
1.GraphWorld:グラフニューラルネットワーク用データセットを自動生成(2/2)まとめ
・GraphWorldは標準的なデータセットがカバーする領域を超える範囲のデータを生成
・グラフが学術的なベンチマークセットと異なるとGNNモデルの性能が変化する
・古典的データセットの同類性は高いため性能が出るが同類性が低いと性能が変る
2.GraphWorldで判明した事
以下、ai.googleblog.comより「GraphWorld: Advances in Graph Benchmarking」の意訳です。元記事は2022年5月4日、John PalowitchさんとAnton Tsitsulinさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by engin akyurt on Unsplash
GraphWorldで扱う確率的ブロックモデル(SBM:Stochastic Block Model)のパラメータの一つは、クラスタの「同類性(homophily)」です。これは、同じクラスタ内の二つのノードが(異なるクラスタ内の二つのノードと比較して)接続されやすくなる可能性を制御するものです。
同類性とは、同じ事に興味を持つユーザー(例えば、SBMクラスタ)がつながりやすいという、ソーシャルネットワークでは一般的な現象です。
しかし、すべてのソーシャルネットワークが同じレベルの同類性を持っているわけではありません。GraphWorldは、SBMを利用して、同類性の高いグラフ(下図左)、同類性の低いグラフ(下図右)、およびその中間の任意のレベルの同類性のグラフを数百万個生成することができます。
これにより、他の研究者が作成した実データセットの有無に依存することなく、あらゆるレベルの同類性のグラフに対するGNNの性能を分析することができます。
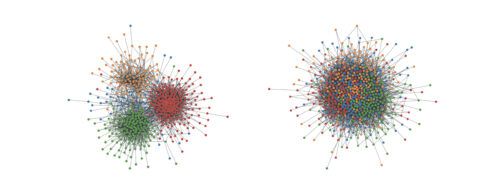
GraphWorldで確率的ブロックモデルを用いて作成したグラフの例
左のグラフは、ノードクラス間の同類性が高く(異なる色で表現)、右のグラフは同類性が低いです。
GraphWorldの実験と洞察
タスクとそのタスク用のパラメータ化された生成器が与えられると、GraphWorldは並列計算(例:Google Cloud Platform Dataflow)を使って、生成器のパラメータ値をサンプリングしてGNNベンチマークデータセットの世界を生成します。
同時に、GraphWorldは任意のGNNモデル(GCN、GAT、GraphSAGEなど、ユーザが選択)のリストを各データセット上でテストし、グラフの特性とGNN性能結果を結びつけた巨大な表形式のデータセットを出力します。
本論文では、ノード分類、リンク予測、グラフ分類の各タスクについて、それぞれ異なるデータセット生成器を用いたGraphWorldのパイプラインを紹介します。各パイプラインは、OGBグラフを用いた最先端の実験よりも短い時間と計算資源で実行できることが分かりました。これは、GraphWorldが低予算の研究者にとって利用しやすいことを意味しています。
以下のアニメーションは、GraphWorldを用いたノード分類パイプライン(データセット生成器としてSBMを使用)によるGNNパフォーマンスデータを可視化したものです。
GraphWorldの影響を説明するために、まず古典的な学術グラフデータセットを、各グラフ内のクラスタの同類性とノードの度数の平均を測定するx-y平面にマッピングします。これは、OGBデータセットを含む上の散布図と同様ですが、測定値が異なります。
次に、GraphWorldの各シミュレーショングラフデータセットを同じ平面にマッピングし、各データセットに対するGNNモデルの性能を測定する3番目のz軸を追加します。
具体的には、ある特定のGNNモデルについて、z軸は私達の論文で評価した他の13のGNNモデルに対するモデルの平均逆順位(MRR:Mean Reciprocal Rank)を測定します。MRRは1に近い値であれば、そのモデルはノードの分類精度の点で最高性能に近いことを意味します。
このアニメーションは、2つの関連した結論を示しています。まず、GraphWorldは、標準的なデータセットがカバーする領域をはるかに超える範囲のグラフデータセット領域を生成します。
第二に、最も重要なことは、グラフが学術的なベンチマークグラフと異なる場合、GNNモデルの順位が変化することです。
具体的には、CoraやCiteSeerのような古典的データセットの同類性は高く、ノードはクラスに応じてグラフ内でよく分離していることを意味します。私達は、GNNが同類性の低いグラフ空間に向かうにつれて、その順位が急速に変化することを見出しました。
例えば、GCNの平均逆順位の比較は、学術ベンチマーク領域で高い値(緑)から、その領域から離れると低い値(赤)へと移動します。これは、GraphWorldが、学術的ベンチマークが提供するほんの一握りの個別データセットだけでは見えない、GNNアーキテクチャ開発における重要な空きスペースを明らかにする可能性を持っていることを示しています。

3種類のGNN(GCN, APPNP, FiLM)を50,000のノード分類データセットで性能測定した相対的比較結果。学術的なGNNベンチマークデータセットは、モデルの順位が変化しないGraphWorld領域に存在することがわかりました。GraphWorldは、GNNアーキテクチャに関する新しい洞察を明らかにする、これまで未開拓だったグラフを発見することができます。
まとめ
GraphWorldは、グラフデータセットの高次元表面で新しいモデルを大規模にテストすることを可能にし、GNN実験に新しい境地を開きました。
これにより、CoraのようなグラフやOGBのような、GraphWorldのデータセットでは個々の点としてしか現れないグラフの部分空間全体に対して、グラフの性質に対するGNNアーキテクチャのきめ細かな分析が可能になります。
GraphWorldの主な特徴は低コストであることで、組織のリソースを利用できない個人の研究者が、新しいモデルの経験的性能を迅速に理解することを可能にします。
GraphWorldを利用することで、より高度なGNN実験を行うために、新しいランダム/生成グラフモデルを調査することも可能です。また、GNNの事前学習にGraphWorldのデータセットを利用できる可能性があります。
私達は、GraphWorldのオープンソースリポジトリとフォローアッププロジェクトによって、これらの研究を支援することを楽しみにしています。
謝辞
GraphWorldはGoogle ResearchのBrandon MayerとBryan Perozziとの共同研究です。本投稿内の画像についてはTom Smallに感謝します。
3.GraphWorld:グラフニューラルネットワーク用データセットを自動生成(2/2)関連リンク
1)ai.googleblog.com
GraphWorld: Advances in Graph Benchmarking
2)arxiv.org
GraphWorld: Fake Graphs Bring Real Insights for GNNs
3)github.com
google-research / graphworld

