
1.Alpa:わずか1行でJAXニューラルネットワークを並列化(2/2)まとめ
・Alpaは標準的な専門家が設計したTransformerモデルでは最高のフレームワークに匹敵する
・mixture-of-expert層を持つTransformerモデルでは主導設計を最大で8倍上回る
・Alpaは手動計画のないWide-ResNetのようなモデルにも一般化でき、性能を向上させる
2.Alpaの性能
以下、ai.googleblog.comより「Alpa: Automated Model-Parallel Deep Learning」の意訳です。元記事は2022年5月3日、Zhuohan LiさんとYu Emma Wangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Sergio Capuzzimati on Unsplash
演算内パス
従来の研究(Mesh-TensorFlowやGSPMDなど)と同様、演算内並列ではデバイスメッシュ上でテンソルを分割します。これは、Transformerモデルの典型的な3Dテンソルについて、batch、sequence、hiddenの各次元を指定したもので、下図のように示されます。batch次元はデバイスメッシュ0次元(mesh0)に沿って、hidden次元はメッシュ1次元(mesh1)に沿って、sequence次元は各プロセッサ内に複製されて分割されます。
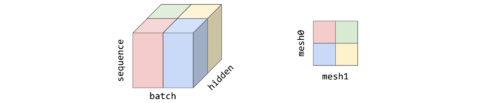
2次元のデバイスメッシュ上に分割された3次元テンソル
Alpaのテンソルの分割を利用して、さらに計算グラフの個々の演算に対する並列化戦略を定義します。以下に行列の乗算の並列化戦略の例を示します。
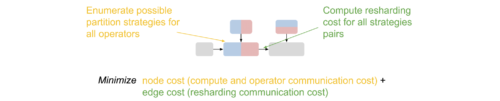
演算に対する並列化戦略を定義すると、1つのテンソルがある演算の出力と別の演算の入力になることがあるため、テンソルの分割が競合する可能性があります。この場合、2つの演算間で再分割が必要となり、通信コストが追加されます。

行列乗算の並列化戦略
各演算のパーティションと再パーティションコストが与えられると、演算内パスは整数計画問題(ILP:Integer-Linear Programming)として定式化されます。各演算に対して、パーティション戦略を列挙するためのワンショット変数ベクトルを定義します。ILPの目的は、計算コストと通信コストの合計(ノードコスト)と再分割通信コスト(エッジコスト)を最小化することです。
ILPの解は、元の計算グラフを分割する特定の分割に変換されます。
演算間パス
演算間パスでは、演算グラフとデバイスクラスタをスライスして、パイプライン並列化を行います。下図のように、ボックスはマイクロバッチ入力を表し、パイプラインステージはサブグラフを実行するサブメッシュを表します。
水平方向は時間を表し、マイクロバッチが実行されるパイプラインステージを示します。演算間パスの目標は、下図に示すように、デバイス上でのワークロード実行全体の合計である実行待ち時間を最小化することです。Alpaは、ダイナミック・プログラミング(DP:Dynamic Programming)アルゴリズムを使用して、総遅延速度を最小化します。計算グラフはまず平坦化され、次に演算間パスに送られます。ここでは、デバイスクラスタをサブメッシュに分割した場合のすべての可能なパフォーマンスがプロファイリングされます。
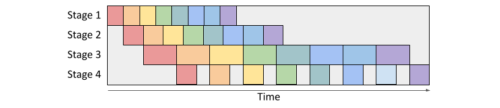
パイプラインの並列
ある時刻に、分割されたデバイスクラスタとスライスされた計算グラフ(ステージ1、2、3など)が処理しているマイクロバッチ(色のついたボックス)を示しています。
実行時制御
演算間および演算内の並列化戦略が完了すると、ランタイムは各デバイスのサブメッシュに対して静的な実行命令列を生成し、発送します。これらの命令には、特定のサブグラフのRUN、他のメッシュからのテンソルのSEND/RECEIVE、またはメモリを解放するための特定のテンソルのDELETEが含まれます。デバイスはこの指示に従うことで、他と連携せずに計算グラフを実行することができます。
評価方法
16GBのV100 GPUを8個搭載したAWS p3.16xlargeインスタンス8台、合計64GPUでAlpaをテストしました。GPUの数を増やしながらモデルサイズを大きくしていった場合に規模拡大時の性能の弱まり方を検証しました。
(1)標準的なTransformerモデル(GPT)
(2)mixture-of-expert層を持つTransformerであるGShard-MoEモデル
(3)従来の専門家が設計したモデル並列化戦略を持たない、大きく異なるモデルであるWide-ResNet
の3つを評価します。
性能は、クラスタ上で達成された1秒あたりの浮動小数点演算(PFLOPS)で測定されます。
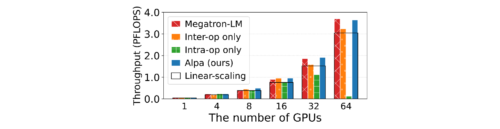
GPTの図
Alpaは、専門家が設計した最高のフレームワークであるMegatron-MLの性能に匹敵します。
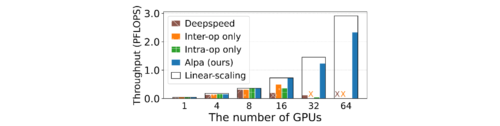
GShard MoEの図
Alpaは、Deepspeed(GPU上でエキスパートが設計した最高のフレームワーク)を最大8倍も上回る性能を発揮します。
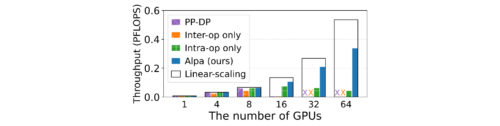
Wide-ResNetの図
Alpaは手動計画のないモデルにも一般化できます。パイプライン・データ並列(PP-DP)は、パイプラインとデータ並列のみを使用し、その他の演算内並列を使用しないベースラインモデルです。
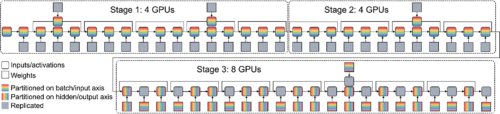
Wide-ResNetの16GPUでの並列化戦略は、3つのパイプラインステージで構成されており、専門家でも設計が複雑な戦略となっています。ステージ1と2は4GPUでデータ並列を行い、ステージ3は8GPUで演算子並列を行います。
まとめ
分散並列深層学習モデルのための効果的な並列化計画を設計するプロセスは、歴史的に困難で手間のかかる作業でした。Alpaは、モデル並列分散学習を自動化するために、演算内および演算間の並列性を活用する新しいフレームワークです。私たちは、Alpaが分散型モデル並列学習を民主化し、大規模な深層学習モデルの開発を加速させると信じています。オープンソースコードの探索とAlpaの詳細については、私達の論文を参照してください。
謝辞
この研究に協力してくれたAWS、カリフォルニア大学バークレー校、上海交通大学、デューク大学、カーネギーメロン大学の同僚に感謝します。本論文の共著者に感謝します。Lianmin Zheng, Hao Zhang, Yonghao Zhuang, Yida Wang, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, そしてIon Stoicaの各氏に感謝します。
Lianmin (UC Berkeley & AWS) は演算内パス、Zhuohan (UC Berkeley & Google) は演算間パス、Hao (UC Berkeley) は実行時自動制御パスの取り組みをリードしています。
このプロジェクトは、LianminとZhuohanがそれぞれAWSとGoogleから提供されたインターンシップの機会なしには実現できませんでした。また、Shibo Wang, Jinliang Wei, Yanping Huang, Yuanzhong Xu, Zhifeng Chen, Claire Cui, Naveen Kumar, Yash Katariya, Laurent El Shafey, Qiao Zhang, Yonghui Wu, Marcello Maggioni, Mingyao Yang, Michael Isard, Skye Wanderman-Milne そして David Majnemer に本研究に対する彼らの共同作業に謝辞を述べたいと思います。
3.Alpa:わずか1行でJAXニューラルネットワークを並列化(2/2)関連リンク
1)ai.googleblog.com
Alpa: Automated Model-Parallel Deep Learning
2)arxiv.org
Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning
3)github.com
alpa-projects / alpa

