
1.FELIX:タグ付けと挿入を使う効率的で柔軟なテキスト編集モデル(1/2)まとめ
・seq2seqは自然言語生成タスクで好まれるが単一言語が対象の際は最適でない可能性
・自己回帰で低速であり単一言語では入力が出力にコピーされるだけの事が多く無駄
・テキスト編集モデルが注目を集めているが速度と柔軟性のトレードオフが存在
2.テキスト編集モデルとは?
以下、ai.googleblog.comより「Introducing FELIX: Flexible Text Editing Through Tagging and Insertion」の意訳です。元記事の投稿は2021年5月5日、Jonathan MallinsonさんとAliaksei Severynさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Nicolas Savignat on Unsplash
Sequence-to-sequence(seq2seq)モデルは、自然言語生成タスクに取り組む際に好まれるアプローチとなっています。機械翻訳(machine translation)から、文章の要約(summarization)、文の融合(sentence fusion)、テキストの簡略化text simplification()、機械翻訳実行後の推敲(machine translation post-editing)などの単一言語生成タスクに至るまで、様々なアプリケーションで使用できます。
ただし、これらのモデルは、多くの単一言語を対象とするタスクにとって最適ではないように思われます。これは、目的の出力テキストが入力テキストをわずかに書き直しするだけで表現出来る事が多いためです。このようなタスクを実行する場合、seq2seqモデルは、一度に1ワードずつ出力を生成するため(つまり、自己回帰するため)遅くなり、ほとんどの入力トークンが出力にコピーされるだけなので無駄になります。
代わりに、テキスト編集モデル(text-editing models)は、編集操作(edit operations、単語の削除、挿入、置換など)を予測することを提案しているため、最近注目を集めています。これらの編集操作は、出力を再構築するために入力に適用されます。
ただし、従来のテキスト編集アプローチには制限がありました。これらは、
・高速(非自己回帰)だが、使用する編集操作の数が限られているため柔軟性がない
・柔軟性があり、可能なすべての編集操作をサポートしているが、低速(自己回帰)
のいずれかであり、どちらの場合も、能動態「彼らは夕食にステーキを食べた(They ate steak for dinner.)」から受動態「ステーキが夕食に食べられた(Steak was eaten for dinner.)」に変換する事など、大規模な構造的(構文的)変換をモデル化する事には重点を置いていません。
代わりに、それらは局所的な変換に焦点を合わせ、短いフレーズを削除または置換しています。大規模な構造変換を行う必要がある場合、それらは生成できないか、大量の新しいテキストを挿入することができず、時間がかかります。
論文「FELIX: Flexible Text Editing Through Tagging and Insertion」では、FELIXを紹介します。これは、大きな構造変化をモデル化し、seq2seqアプローチと比較して90倍の高速化を実現すると同時に、4つの単一言語生成タスクで印象的な結果を達成する高速で柔軟なテキスト編集システムです。従来のseq2seqメソッドと比較して、FELIXには次の3つの重要な利点があります。
(1)サンプル効率:高精度のテキスト生成モデルをトレーニングするには、通常、大量の高品質の教師ありデータが必要です。FELIXは、3つの手法を使用して、必要なデータの量を最小限に抑えます。
1)事前にトレーニングされたチェックポイントを微調整する
2)少数の編集操作を学習するタグ付けモデル。
3)事前トレーニングタスクと非常によく似たテキスト挿入タスク
(2)速い推論時間:FELIXは完全に非自己回帰であり、自己回帰デコーダーによって引き起こされる遅い推論時間を回避します。
(3)柔軟なテキスト編集:FELIXは、学習した編集操作の複雑さと、モデル化する変換の柔軟性のバランスを取ります。
つまり、FELIXは、自己教師型の事前トレーニングから最大のメリットを引き出すように設計されており、利用可能なトレーニングデータがほとんどない、リソースの少ない状況で効率的です。
FELIXの概要
上記を実現するために、FELIXはテキスト編集タスクを2つのサブタスクに分解します。1つは「入力データの部分集合」と「それらの出力テキスト内の出現位置」を決定するタグ付けタスク、もう1つは入力データ内の一部を隠して、そこにあるべき単語を挿入させる挿入タスクです。
タグ付けモデルは、構造変換をサポートする新しいポインターメカニズムを採用していますが、挿入モデルはマスク言語モデルに基づいています。
これらのモデルは両方とも非自己回帰であり、モデルが高速であることを保証します。FELIXの概要図を以下に示します。
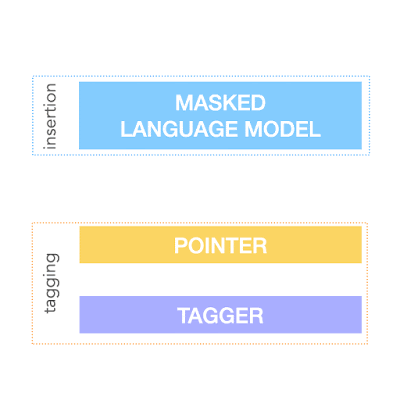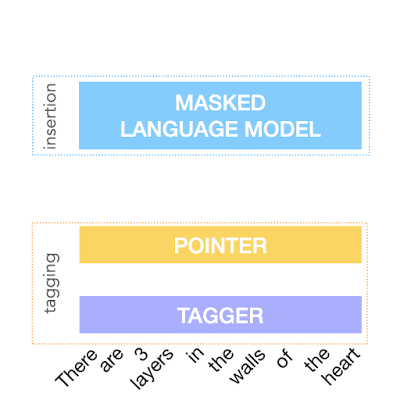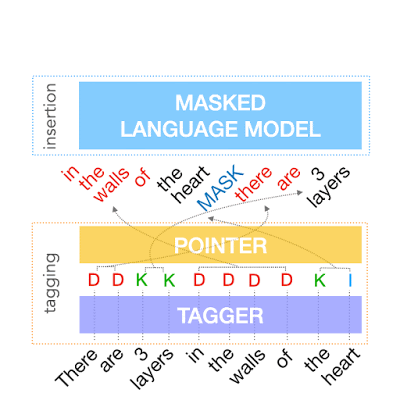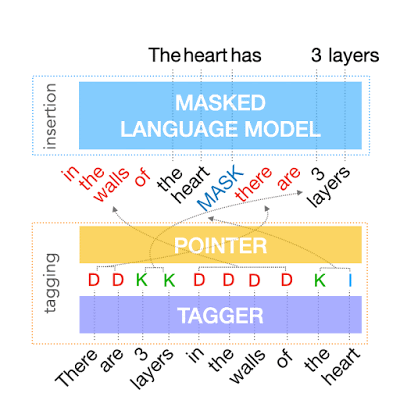
テキスト簡略化タスクのデータでトレーニングされたFELIXの例。 入力ワードは、最初に「保持(KEEP(K))」、「削除(DELETE(D))」、または「保持と挿入(KEEP and INSERT(I))」としてタグ付けされます。タグ付け後、入力は並べ替えられます。この並べ替えられた入力は、マスク言語モデルに送られます。
3.FELIX:タグ付けと挿入を使う効率的で柔軟なテキスト編集モデル(1/2)関連リンク
1)ai.googleblog.com
Introducing FELIX: Flexible Text Editing Through Tagging and Insertion
2)www.aclweb.org
FELIX: Flexible Text Editing Through Tagging and Insertion
3)github.com
google-research/felix/

