
1.LIMoE:画像と文章に対応可能で規模拡大が容易なスパースMoEモデル(2/2)まとめ
・多様な情報を処理可能なマルチモーダルモデルは将来が有望視されているが密モデルでは困難
・疎モデルは規模拡大の容易性と情報同士を組み合わせて性能を向上する能力に優れる
・個別タスクに特化する専門性と広範囲のタスクに対応する柔軟性を備えた汎用モデルに近づく
2.LIMoEの性能
以下、ai.googleblog.comより「LIMoE: Learning Multiple Modalities with One Sparse Mixture-of-Experts Model」の意訳です。元記事は2022年6月9日、Basil MustafaさんとCarlos Riquelmeさんによる投稿です。
アイキャッチ画像はDALL·E FLOW
LIMoEによる対照学習
マルチモーダル対照学習では、画像とテキストのペアデータ(例えば、写真とその写真を説明する文章)を用いてモデルを学習します。
一般に、画像モデルは画像の特徴表現を抽出し、テキストモデルはテキストの特徴表現を抽出します。対照学習の目的は、画像とテキストの特徴表現が、同じ画像とテキストのペアでは近く、異なるペアのコンテンツでは遠くなるように促すものです。
このように特徴表現を揃えたモデルは、追加の学習データなしに新しい課題に適応できます。(ゼロショットと言います)
例えば、ある画像が、その特徴表現が「猫」という単語よりも「犬」という単語の特徴表現に近ければ、犬として分類されることになります。この考え方を、何千ものクラスに規模拡大したものが、ゼロショット画像分類と呼ばれます。
CLIPとALIGN(両方とも2タワーモデル)はこの手法の規模を拡大し、人気のあるImageNetデータセットにおいて76.2%と76.4%のゼロショット分類精度を達成しました。
私達は、画像とテキスト特徴表現の両方を計算する1タワーモデルについて研究しています。その結果、負の干渉やモデルの容量不足が原因で、高密度モデルでは性能が低下することがわかりました。しかし、計算量を一致させたLIMoEは1タワーの密なモデルだけでなく、2タワーの密なモデルも上回りました。
私達はCLIPと同等の学習体制で一連のモデルを訓練しました。L/16の高密度モデルが73.5%のゼロショット精度を達成したのに対し、LIMoE-L/16は78.6%となり、CLIPの高価な2タワーL/14モデル(76.2%)をも凌駕しています。このように、LIMoEはスパース性を利用することで、同等のコストを持つ高密度モデルに対して、顕著な性能向上を実現しています。
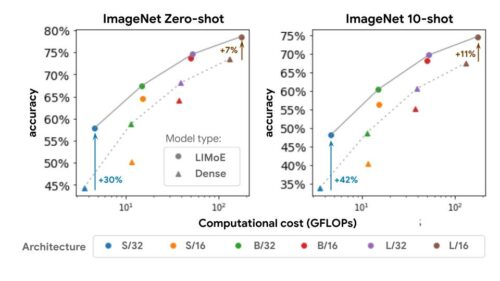
ある計算コスト(x軸)に対して、LIMoE モデル(丸、実線)は密な比較対象モデル(三角、破線)より大幅に優れています。アーキテクチャは、左(S/32)から右(L/16)に向かって、基礎となるtransformerのサイズを示しています。標準的な慣習に従って、S(小)、B(ベース)、L(大)はモデルの規模を意味します。数字は入力として与えるデータ断片(パッチ)の大きさを表し、パッチの大きさが小さい事はアーキテクチャが大きいことを意味します。
LiTとBASICは、密な 2タワーモデルのゼロショット精度をそれぞれ 84.5%、85.6%に押し上げました。これらのアプローチでは、規模拡大に加えて、特別な事前学習方法を用いて、すでに非常に高い品質を持つ画像モデルを再利用しています。
LIMoE-H/14は、事前学習やモダリティに特化した部品から恩恵を受けていませんが、それでもゼロからのトレーニングで同等の84.1%のゼロショット精度を達成しました。
これらのモデルの規模を比較することも興味深いことです。LiTとBASICは21億と30億のパラメータモデルです。LIMoE-H/14は合計56億のパラメータを持ちますが、スパース性により、トークンあたり6.75億のパラメータを適用するだけなので、より軽量になります。
| Data seen during training | |||||
| Model | Pre-training | Image-text | Total | Parameters per token | ImageNet accuracy |
| CLIP | – | 12.8B | 12.8B | ~200M | 0.762 |
| ALIGN | – | 19.8B | 19.8B | ~410M | 0.764 |
| LiT | 25.8B | 18.2B | 44.0B | 1.1B | 0.845 |
| BASIC | 19.7B | 32.8B | 52.5B | 1.5B | 0.856 |
| LIMoE H/14 | – | 23.3B | 23.3B | 675M | 0.841 |
LIMoE の挙動を理解する
LIMoEは、疎な条件計算(Sparse conditional computation)により、汎用のマルチモーダルモデルでありながら、各モダリティを理解するのに必要な専門性を身につけることができるという直感に基づき、開発されました。私達はLIMoEのExperts層を分析し、いくつかの興味深い現象を発見しました。
まず、モダリティに特化したExpertsが出現していることがわかります。私たちの学習環境では、テキストよりも画像の方が多いため、すべてのExpertsが少なくとも画像を処理する傾向がありますが、Expertsによっては、ほとんど画像、ほとんどテキスト、あるいはその両方を処理する人もいます。
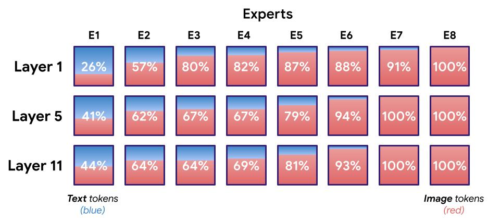
LIMoEの8Expertsの分布
パーセントはExpertsが処理した画像トークンの量を示します。明らかにテキストに特化したExpertsが1~2名(ほとんどが青色のExpertsで示されています)、通常2~4名の画像Experts(ほとんどが赤色)、残りはその中間に位置しています。
また、画像Expertsには、明確な質的パターンが存在します。
例えば、ほとんどのLIMoEモデルでは、テキストを含んでいる画像全てを処理するExpertsが存在します。下の例では、あるExpertsは動植物や緑を処理し、別のExpertsは人の手を処理しています。

LIMoEは各トークンに対してExpertsを選択します。ここでは、LIMoE-H/14の1つのレイヤーにおいて、どの画像トークンがどのExpertsに行くかを示しています。意図して学習させたわけではないにもかかわらず、植物や車輪など特定の意味を持つトピックに特化したExpertsが出現していることがわかります。
前へ進む
多くのタスクを処理するマルチモーダルモデルは、将来性のある方法であり、成功のための2つの重要な要素を持ちます。
規模拡大の容易性と、相乗効果を利用しながら異なるタスクやモダリティ間の干渉を回避する能力です。
疎な条件計算(Sparse conditional computation)は、その両方を実現する優れた方法です。LIMoEが少ない計算量で優れた性能を発揮していることからもわかるように、個々のタスクに特化するための能力と柔軟性を備えた、性能と効率の良いジェネラリストモデルを実現することができるのです。
謝辞
この研究の共著者であるJoan Puigcerver、 Rodolphe Jenatton、Neil Houlsbyに感謝します。
また、Andreas Steiner、Xiao Wang、Xiaohua Zhaiには、対照的マルチモーダル学習のための高密度シングルタワーモデルに関する初期の研究をリードし、データアクセスを提供してくれたことに感謝します。
また、André Susano Pinto, Maxim Neumann, Barret Zoph, Liam Fedus, Wei Han, Daniel Keysers, Josip Djolongaとも有益な議論を楽しみました。
最後に、この投稿で使用した素晴らしいアニメーション図を提供してくれたTom Smallにも感謝し、謝意を表したいと思います。
3.LIMoE:画像と文章に対応可能で規模拡大が容易なスパースMoEモデル(2/2)関連リンク
1)ai.googleblog.com
LIMoE: Learning Multiple Modalities with One Sparse Mixture-of-Experts Model
2)arxiv.org
Multimodal Contrastive Learning with LIMoE: the Language-Image Mixture of Experts

