
1.PRIME:のシミュレーションログ使ってアクセラレータを新規に設計(1/3)まとめ
・ハードウェア設計には多くのシミュレーションが必要でMLがあっても手間がかかる作業
・過去データを使ってモデルを学習させ、次世代のアクセラレータを設計できないか考えた
・PRIMEはハードウェアシミュレーションを行わずにアクセラレータを設計する新アプローチ
2.PRIMEとは?
以下、ai.googleblog.comより「Offline Optimization for Architecting Hardware Accelerators」の意訳です。元記事は2022年3月17日、Amir YazdanbakhshさんとAviral Kumarさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Wesley Tingey on Unsplash
機械学習(Machine Learning)の進歩は、しばしばハードウェアや計算機システムの進歩に伴ってもたらされます。
例えば、視覚や言語などの様々な問題を解決するMLベースのアプローチの成長により、アプリケーションに特化したハードウェアアクセラレータ(Google TPUやEdge TPUなど)が開発されるようになりました。
しかし、目的とするアプリケーション向けにカスタマイズしたアクセラレータを設計するための標準的な手順では、ハードウェアの正確で合理的なシミュレータを考案するための手作業と、目的の最適化(たとえば、特定のアプリケーションを実行する際の低消費電力や応答遅延を最適化)のために、多くの時間を要するシミュレーションを実行する必要があります。
その際、チップ面積の上限やピーク電力など、さまざまな設計制約のもとで、計算資源やメモリ資源の総量と通信帯域の適切なバランスを見極める必要があります。しかし、これらの設計制約を満たすようにアクセラレータを設計すると、実現不可能な設計になってしまう事が多くあります。
これらの課題を解決するために、私達は「大量にある過去のアクセラレータ実験データを使って表現力豊かなディープニューラルネットワークモデルを学習し、学習したモデルを用いて、手間のかかるハードウェアシミュレーションをせずに、次世代の専用アクセラレータを設計することは可能でしょうか?」と考えました。
ICLR 2022で採択された論文「Data-Driven Offline Optimization for Architecting Hardware Accelerators」では、データ駆動型の最適化を行い、アクセラレータ設計とその性能指標(遅延、電力など)からなる既存のログデータ(従来のアクセラレータ設計時に記録されたデータ)のみを利用し、更なるハードウェアシミュレーションを行わずにハードウェアアクセラレータを設計する事に焦点を当てたアプローチ、PRIMEを紹介しています。
これにより、時間のかかるシミュレーションを実行する必要がなくなります。対象となるアプリケーションが変わっても(例えば、視覚、言語、その他の目的のためのMLモデル)、また、トレーニングセットに関連するが従来になかったアプリケーションに対しても、ゼロショットで過去の実験データを再利用することが可能になるのです。
PRIMEは、過去のシミュレーションデータ、実際に製造されたアクセラレータのデータベース、および実現不可能または失敗したアクセラレータ設計のデータベースで学習することができます。
シングルアプリケーションとマルチアプリケーションの両方に対応するこのアクセラレータ設計手法は、最新のシミュレーション駆動型手法に比べて性能を約1.2倍から1.5倍向上させ、必要な総シミュレーション時間をそれぞれ93%と99%大幅に短縮します。PRIMEはまた、ゼロショット設定において、未知のアプリケーションのための効果的なアクセラレータを構築し、シミュレーションベースの手法を1.26倍も上回りました。
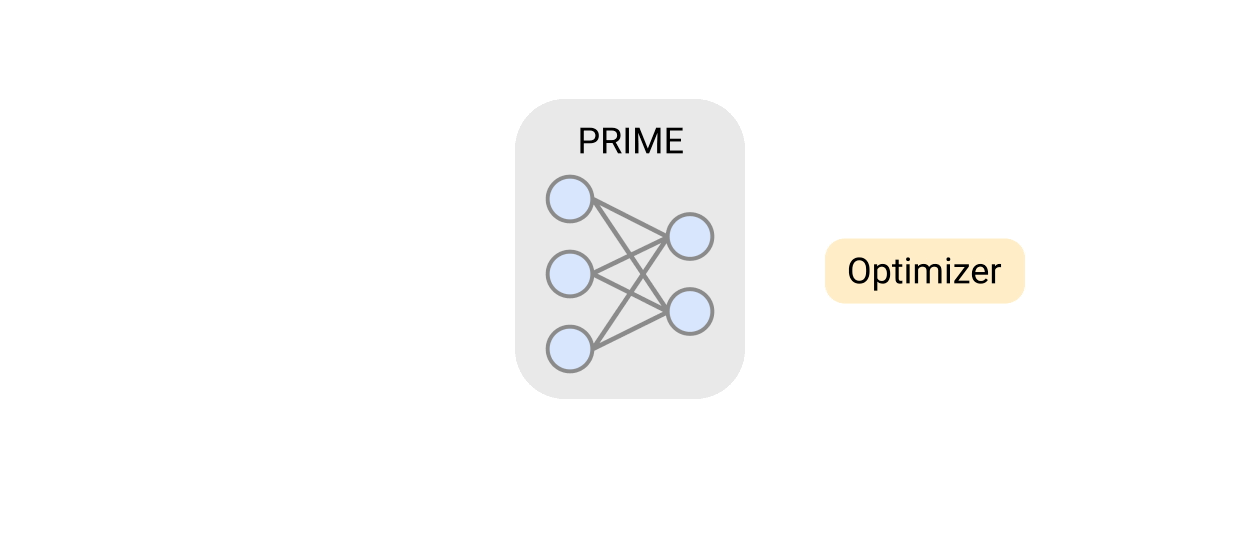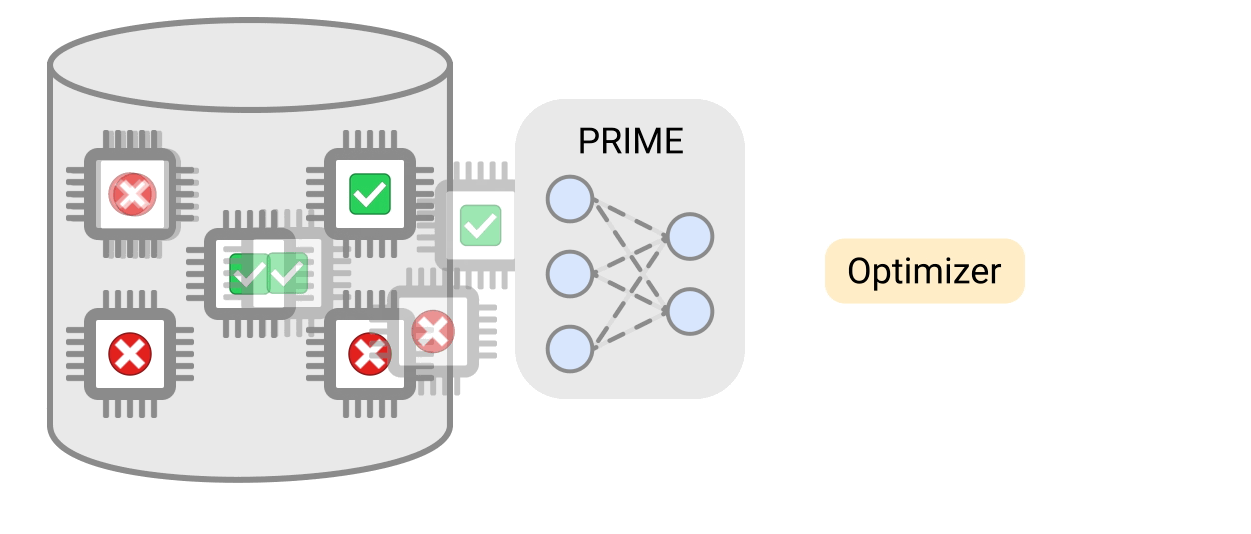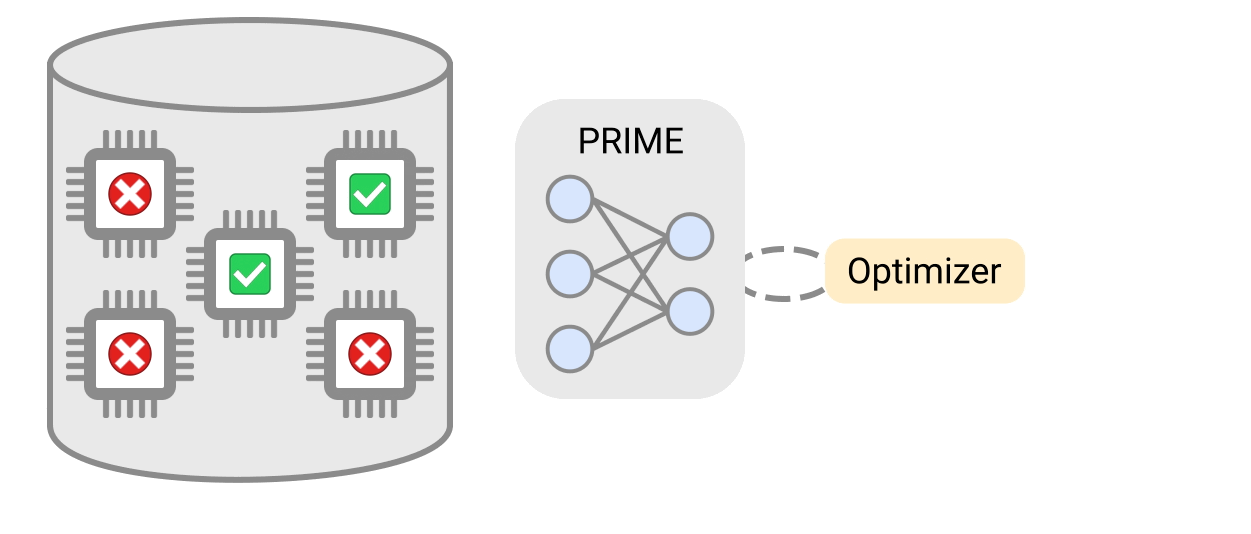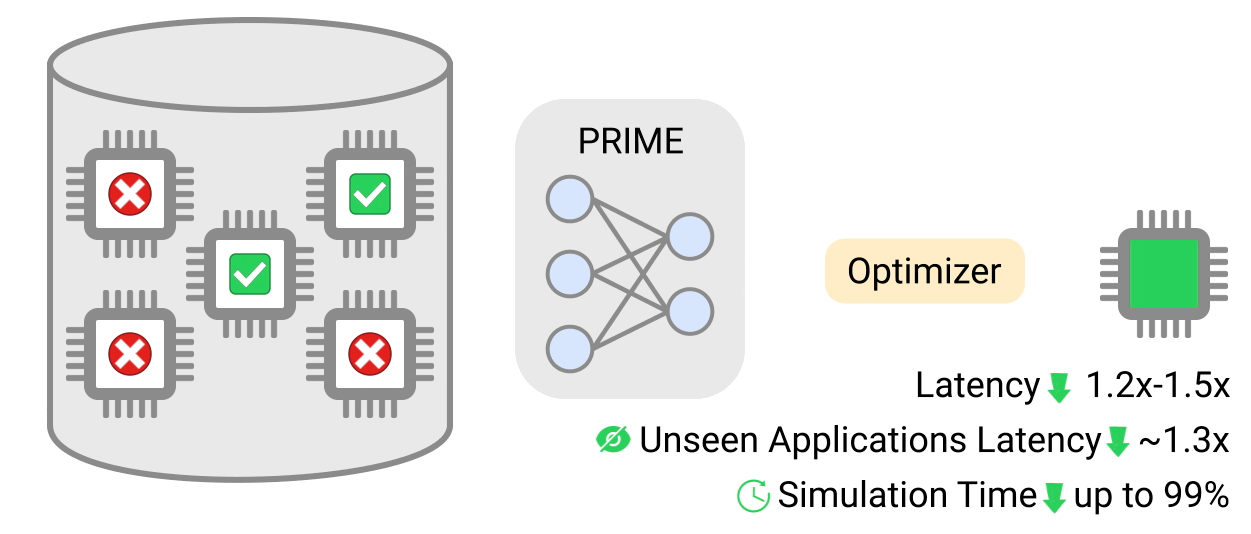
PRIMEは、実現可能なアクセラレータと実現不可能なアクセラレータからなるログデータを用いて保守的なモデルを学習し、設計制約を満たしながらアクセラレータを設計するために使用できます。PRIMEは、必要なハードウェアシミュレーション時間を最大99%削減しながら、最大1.5倍まで応答遅延が小さいアクセラレータを設計することができます。
アクセラレータ設計のためのPRIMEアプローチ
過去に設計されたアクセラレータのデータベースをハードウェア設計に利用する最もシンプルな方法は、教師あり機械学習を用いて、与えられたアクセラレータの目標性能を予測するモデルを入力として訓練することでしょう。その後、この学習したモデルの性能出力を、入力されたアクセラレータ設計に対して最適化することで、新しいアクセラレータを設計することができる可能性があります。
このようなアプローチは、モデルベース最適化(model-based optimization)として知られています。しかし、この単純なアプローチには重要な限界があります。それは、予測モデルが最適化の際に遭遇する可能性のあるすべてのアクセラレータのコストを正確に予測できることを前提としていることです!
教師あり学習で学習した予測モデルのほとんどは、敵対的なデータがサンプルに混ざると誤った予測することがよく知られています。敵対的なサンプルとは人間には通常のサンプルに見えてもモデルには違って見えるような「モデルを惑わす」サンプルです。
同様に、教師ありモデルの出力を最適化しても、学習されたモデルは有望に見えても、本来の目的ではひどい結果になる敵対的なサンプルが存在する事が示されています。
この制限に対処するため、PRIMEは、最適化の際に発見されるような敵対的な事例(後述)に惑わされない堅牢な予測モデルを学習します。
そして、シミュレータを構築するための標準的なオプティマイザーを用いて、このモデルを単純に最適化することができます。さらに重要なことは、従来の方法とは異なり、PRIMEは既存の実現不可能なアプローチのデータベースを利用して、設計してはいけないものを学ぶことができることです。
これは、「実現不可能なアプローチ」や「敵対的な事例」に対してペナルティを課す追加の損失項で教師あり学習を拡張することによって行われます。
この手法は、敵対的学習の一形態に似ています。
3.PRIME:のシミュレーションログ使ってアクセラレータを新規に設計(1/3)関連リンク
1)ai.googleblog.com
Offline Optimization for Architecting Hardware Accelerators
2)arxiv.org
Data-Driven Offline Optimization For Architecting Hardware Accelerators
3)github.com
google-research/prime/

