination)に対して敏感ですが、Plexは堅牢です。
適応性(Adaptation):Plexはより早くパフォーマンスを向上させるために、学習するデータを積極的に選択することができます。
信頼性のためのフレームワーク
まず、新しいシナリオにおけるモデルの信頼性をどのように理解するかについて検討します。私達は、信頼性の高い機械学習(ML:Machine Learning)システムの要件として、3つの一般的なカテゴリを想定しています。
(1)予測値の不確実性を正確に報告すること(自分が何を知らないかを知る)
(2)新しいシナリオに堅牢に汎化すること(分布シフト)
(3)新しいデータに効率的に適応できること(適応)
です。
重要なことは、信頼できるモデルは、個々のタスクのためにカスタマイズすることなく、これらの領域すべてにおいて同時にうまく機能することを目指すべきであるということです。
・不確実性は、モデルが正確な予測を行うことを困難にする不完全な情報または未知の情報を反映します。予測不確実性の定量化は、モデルが最適な決定を計算することを可能にし、実務家がモデルの予測をいつ信頼すべきかを認識するのを助け、それによってモデルが間違っている可能性が高いときに率直に失敗することを可能にします。
・堅牢な汎化には、未知の事象についての推定や予測が必要です。私達は4種類の分布外データを調査します。:共変量シフト(出力分布は変化しないが訓練時入力と本番時入力で分布が変化する場合)、意味(またはクラスの)シフト、ラベルの不確実性、および下位母集団へのシフトです。
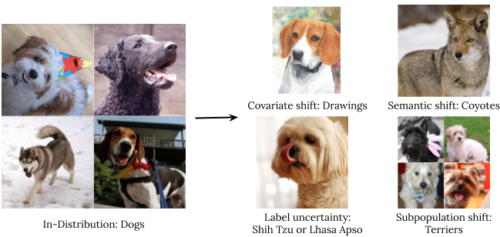
ImageNetの犬のイラストを使った分布シフトの種類の説明
・適応とは、学習過程におけるモデルの能力を調査することです。ベンチマークは通常、事前に定義された訓練セットとテストセットに分割した静的なデータセットで評価されます。しかし、多くのアプリケーションでは、新しいデータセットに素早く適応し、できるだけ少ないラベル付けされた例で効率的に学習できるモデルに関心があります。
信頼性フレームワーク
私達は、不確実性、堅牢な汎化、適応ベンチマークにまたがる「すぐに使える」モデル性能(すなわち予測分布)を、個々のタスクのためにカスタマイズすることなく、同時にストレステストすることを提案します。
不確実性、堅牢な汎化、適応の3つの信頼性領域を捉えるために10種類のタスクを適用し、各領域の望ましい特性の多様なセットを測定することを保証しています。
タスクは視覚と自然言語のモダリティを横断する40の下流データセットから構成されます。微調整用の14データセット(少数回学習や能動学習による適応を含む)と、分布外評価のための26データセットです。
3.Plex:何をすればディープラーニングの信頼性を高める事が出来るのか?(1/2)関連リンク
1)ai.googleblog.com
Towards Reliability in Deep Learning Systems
2)arxiv.org
Plex: Towards Reliability using Pretrained Large Model Extensions
3)goo.gle
plex-code

