
1.厳密な差分プライバシー保証を持つ連合学習(2/3)まとめ
・多くの外部要因によって利用可能なデバイスの数が大幅に変化し得るので困難であった
・学習に参加可能な端末が少ないとランダム性がないためプライバシーが緩まる事になる
・累積和と負相関ノイズを利用することによりこれらの課題を解決する事に成功した
2.差分プライバシーを用いた連合学習
以下、ai.googleblog.comより「Federated Learning with Formal Differential Privacy Guarantees」の意訳です。元記事は2022年2月28日、Brendan McMahanさんとAbhradeep Thakurtaさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Ruthson Zimmerman on Unsplash
差分プライバシーを用いた連合学習を実現するまでの道のり
2018年には、DP-SGDアプローチをユーザーレベルのDP保証で連合学習設定に拡張したDP-FedAvgアルゴリズムを発表し、2020年にはこのアルゴリズムを初めてモバイルデバイスに展開しました。このアプローチでは、学習メカニズムが特定のユーザーのデータに敏感すぎないようにし、経験則的なプライバシー監査技術により、ある種の暗記を排除しています。
しかし、DP-FedAvgで強力なDP保証を提供するためには、プライバシー保証増幅(amplification-via-sampling)の議論が不可欠でした。それでも、現実世界の様々なデバイスが参加するFLシステムにおいて、デバイスが大きな集団から正確かつ均一にランダムに抽出されることを保証する事は、複雑で検証しにくいものです。
1つの課題は、デバイスが多くの外部要因(例えば、デバイスがアイドル状態であること、従量課金接続でないこと、充電中であること)に基づいて接続(つまり「チェックイン」)するタイミングを選択するので、 利用可能なデバイスの数が大幅に変化し得るということです。
正式なプライバシー保証を達成するためには、以下のすべてを行うプロトコルが必要です。
(1)利用可能なデバイスの数が時間と共に大きく変化しても、学習を進めることができる
(2)利用可能なデバイスが予期せぬ、または任意に変化した場合でも、プライバシー保証を維持する事ができる
(3)効率化のため、クライアント端末は、トレーニングに参加するためにサーバにチェックインするかどうかを、他の端末の動向に影響を受けず、独自に決定可能である事。
ランダムにチェックインを行ってプライバシーを増幅に関する初期の研究は、これらの課題を浮き彫りにし、実現可能なプロトコルが導入されましたが、それを展開するためには、私たちの製品基盤に複雑な変更を加えなければなりませんでした。
さらに、DP-SGDアプローチで検証したように、ランダムチェックインによるプライバシー増幅は、多くのデバイスが利用可能であることに依存しています。例えば、1000台のデバイスがトレーニングに利用可能で、各トレーニングステップに少なくとも1000台のデバイスの参加が必要な場合、
(1)現在利用可能な全てのデバイスを含める。選択にランダム性がないため大きなプライバシーコストを支払う事になる
または
(2)学習を一時停止してより多くのデバイスが利用可能になるまで進捗させない
のいずれかが必要となります。
DP-FTRL:証明可能な差分プライバシーを実現したFederated Learning
この課題を解決するために、DP-FTRLアルゴリズムは2つの重要な見解に基づいて構築されています。
(1)勾配降下型アルゴリズムの収束は、主に個々の勾配の精度ではなく、勾配の累積和の精度に依存する
(2)集計サーバによって追加される負相関ノイズを利用することにより、強いDP保証で累積和を正確に推定できる。基本的に、ある勾配にノイズを加え、後の勾配から同じノイズを減算
DP-FTRLはTree Aggregationアルゴリズムを用いて、これを効率的に実現します。
以下の図は、個々の勾配ではなく、累積和を推定することがいかに有効であるかを示しています。
DP-FTRLとDP-SGDによってもたらされるノイズが、各反復で1単位ずつ右に移動する真の勾配(ノイズを含まない、黒色)と比較して、モデルの学習にどのような影響を与えるかを見ています。
累積和に基づく個々のDP-FTRL勾配推定値(青)は、個別にノイズを除去したDP-SGD推定値(オレンジ)よりも平均二乗誤差が大きくなりますが、DP-FTRLノイズは負の相関があるため、ステップ毎に一部が相殺され、全体の学習軌道は真の勾配降下のステップに近くなることがわかります。
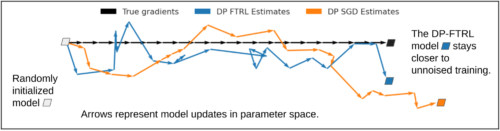
強力なプライバシー保証を提供するため、1人のユーザーが更新を行う回数を制限しています。各デバイスは、過去に自分が貢献したモデルをローカルに記憶し、それらのモデルについて以降のラウンドでサーバーに接続しないことを選択することができます。
3.厳密な差分プライバシー保証を持つ連合学習(2/3)関連リンク
1)ai.googleblog.com
Federated Learning with Formal Differential Privacy Guarantees
2)arxiv.org
Private Online Prefix Sums via Optimal Matrix Factorizations
