
1.SPL:ゆるくラベル付けされた動画に疑似的なラベルを付与して動画認識を改善(2/3)まとめ
・SPLは、教師-生徒学習の枠組みを発展させたシンプルな手法で教師モデルと生徒モデルからなる
・動画検索時に使用したテキストと教師が予測したラベルを組み合わせて教師とする新しい手法
・全体としてより良い擬似ラベルを得ることができ他の領域にも容易に拡張することが可能
2.SPLの原理
以下、ai.googleblog.comより「Learning from Weakly-Labeled Videos via Sub-Concepts」の意訳です。元記事は2022年3月7日、Zizhao ZhangさんとGuanhang Wuさんによる投稿です。
アイキャッチ画像のクレジットはアイキャッチ画像のクレジットはPhoto by norbert braun on Unsplash
サブ擬似ラベル(SPL)
SPLは、教師-生徒学習の枠組み(teacher-student training framework)を発展させたシンプルな手法です。この枠組みは自己学習や半教師有り学習の改善に有効であることが知られています。
教師-生徒学習の枠組みでは、教師モデルは高品質なラベル付きデータで学習し、その後、ラベルのないデータに擬似ラベルを付与します。生徒モデルは高品質なラベル付きデータと教師が予測した疑似ラベルが付与されたデータの両方で学習を行います。
従来の手法では、擬似ラベルの品質を向上させる方法がいくつか提案されていますが、SPLでは弱いラベル(すなわち、データ取得時に検索語として用いたテキスト)と教師が予測したラベルの両方からの知識を組み合わせるという新しいアプローチをとっており、全体としてより良い擬似ラベルを得ることができます。本手法は、時間的ノイズが問題となるビデオ認識に焦点を当てていますが、画像分類のような他の領域にも容易に拡張することができます。
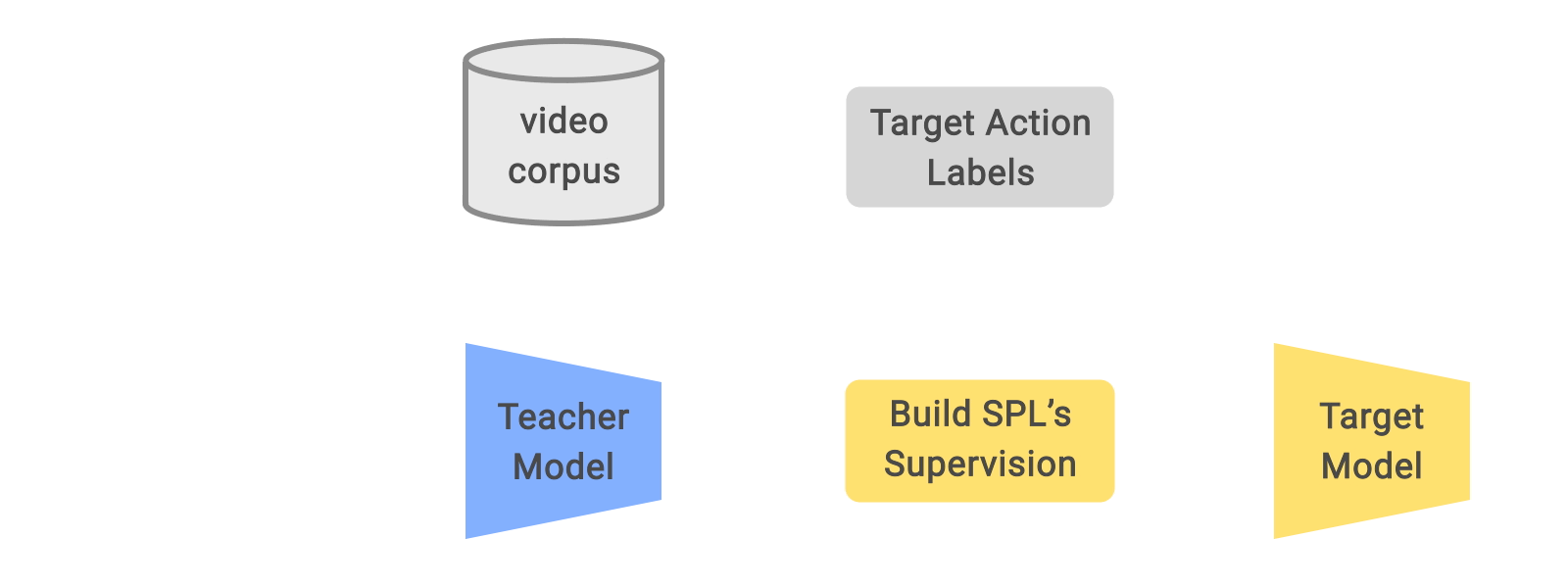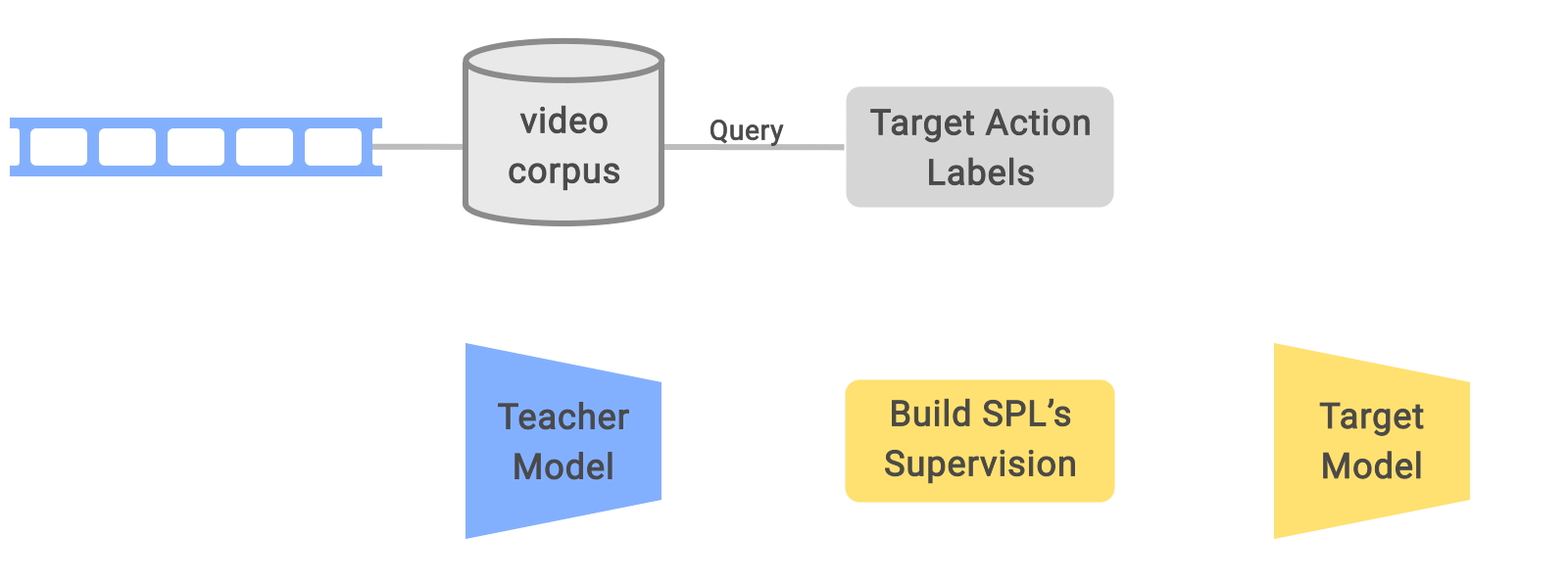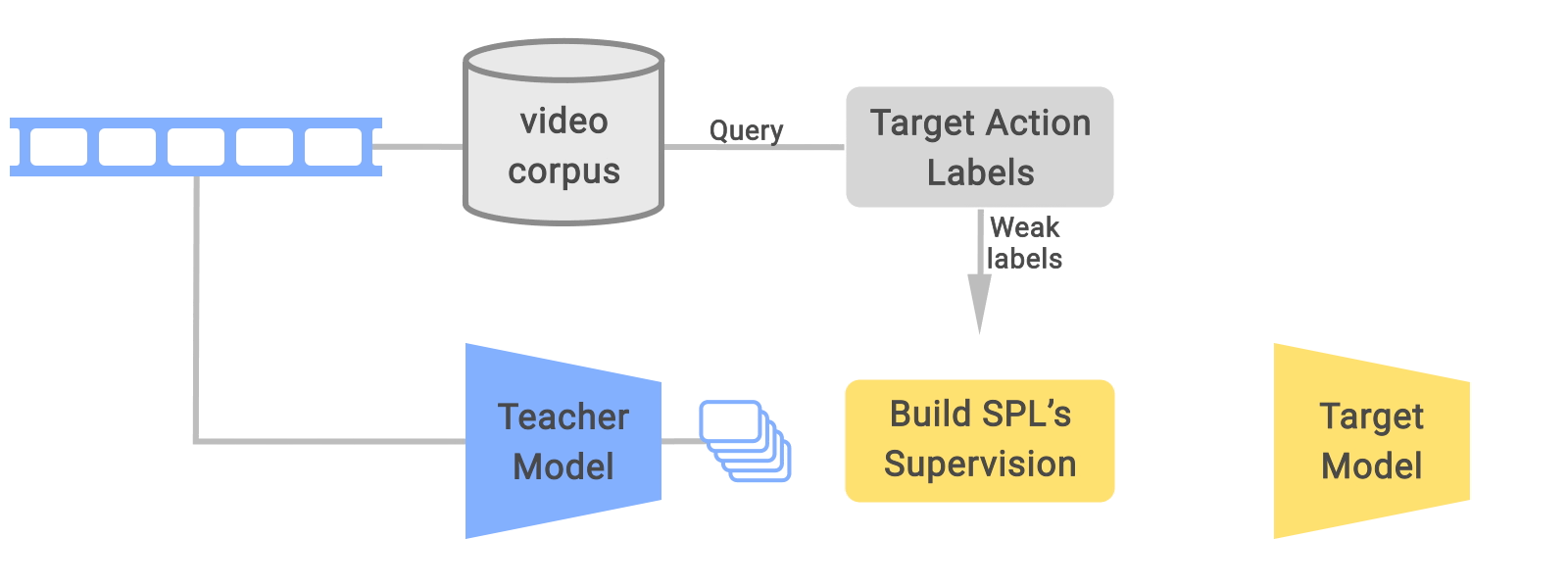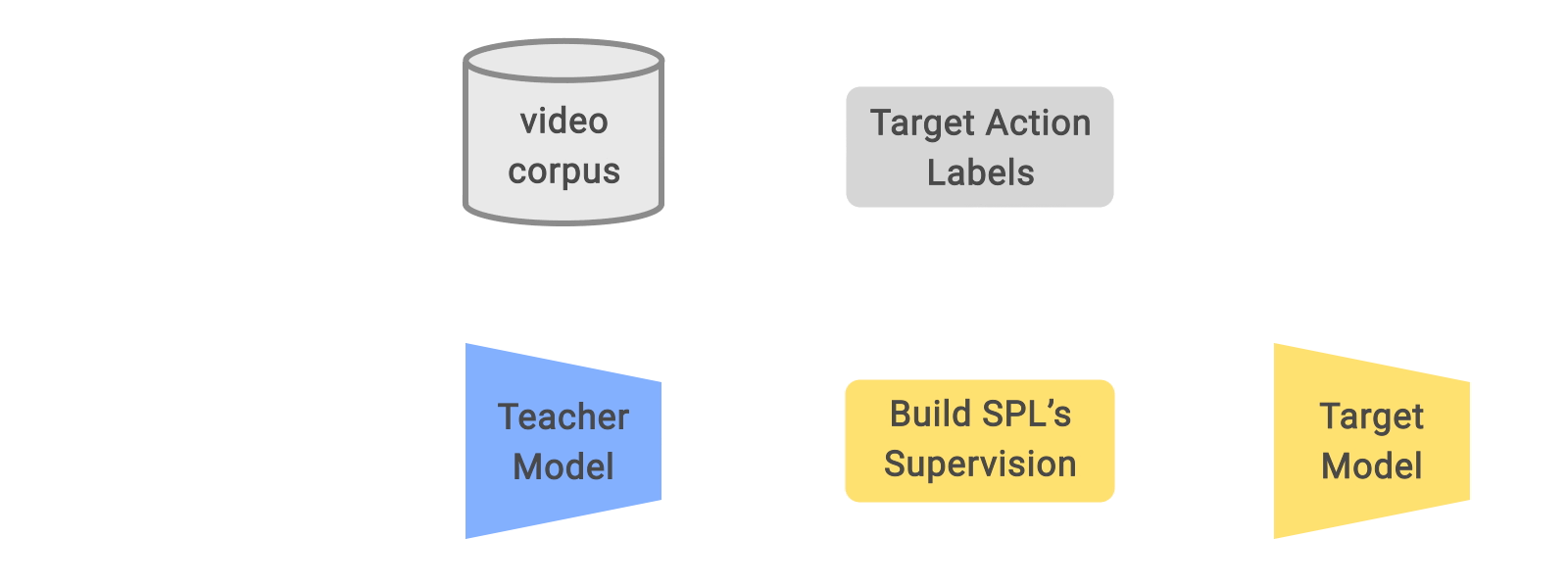
ゆるくラベル付けされた動画からSPLを介して学習する総体的な事前学習フレームワーク
トリミングされた各ビデオクリップは、「教師が予測したラベル」と「対応するトリミングされていないビデオを検索する際に使用された弱いラベル」を与えられたSPLにより再ラベル付けされます。
SPL法は「ノイズの多い」映像クリップは目的となる行動(すなわち、弱いラベルクラス)と意味的な関係を持つが、教師モデルが予測したクラスのような他の行動の重要な視覚成分も含む場合があるという観察から動機づけられています。
本手法では、弱いラベルから推定されたSPLと蒸留されたラベルを併用することで、強化された教師信号を捉え、事前学習時により良い特徴表現の学習を促し、下流の微調整タスクに利用できるようにします。
各ビデオクリップのSPLクラスを決定するのは簡単です。まず、ターゲットデータセットを使って学習した教師モデルを用いて、各ビデオクリップに対して推論を行い、教師が予測したクラスを得ます。
また、各クリップはトリミングされていない元ビデオのクラス(すなわち、検索時に使ったテキスト)によってラベル付けされます。2次元の混同行列(2-dimensional confusion matrix)を用いて、教師モデルの推論と元の弱い注釈の間の整合をとりまとめます。この混同行列に基づき、教師モデルの予測と弱いラベルを使って疑似ラベルの推測を行い、生のSPLラベル空間を得ます。
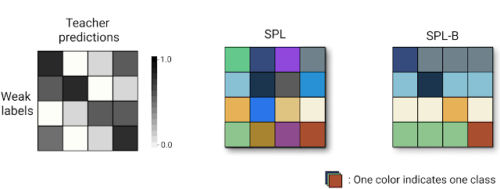
左:生のSPLラベル空間の基礎となる混同行列
中央:得られたSPLラベル空間(この例では16クラス)
右:SPL-B(別のバージョンのSPL)は、各行の一致と不一致のエントリを独立したSPLクラスとして照合することでラベル空間を縮小します。この例では8クラスのみを得ることができます。
3.SPL:ゆるくラベル付けされた動画に疑似的なラベルを付与して動画認識を改善(2/3)関連リンク
1)ai.googleblog.com
Learning from Weakly-Labeled Videos via Sub-Concepts
2)arxiv.org
Learning from Weakly-labeled Web Videos via Exploring Sub-Concepts
