
1.CMT-DeepLab:パノプティックセグメンテーションをクラスタ問題として考える(2/2)まとめ
・マスクtransformerをクラスタリングの観点から再定義すると性能と解釈可能性が大幅に向上
・kMaX-DeepLabは修正が簡単でテスト時間を増やさず追加データもなしでこれを達成
・視覚分野にtransformersアーキテクチャを導入する今後の研究の促進に繋がる事が期待される
2.kMaX-DeepLabとは?
以下、ai.googleblog.comより「Revisiting Mask Transformer from a Clustering Perspective」の意訳です。元記事は2022年7月12日、Qihang YuさんとLiang-Chieh Chenさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Tengyart on Unsplash
マスクtransformerのクロスAttentionをクラスタリングの観点から再定義することで、セグメンテーション性能が大幅に向上し、複雑なマスクtransformerのパイプラインをより解釈しやすいものに簡略化することができます。まず、エンコーダ・デコーダ構造で入力画像から画素の特徴を抽出します。次に、クラスタ中心のセットを用いて画素をグループ化し、さらにクラスタリングの割り当てに基づいて更新します。最後に、クラスタリングの割り当てと更新のステップが繰り返し実行され、最後の割り当てが直接セグメンテーションの予測として機能します。
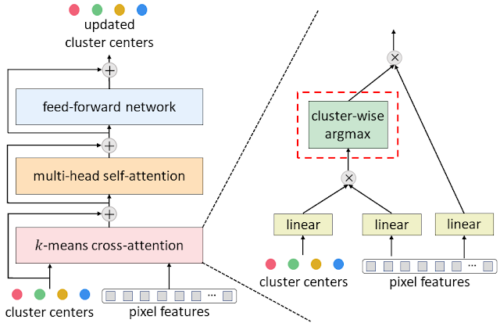
典型的なマスクtransformerデコーダー(クロスAttention、マルチヘッド自己Attention、フィードフォワードネットワークで構成)を私達の提案するk-meansクロスAttentionに変換するには、空間ワイズソフトマックスをクラスタワイズargmaxに置き換えるだけです。
私達が提案するkMaX-DeepLabのメタアーキテクチャは、画素エンコーダ、拡張画素デコーダ、kMaXデコーダの3つから構成されています。
画素エンコーダは、画像の特徴を抽出するために使用されるネットワークバックボーンでし。拡張画素デコーダは、画素の特徴を強化するためのtransformerエンコーダと、より高い解像度の特徴を生成するためのアップサンプリングレイヤーを含んでいます。一連のkMaXデコーダはクラスタ中心を(1)マスクembeddingベクトルに変換し、このベクトルと画素特徴を掛け合わせて予測マスクを生成し、(2)各マスクに対するクラス予測を行います。
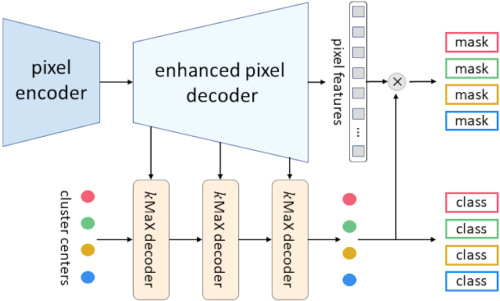
kMaX-DeepLabのメタ・アーキテクチャ
研究成果
CMT-DeepLabとkMaX-DeepLabを、パノプティック品質指標(PQ)を用いて、最も困難なパノプティックセグメンテーションデータセットであるCOCOとCityscapesの2つで、MaX-DeepLabや他の最新手法と比較評価しました。CMT-DeepLabは大幅な性能向上を達成し、kMaX-DeepLabは修正が簡単なだけでなく、テスト時間を増やさず外部データセットを使用せずに、COCO val setでPQ 58.0%、マスク平均精度(マスクAP)44.0% 、Cityscapes val setで平均交差過剰一致(mIoU) 83.5% という大きな差をつけてさらに最先端を押し上げることに成功しました。
| Method | PQ | APmask | mIoU |
| Panoptic-DeepLab | 63.0% (-5.4%) | 35.3% (-8.7%) | 80.5% (-3.0%) |
| Axial-DeepLab | 64.4% (-4.0%) | 36.7% (-7.3%) | 80.6% (-2.9%) |
| SWideRNet | 66.4% (-2.0%) | 40.1% (-3.9%) | 82.2% (-1.3%) |
| kMaX-DeepLab | 68.40% | 44.00% | 83.50% |
COCO val setでの比較
| Method | PQ |
| MaX-DeepLab | 51.1% (-6.9%) |
| MaskFormer | 52.7% (-5.3%) |
| K-Net | 54.6% (-3.4%) |
| CMT-DeepLab | 55.3% (-2.7%) |
| kMaX-DeepLab | 58.00% |
Cityscapes val setでの比較
クラスタリングの観点から設計されたkMaX-DeepLabは、性能が高いだけでなく、Attentionマップの動作メカニズムを理解するために、より妥当な視覚化を行っています。下の例では、kMaX-DeepLabがクラスタリングの割り当てと更新を繰り返し行い、徐々にマスクの品質を高めています。
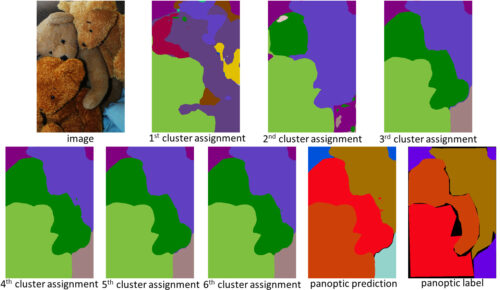
kMaX-DeepLabのAttentionマップは、パノプティックセグメンテーションとして直接視覚化することができ、モデルの動作メカニズムに説得力を与えます。(画像提供:coco_url、ライセンス取得済)
結論
私達は、視覚タスクのためのマスクtransformersをより良く設計する方法を示しました。CMT-DeepLabとkMaX-DeepLabは、簡単な修正により、クロスAttentionをよりクラスタリングアルゴリズムに近い形で再定式化することができます。その結果、提案モデルは、難易度の高いCOCOおよびCityscapesデータセットにおいて、最先端の性能を達成することができました。DeepLab2ライブラリにおけるkMaX-DeepLabのオープンソース公開により、視覚に特化したtransformersアーキテクチャの設計に関する今後の研究の促進が期待されます。
謝辞
Huiyu Wang, Dahun Kim, Siyuan Qiao, Maxwell Collins, Yukun Zhu, Florian Schroff, Hartwig Adam, そして Alan Yuilleからの貴重な議論と支援に感謝します。
3.CMT-DeepLab:パノプティックセグメンテーションをクラスタ問題として考える(2/2)関連リンク
1)ai.googleblog.com
Revisiting Mask Transformer from a Clustering Perspective
2)arxiv.org
CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation
k-means Mask Transformer
3)github.com
google-research / deeplab2

