
1.JSRL:事前ポリシーを効率的に使用して強化学習をジャンプスタート(1/2)まとめ
・強化学習は試行錯誤でタスクを実行するがゼロからポリシーを学習する事は難しい
・例えば複雑でゴールにどれだけ近づいているかを測定できないようなタスクの解決は困難
・JSRLは任意のポリシーで任意の種類のRLアルゴリズムを効率的に初期化するメタアルゴリズム
2.JSRLとは?
以下、ai.googleblog.comより「Efficiently Initializing Reinforcement Learning With Prior Policies」の意訳です。元記事は2022年4月6日、Ikechukwu UchenduさんとTed Xiaoさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Erik Dungan on Unsplash
強化学習(RL:Reinforcement Learning)は、試行錯誤によってタスクを実行するポリシーを学習することができますが、RLの大きな課題は、探索が困難な環境においてゼロからポリシーを学習することです。
例えば、DAPGプロジェクトのadroit manipulation suiteに含まれるdoor-binary-v0環境が前提にしている設定を考えてみましょう。RLエージェントは3D空間で手を制御し、目の前に置かれたドアを開けなければなりません。

RLエージェントは、3次元空間上で手を操作して、目の前に置かれたドアを開けなければなりません。エージェントが報酬を受け取るのは、ドアが完全に開いたときだけです。
エージェントには中間報酬が用意されていないので、タスクの完了にどれだけ近づいているかを測定することができず、最終的にドアを開けるまでランダムに空間を探索しなければなりません。このタスクの所要時間と必要となる精密な制御を考えると、このような設定はあまり成功しそうにありません。
このようなタスクの場合、事前情報(prior information)を利用することで、ランダムに状態空間を探索することを避けることができます。この事前情報は、エージェントが環境のどの状態が良好で、さらに探索する必要があるかを理解するのに役立ちます。
オフラインデータ(人間の実演者、スクリプト化されたポリシー、他のRLエージェントなどにタスクを実行させる事によって収集された静的データ)を使ってポリシーを学習し、それを使って新しいRLポリシーを初期化することができます。
このようにニューラルネットでポリシーを表現する場合、事前に学習させたポリシーのニューラルネットを新しいRLのポリシーにコピーする事ができます。
この手順により、新しいRLポリシーは事前学習されたポリシーと同じように動作するようになります。しかし、このように新しいRLポリシーを素朴(naïvely)に初期化すると、特に以下に示すように、価値ベースのRL手法(value-based RL methods)ではうまくいかないことが多いです。
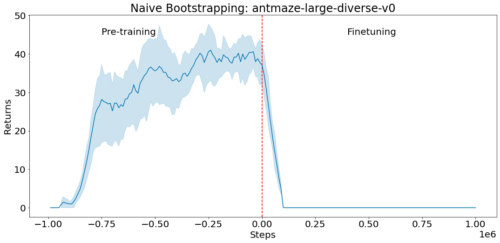
D4RL環境antmaze-large-diverse-v0においてオフラインデータで事前学習させます(負のステップが事前学習に相当します)そして、この事前学習されたポリシーを初期アクターとして、actor-criticの微調整を初期化します(ステップ0から始まるの正のステップ)
criticはランダムに初期化されます。このとき、actorのスコアはすぐに低下し回復しません。これは、未訓練のcriticが貧弱な学習シグナルを与え、良好な初期方針を忘れさせてしまうためです。
そこで、論文「Jump-Start Reinforcement Learning(JSRL)」 では、既存の任意の形式のポリシーを用いて、任意の種類のRLアルゴリズムを初期化できるメタアルゴリズムを紹介します。
JSRLは2つのポリシーを使ってタスクを学習します。
ガイドポリシー(guide-policy)と探索ポリシー(exploration-policy)です。
ガイドポリシーはオンライン学習中に更新されない任意の形式の既存のポリシーです。探索ポリシーはエージェントが環境から収集した新しい経験によってオンラインで学習されるRLポリシーです。
本研究では、ガイドポリシーがデモから学習されるシナリオに焦点を当てますが、他の多くの種類のガイドポリシーを使用することができます。JSRLは、ガイドポリシーと、それに続く自己改善型探索ポリシーによって学習カリキュラムを作成し、競合するIL+RL手法と比較し、性能を向上させることができます。
JSRLのアプローチ
ガイドポリシーは、台本化されたポリシー、RLで学習されたポリシー、あるいは生きた人間のデモなど、どのような形でも問題ありません。ガイドポリシー要件は、合理的であること(ランダム探索より優れていること)と、環境の観察に基づいて行動を選択できることだけです。
理想的なのは、ガイドポリシーがその環境において貧弱か中程度の性能に達し、さらに微調整を加えてもそれ以上向上しないことです。そこでJSRLでは、このガイドポリシーの進化を利用して、さらに高いパフォーマンスを発揮できるようにします。
学習開始時には、ガイドポリシーを一定のステップ数だけ展開し、エージェントが目標状態に近づくようにします。その後、探索ポリシーが引き継ぎ、目標に到達するように環境中の行動を継続します。
探索ポリシーの性能が向上するにつれて、ガイドポリシーのステップ数を徐々に減らし、探索ポリシーが完全に引き継ぐようにします。このプロセスにより、探索ポリシーは、各カリキュラム段階において、以前のカリキュラム段階の初期状態に到達するための学習のみを行えばよいというカリキュラムを作成することができます。

ここでは、ロボットアームが青いブロックを拾うことがタスクとなっています。ガイドポリシーはアームをブロックまで動かすことができますが、それを拾うことはできません。ガイドポリシーは、ロボットがブロックを掴むまで制御し、その後、探索ポリシーが引き継ぎ、最終的にブロックを拾うことを学習します。探索方針が向上するにつれて、ガイド方針によるエージェントの制御は少なくなっていきます。
3.JSRL:事前ポリシーを効率的に使用して強化学習をジャンプスタート(2/2)関連リンク
1)ai.googleblog.com
Efficiently Initializing Reinforcement Learning With Prior Policies
2)arxiv.org
Jump-Start Reinforcement Learning

