
1.VFS:強化学習で長期目線が必要な行動を実現(1/2)まとめ
・強化学習の進歩によりロボットは複雑なタスクを実行できるようになった
・しかし、可能なのは短期目線タスクで長期目線が必要なタスクは困難
・VFSで長期目線を持たせると状態と行動の抽象化を学習可能になる
2.VFSとは?
以下、ai.googleblog.comより「Extracting Skill-Centric State Abstractions from Value Functions」の意訳です。元記事は2022年4月29日、Dhruv ShahさんとBrian Ichterさんによる投稿です。
アフォーダンス(affordance)の概念が久しぶりに出てきたので、何だったっけ?と思った方は以下を読んでおくことを推奨です。
視覚タスクで学習した重みをロボット操作タスクに転移学習する試み(1/3)
long horizonsを意識したアイキャッチ画像のクレジットはPhoto by 張 峻嘉 on Unsplash
ロボット工学のための強化学習(RL:Reinforcement Learning)の進歩により、ロボット・エージェントは、困難な環境においてますます複雑なタスクを実行することができるようになりました。最近の成果では、ロボットが服をたたむこと、ルービックキューブを器用に操作すること、物体を色で分類すること、複雑な環境を案内すること、困難な不整地を歩行することを学習できることが示されています。
しかし、これらのような「短期目線(short-horizon)」タスクは、長期的な計画をほとんど必要とせず、失敗のフィードバックがすぐに得られるため、実世界でロボットが直面する多くのタスクに比べて、比較的簡単に訓練することができます。しかし、このような短期目線のスキルを、抽象的で長期目線(long horizons)の実世界のタスクに拡張することは困難です。
例えば、物を拾って部屋の配置を変えることができるロボットはどのように訓練すればよいでしょうか?
階層型強化学習(HRL:Hierarchical Reinforcement Learning)はこの問題を解決するための一般的な手法で、様々な長期目線のRLタスクにおいて一定の成功を収めてきました。HRLは、低レベルスキルを階層的に積み重ねて行動を抽象化する手段を提供し、このような問題を解決することを目的としています。
しかし、高レベルの計画問題は、状態と行動の両方を抽象化することで、さらに単純化することができます。
例えば、ロボットが机の上の物を操作する卓上再配置タスクを考えてみましょう。
近年のRL、模倣学習、教師なしスキル発見などの進歩により、引き出しを開閉する、物を取る、置くなどの原始的な操作スキルのセットを得ることが可能です。しかし、ブロックを引き出しに入れるという単純なタスクでさえ、これらのスキルを連鎖させることは容易ではありません。
これは、
(i)長期目線の計画と推論に関する課題
(ii)風景の意味とアフォーダンスを解析しながら高次元の観察を扱うこと
の組み合わせに起因していると思われます。
つまり、いつ、どこで、どのようなスキルが使用できるのか、ということです。
ICLR 2022で発表された「Value Function Spaces: Skill-Centric State Abstractions for Long-Horizon Reasoning」では、長期目線に適した状態と行動の抽象化を学習する課題に取り組んでいます。
私達は、HRLにおける高レベルポリシーのための最小限の、しかし完全な特徴表現は「利用可能なスキルの性能」に依存する必要があると仮定しています。
私達は、スキルの価値関数(skill value functions)を用いてそのような特徴表現を得るための簡単なメカニズムを提示し、そのようなアプローチがモデルベースとモデルフリーRLの両方において長期目線の性能を向上させ、より良いゼロショット汎化を可能にすることを示します。
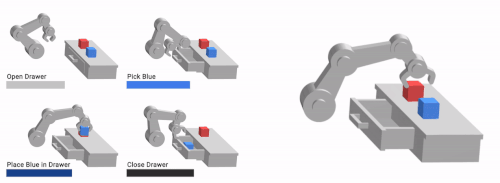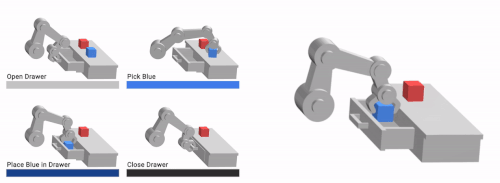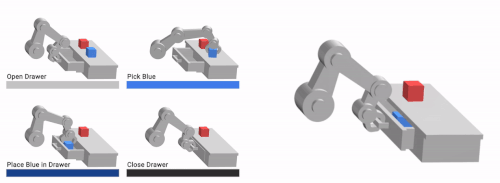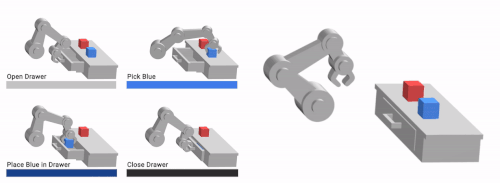
私達の手法であるVFSは、低レベルな基本要素(左)を組み合わせて、複雑な長期目線の行動(右)を学習することができます。
価値関数空間の構築
本研究の動機となる重要な洞察は、「行動と状態の抽象的な特徴表現」が、学習されたポリシーの価値関数を通じて容易に利用可能であるということです。
RLにおける「価値」の概念は、アフォーダンスと本質的に結びついています。つまり、そのスキルをうまく実行したときに報酬を受け取る確率が「状態の価値」を反映しています。
どのようなスキルであっても、その価値関数には2つの重要な性質があります
(1)そのスキルがいつどこで使えるかという使用場面の前提条件とアフォーダンス
(2)そのスキルを使ったときにうまく実行できたかどうかという結果
です。
このように、疎な結果報酬で学習された有限個のスキル集合とそれに対応する価値関数からなる決定過程がある場合、これらのスキルの価値関数を積み重ねることでembedding空間を構築します。
これにより、ある状態をk次元の特徴表現に対応させる抽象的な特徴表現が得られ、これを私達は価値関数空間(VFS:Value Function Space)と呼んでいます。この特徴表現は、エージェントの環境との相互作用の網羅的な集合に関する機能情報(functional information)を捕捉し、下流タスクに適した状態の抽象化です。
3.VFS:強化学習で長期目線が必要な行動を実現(1/2)関連リンク
1)ai.googleblog.com
Extracting Skill-Centric State Abstractions from Value Functions
2)arxiv.org
Value Function Spaces: Skill-Centric State Abstractions for Long-Horizon Reasoning

