
1.MLGO:強化学習を使ってコンパイラの最適化処理を最適化(2/2)まとめ
・MLGOを使用してレジスタ割当問題も大規模データセンターのQPSで0.3%~1.5%改善できた
・QPSは導入後数ヶ月間持続しており時間経過に伴って性能が劣化しない汎化性がある
・今後、より良いRLアルゴリズムの適用や他の最適化経験則への適用などが見込まれる
2.MLGOの性能
以下、ai.googleblog.comより「MLGO: A Machine Learning Framework for Compiler Optimization」の意訳です。元記事は2022年7月6日、Yundi QianさんとMircea Trofinさんによる投稿です。
アイキャッチ画像はlatent diffusionによる自動生成
MLGOのinlining-for-sizeトレーニングは、バイナリサイズが重要な、ハードウェアとソフトウェアの多様なエコシステムを動かすために設計された汎用オープンソースOS、Fuchsiaに展開されました。ここでは、MLGOはC++翻訳ユニットに対して6.3%のサイズ削減を示しました。
レジスタ割り当て(性能向上のための)
汎用的なフレームワークとして、私達はMLGOを使用して、LLVMのコード性能を向上させるレジスタ割当パスを改善しました。レジスタ割当は、物理レジスタをライブレンジ(すなわち変数)に割り当てるという問題を解決します。
コードが実行されると、異なるライブレンジが異なるタイミングで完了し、後続の処理ステージで使用するためのレジスタが解放されます。以下の例では、「加算」と「乗算」の各命令で、すべての演算子と結果が物理レジスタにあることが必要です。ライブレンジxは、緑色のレジスタに割り当てられ、青色または黄色のレジスタのライブレンジのいずれよりも前に完了します。xが完了した後、緑色のレジスタが使用可能になり、ライブレンジtに割り当てられます。
レジスタ割り当て例
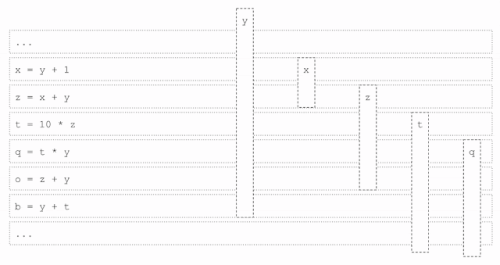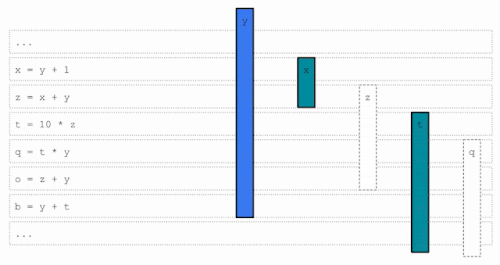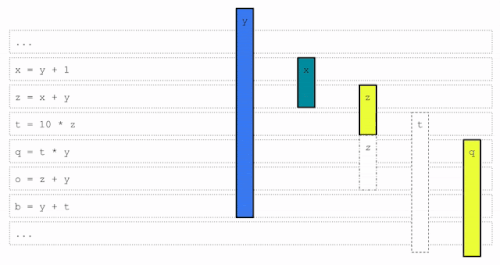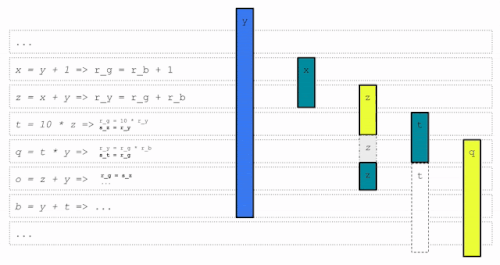
ライブレンジqを割り当てるとき、利用可能なレジスタがないので、レジスタ割り当てパスはq用にスペースを作るために、どの(もしあれば)ライブレンジをそのレジスタから「退避」させるかを決定しなければなりません。
これは「ライブレンジ退避(live range eviction)」問題と呼ばれ、オリジナルの経験則に代わるモデルを訓練するための意思決定問題となります。この特定の例では、黄色のレジスタからzを退去させ、qとzの前半に割り当てます。
今度はライブレンジzの未割り当ての後半を考えてみましょう。再び競合が発生し、今度はライブレンジtが退避・分割され、tの前半とzの最終部分が緑のレジスタを使用することになります。
zの中間部分はq = t * yという命令に対応し、zは使われていないので、どのレジスタにも代入されず、その値は黄色のレジスタからスタックに格納され、後で緑のレジスタにリロードされます。tについても同様です。
これはコードに余分なロード/ストア命令を追加し、パフォーマンスを低下させます。レジスタ割り当てアルゴリズムの目標は、このような非効率性を可能な限り減らすことです。これは、RLポリシーの学習を導く報酬として使用されます。
inlining-for-sizeポリシーと同様に、レジスタ割り当て(regalloc-for-performance)ポリシーは、Google内部の大規模なソフトウェアパッケージで学習され、異なるソフトウェア間で一般化可能であり、内部の大規模データセンターアプリケーションのセットでクエリー/秒(QPS)が0.3%~1.5%改善されました。QPSの向上は、導入後数ヶ月間持続しており、このモデルの時間軸における汎化性を示しています。
まとめと今後の課題
私達は、産業用コンパイラLLVMにML技術を体系的に統合するためのフレームワークであるMLGOを提案します。MLGOは、
(1)より深く、例えば、より多くの機能を追加し、より良いRLアルゴリズムを適用する
(2)より広く、例えば、インライン化やレジスタ割当以外の最適化経験則に適用する
といった拡張が可能な汎用的なフレームワークです。MLGOがコンパイラ最適化分野にもたらす可能性に期待し、そのさらなる普及と研究コミュニティからの今後の貢献に期待します。
自分で試してみましょう
オープンソースで直接データを収集・学習するソリューションと、ポリシー勾配を用いたinlining-for-sizeポリシーの学習デモをgithubでご覧ください。
謝辞
MLGOの貢献者、協力者であるEugene Brevdo, Jacob Hegna, Gaurav Jain, David Li, Zinan Lin, Kshiteej Mahajan, Jack Morris, Girish Mururu, Jin Xin Ng, Robert Ormandi, Easwaran Raman, Ondrej Sykora, Maruf Zaber, Weiye Zhaoに感謝いたします。また、私たちを信頼し、MLGOの最初の顧客としてFuchsiaにMLGOを導入してくれたPetr Hosek, Yuqian Li, Roland McGrath, Haowei Wu for、、Google内部の大規模データセンターアプリケーションへの導入を支援してくれた David Blaikie, Eric Christopher, Brooks Moses, Jordan Rupprecht、リーダーシップをとってサポートしてくれた Ed ChiとTipp Moseleyに感謝します。
3.MLGO:強化学習を使ってコンパイラの最適化処理を最適化(2/2)関連リンク
1)ai.googleblog.com
MLGO: A Machine Learning Framework for Compiler Optimization
2)arxiv.org
MLGO: a Machine Learning Guided Compiler Optimizations Framework
3)github.com
google / ml-compiler-opt

