
1.Pix2Seq:言語モデルを使って物体検出を行う(1/2)まとめ
・物体検出タスクを行う従来のアプローチは高度にカスタマイズされており汎用性がない
・物体検出タスクを画素を入力とする言語モデリングタスクとみなすPix2Seqを考案
・Pix2Seqは物体検出タスクで既存手法と比較して競争力のある結果を達成できた
2.Pix2Seqとは?
以下、ai.googleblog.comより「Pix2Seq: A New Language Interface for Object Detection」の意訳です。元記事は2022年4月22日、Ting ChenさんとDavid Fleetさんによる投稿です。
言語モデルを使って他領域のタスクを行う試みは有望な研究分野になってきましたね。それと、本論文はヒントン先生が関わっているようでした。
アイキャッチ画像のクレジットはPhoto by Clem Onojeghuo on Unsplash
物体検出(Object detection)は、画像内のすべての関心のある物体を認識し、位置を特定することを試みる、長年にわたるコンピュータビジョンの課題です。
範囲の重複を避けながら、すべての物体の識別または位置特定をしようとすると、複雑さが生じます。Faster R-CNNやDETRのような既存のアプローチは、慎重に設計され、アーキテクチャや損失関数の選択において高度にカスタマイズされています。
このような既存システムの専門化は、2つの大きな障壁を生み出しています。
(1)システムの異なる部分(例えば、領域提案ネットワーク(region proposal network)、GIOU損失によるグラフマッチングなど)のチューニングとトレーニングが複雑になる
(2)モデルの汎化能力が低下し、他のタスクに適用するためにモデルの再設計が必要になる
事などです。
ICLR 2022で発表された論文「Pix2Seq: A Language Modeling Framework for Object Detection」では、全く異なる観点から物体検出に取り組む、シンプルで汎用的な方法を紹介します。
タスクに特化した従来のアプローチとは異なり、私達は物体検出を「観測された画素入力を条件とする言語モデリングタスク」として投げかけます。
私達は、Pix2Seqが大規模オブジェクト検出COCOデータセットにおいて、既存の高度に専門的で最適化された検出アルゴリズムと比較して競争力のある結果を達成し、さらに大規模オブジェクト検出データセットでモデルを事前学習することによってその性能を向上できることを実証します。
また、この方向でのさらなる研究を奨励するため、Pix2Seqのコードと事前学習済みモデルを操作可能なデモとともに、より広い研究コミュニティに公開することをうれしく思います。
Pix2Seqの概要
私達ちのアプローチは、ニューラルネットワークが画像内の物体がどこにあり、何があるのかを知っているのであれば、それを読み取る方法を教えるだけでよいという直感に基づいています。
物体の「説明の仕方(describe)」を学習することで、モデルは画素観測に基づく説明を学習し、有用な物体特徴表現に導くことができます。
Pix2Seqモデルは画像が与えられると、一連の物体の説明を出力します。各物体は5つの離散トークンを用いて記述されます。境界ボックスボックスの四隅の座標[ymin, xmin, ymax, xmax]とクラスラベルです。

物体検出用のPix2Seqフレームワーク
ニューラルネットワークは画像を認識し、各物体に対して、境界ボックスとクラスラベルに対応する一連のトークンを生成します。
Pix2Seqでは、「境界ボックスとクラスラベル」を離散的なトークン列に変換する量子化・直列化スキームを提案し、(言語モデルがキャプションを扱うのと同様に)エンコーダ・デコーダアーキテクチャを利用して画素入力を認識し、物体説明のシーケンスを生成します。
学習目的関数( training objective function)は、画素入力と先行するトークンを条件とするトークンの最大尤度です。
物体の説明からシーケンスを構築
一般に用いられる物体検出のデータセットでは、画像には様々な数の物体があり、それらは境界ボックスとクラスラベルの集合として表現されます。
Pix2Seqでは、境界ボックスとクラスラベルで定義される1つの物体は、[ymin, xmin, ymax, xmax, class]と表現されます。
しかし、一般的な言語モデルは離散的なトークン(または整数)を処理するように設計されており、連続的な数を理解することはできません。
そこで、画像の座標を連続数として表現するのではなく、0から1の間で正規化し、数百または数千の離散ビン(discrete bins)のいずれかに量子化します。
これにより、座標は物体の説明と同様に離散的なトークンに変換され、画像のキャプションと同様に、言語モデルによって解釈されるようになります。量子化処理は、正規化された座標(例えばymin)にビン数マイナス1を掛け、最も近い整数に丸めることで実現されます。(詳細な処理は論文で確認できます)
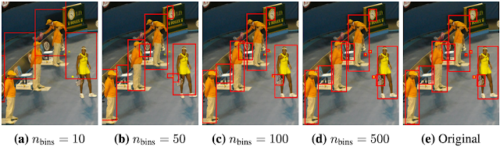
480 x 640の画像に対して、ビン数を変えて境界ボックスの座標を量子化
500ビンといった少ないビン/トークンで、小さな物体でも高い精度を実現します。
3.Pix2Seq:言語モデルを使って物体検出を行う(1/2)関連リンク
1)ai.googleblog.com
Pix2Seq: A New Language Interface for Object Detection
2)arxiv.org
Pix2seq: A Language Modeling Framework for Object Detection
3)github.com
google-research / pix2seq
4)colab.research.google.com
Pix2Seq Inference (Object Detection).ipynb

