
1.DALL-E 2がセンシティブな画像を生成しないようにするための工夫(1/3)まとめ
・DALL-E 2は強力な画像生成モデルだがOpenAIのポリシーに違反しない工夫をしている
・工夫の一部にDALL-E 2の学習データを直接変更する事前学習の緩和策がある
・この措置により暴力的な画像や性的な画像、偏見、記憶の問題を低減する事ができている
2.DALL-E 2の学習データのクレンジング
以下、openai.comより「DALL·E 2 Pre-Training Mitigations」の意訳です。元記事は2022年6月28日、Alex Nicholさんによる投稿です。
生成系のAIって画像でも文章でも、人間から見ると学習用データとの違いがわからない、ほぼそのままコピーしたかのような出力をしてしまう事があります。GitHub Copilotなどはまさに今、完全に同じコードを出力したら学習用に使ったコードのライセンス違反になるのではないかという懸念が指摘されている状況ですが、DALL-E 2は学習用データに手を加える事でこういった事象を低減しているとの事で参考になる記事でした。
アイキャッチ画像のクレジットはPhoto by Dan Meyers on Unsplash
DALL-E 2の魅力を多くの人と共有するために、強力な画像生成モデルに関連するリスクを軽減する必要がありました。そのため、生成された画像が私たちのコンテンツポリシーに違反しないよう、さまざまなガードレールを設置しました。
この記事では、ガードレールの一部である「事前学習の緩和策(pre-training mitigations)」に焦点を当てます。事前学習の緩和策ではDALL-E 2の学習データを直接変更します。
特に、DALL-E 2はインターネット上の何億もの説明文付き画像で学習しますが、これらの画像の一部を削除して重みを変更することで、モデルの学習内容を変更します。
本投稿は3つの章から構成されており、それぞれが異なる事前トレーニングの緩和策について説明しています。
第1章では、DALL-E 2のトレーニングデータセットから暴力的な画像や性的な画像をどのように除外したかを説明しています。このフィルタリングを行わないと、写実的で露骨な画像を要求されたときに、その画像を生成するように学習してしまい、一見無害に見えるプロンプトに対しても、意図せずにそのような画像を返してしまう可能性があります。
第2章では、私達は学習データにフィルタをかけるとバイアスが増幅されることを発見しており、この影響を緩和するための手法について述べます。例えば、フィルタリングされたデータを用いて学習したモデルは、元のデータセットを用いて学習したモデルと比べて、男性を描いた画像が多く、女性を描いた画像が少なく生成されることがあることが分かりました。
最後の章では、記憶の問題(issue of memorization)に目を向けます。DALL-E 2のようなモデルが、新規に画像を作成するのではなく、訓練時の画像を再現することがあることを発見しました。実際には、この画像の再生産は、データセット内で何度も複製されている画像が原因であることがわかり、データセット内の他の画像と視覚的に類似している画像を削除することで問題を軽減しています。
写実的で露骨な学習データの削減
学習データは学習したモデルの能力を形成するため、データフィルタリングは望ましくないモデルの能力を制限するための強力なツールです。
私たちはこのアプローチを、「暴力的な画像」と「性的な画像」という2つのカテゴリに適用しました。このカテゴリに属する画像を、DALL-E 2の学習前に分類器を使ってデータセットから除外するのです。これらの画像分類器は社内で学習し、データセットのフィルタリングが学習したモデルに与える影響について継続的に研究しています。
画像分類器の学習には、以前GLIDEの学習データのフィルタリングに用いた手法を再利用しました。このアプローチの基本的な手順は以下の通りです。
(1)ラベル付けしたい画像カテゴリの仕様を作成
(2)各カテゴリについて数百のポジティブな例とネガティブな例を収集
(3)能動学習(active learning)によりデータを収集し、適合率(precision)と再現率(recall)率のトレードオフを改善
(4)得られた分類器をデータセット全体に対して実行。このとき、適合率(ポジティブと予測されたデータのうち、本当にポジティブであるものの割合)より再現率(本当にポジティブであるもののうち、ポジティブであると予測されたものの割合)を優先するため、保守的な分類の閾値を設定
これらの閾値を設定するために、私たちは良いデータを残すことよりも悪いデータをすべてフィルタリングすることを優先させました。これは、モデルは後でいつでもより多くのデータで微調整して新しいことを教えることができますが、既に学習したことを忘れさせることははるかに難しいからです。
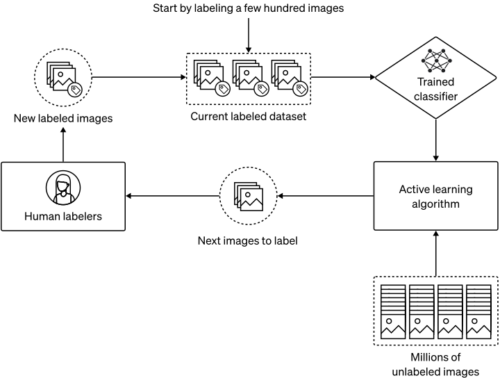
まず、ラベル付けされた画像からなる小さなデータセット(図の上部)を用意します。そして、このデータに対して分類器を学習させます。次に、能動学習プロセスで、現在の分類器を用いて、分類器の性能を向上させる可能性のあるラベルの付いていない画像をいくつか選択します。最後に、人間がこれらの画像に対してラベルを作成し、ラベル付きデータセットに追加します。このプロセスを繰り返すことで、分類器の性能を反復的に向上させることができます。
能動学習の段階では、分類が困難な画像や誤判定した画像に対して人間がラベルを付与し、繰り返し分類器を改善しました。
特に、何億枚ものラベルの付いていない画像を含むデータセットから、人間がラベルを付けるべき画像を選択するために、2つの能動学習技術を用いました。
まず、分類器の誤検出率(良性の画像を暴力的または性的と誤判定する頻度)を下げるため、現在のモデルが陽性と判定した画像に人間がラベルを割り当てました。
このステップをうまく機能させるために、誤検知が多くなっても再現率がほぼ100%になるように分類しきい値を調整しました。
こうすることで、ラベル付け作業者が本当に悪性なケースにラベルを付けることがほとんどになりました。この方法は、誤検知を減らし、ラベル付け作業者が有害と思われる画像を探す必要性を減らすのに役立ちますが、モデルが現在見逃しているより多くの陽性ケースを見つけるのには役立ちません。
分類器の偽陰性率、すなわち検知漏れを下げるために、2つ目の能動学習技法である最近傍探索を採用しました。特に、現在のラベル付きデータセットから、モデルが誤って問題なしと分類する傾向のある問題のあるサンプルを見つけるために、何度も交差検証を行いました。(このために、文字通り、異なる訓練-検証分割を行った何百ものバージョンの分類器を訓練しました。)
次に、ラベルの付いていない大量の画像をスキャンして、知覚的特徴空間におけるこれらのサンプルの最近傍を探し、発見された画像に人間のラベルを割り当てました。私達の計算機基盤のおかげで、分類器の学習と最近傍探索の両方を多くのGPUにスケールアップすることは容易であり、能動学習ステップを数時間や数日ではなく、数分で行うことができます。
データフィルタの有効性を検証するために、同じハイパーパラメータで2つのGLIDEモデルを学習させました。1つはフィルタリングされていないデータで、もう1つはフィルタリングされたデータセットで学習させたものです。前者をフィルタリングなしモデル、後者をフィルタリング後モデルと呼ぶことにします。
予想通り、フィルタリングモデルは、この種のコンテンツの要求に対して、一般に、より少ない露骨なまたはグラフィックコンテンツを生成することがわかりました。しかし、データ・フィルタリングの予想外の副作用も見つかりました。
モデルの出力が特定の人口動態に偏ったり、その偏りが増幅されたりしたのです。


フィルタリングされていないモデル(左)とフィルタリングされたモデル(右)のプロンプト「反戦抗議」に対する生成画像。注目すべきは、フィルタリングモデルでは、銃の画像がほとんど生成されないことです。
3.DALL-E 2がセンシティブな画像を生成しないようにするための工夫(1/3)関連リンク
1)openai.com
DALL·E 2 Pre-Training Mitigations

