
1.Googleアシスタントが文脈を意識できる理由(2/2)まとめ
・言い換えシステムは3種の異なるタイプの生成器を用いて候補を生成している
・言い換え候補からいくつかの信号を抽出しMLモデルで最も有望な候補を選択
・本手法は、問い合わせ文を処理機構に依存しないため後処理に影響を与えない
2.言い換え候補の作成方法
以下、ai.googleblog.comより「Contextual Rephrasing in Google Assistant」の意訳です。元記事は2022年5月17日、Aurelien BoffyさんとRoberto Pieracciniさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Taha on Unsplash
システム構成
言い換えシステムは、高レベルでは、異なるタイプの候補生成器を用いて言い換え候補を生成します。そして、それぞれの言い換え候補をいくつかの信号に基づいて得点化し、最も高い得点のものを選択します。
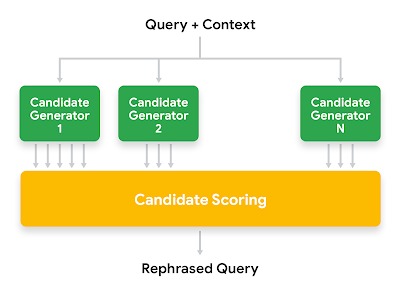
Googleアシスタントの文脈を意識した言い換え候補生成器の高レベルデザイン図
候補の生成
言い換え候補の生成には、さまざまな技術を適用したハイブリッドアプローチを使用しており、これらは3つのカテゴリーに分類されます。
(1)問い合わせ文の言語構造の分析に基づく生成では、文法規則や形態規則を使って特定の操作を行います。たとえば、代名詞や他の参照語句を文脈から先行詞に置き換えます。
(2)問い合わせ文の統計に基づく生成は、現在の問い合わせ文とその文脈のキーワードを組み合わせて、過去のデータや一般的な問い合わせ文パターンから人気のある問い合わせ文に一致する候補を生成します。
(3)MUM(Multitask Unified Model、2019年のBERT導入に続く、2021年から徐々にGoogle検索に取りこまれているより複雑な検索に対応するモデル。75の異なる言語と多くの異なるタスクで同時にトレーニングされ、テキスト以外にも画像情報も扱えるため、直接の答えが見つからない検索でも他言語や画像などから得た答えを示す事が出来るようになるという)のようなTransformer技術に基づく生成器は、多数の学習サンプルに従って単語の並びを生成するように学習します。
LaserTaggerやFELIXは、入力テキストと出力テキストの重複が多いタスクに適した技術であり、推論時間が非常に速く、幻覚(入力テキストと関係のないテキストを生成してしまう事)に対して脆弱でありません。
問い合わせ文とその文脈が提示されると、文脈のどの部分を保存し、どの単語を修正すべきかを示すことにより、入力クエリを言い換え候補に変換するための一連のテキスト編集を生成することが可能です。
候補のスコアリング
各言い換え候補からいくつかの信号を抽出し、MLモデルを使って最も有望な候補を選択します。いくつかの信号は現在の問い合わせ文とその文脈にのみ依存します。
例えば「現在の問い合わせ文のトピックは以前の問い合わせ文のトピックと類似しているか?」あるいは「現在の問い合わせ文は単体の問い合わせ文として優れているか、それとも不完全に見えるのか?」などです。
その他の信号は、候補自身に依存します。「候補は文脈情報をどの程度保持しているか?」「候補は言語学的に正しく形成されているか?」などです。
最近、BERTとMUMモデルによって生成された新しい信号がランキングシステムの性能を著しく向上させ、文脈に基づかない(従って言い換えを必要としない)問い合わせ文の誤検出を最小限に抑えながら、再現性の伸びしろを約3分の1修正することに成功しました。

Google アシスタントが一連の文脈的なクエリを理解しているスマートフォンでの会話例
まとめ
ここで説明した解決策は、文脈に依存する問い合わせ文を、他の情報を参照せずに完全に回答できるように言い換えることで、文脈に依存する問い合わせ文を解決しようとするものです。このアプローチの利点は、問い合わせ文を処理するメカニズムに依存しないため、さらなる後処理を行う前に展開する水平レイヤーとして使用できることです。
人間の言語には様々な文脈が存在するため、私達は言語規則、過去の記録から得た大量の履歴データ、および最新のTransformerアプローチに基づくMLモデルを組み合わせたハイブリッドアプローチを採用しました。
各問い合わせ文とその文脈に対して多数の言い換え候補を生成し、さまざまな信号を使用してそれらをスコアリングおよびランク付けすることにより、Googleアシスタントはほとんどの文脈を持つ問い合わせ文を言い換えることができ、したがって正しく解釈することができます。
アシスタントが、ほとんどの種類の言語的な参照を扱うことができるため、ユーザーがより自然な会話をすることができるようになります。
このような複数回にわたる会話の煩わしさを軽減するために、アシスタントのユーザーは「継続会話」モードをオンにすることで、それぞれの問い合わせの間に「Hey Google」と繰り返すことなく、次の問い合わせをすることができます。私たちは、この技術を他のバーチャルアシスタントにも応用し、例えば、画面に表示されたものやスピーカーから流れる音から文脈を解釈するような使い方も考えています。
謝辞
本記事は、Aliaksei Severyn, André Farias, Cheng-Chun Lee, Florian Thöle, Gabriel Carvajal, Gyorgy Gyepesi, Julien Cretin, Liana Marinescu, Martin Bölle, Patrick Siegler, Sebastian Krause, Victor Ähdel, Victoria Fossum, Vincent Zhaoによる共同作業から引用しています。また、Amar Subramanya、Dave Orr、Yury Pinskyには、有益な議論と支援をいただきました。
3.Googleアシスタントが文脈を意識できる理由(2/2)関連リンク
1)ai.googleblog.com
Contextual Rephrasing in Google Assistant

