
1.Platform-Aware NAS:ハードウェア性能を最高に引き出すニューラル・アーキテクチャ探索(1/2)まとめ
・最新のアクセラレータのピーク性能とMLモデル実行時の性能の間にギャップが広がりつつある
・指標(FLOPS)ではなく性能(処理能力や応答速度)を意識したML最適化手法は未開拓である
・実行するハードウェアに自動的に適応させる「ハードウェアを意識したNAS」を新たに開発
2.Platform-Aware NASとは?
以下、ai.googleblog.comより「Unlocking the Full Potential of Datacenter ML Accelerators with Platform-Aware Neural Architecture Search」の意訳です。元記事は2022年2月8日、Sheng LiさんとNorman P. Jouppiさんによる投稿です。
データセンターの内部っぽいアイキャッチ画像のクレジットはPhoto by jesse orrico on Unsplash
TPUやGPUなどの機械学習(ML:Machine Learning)用で、データセンター(DC:DataCenter)内で使われるアクセラレータの設計と実装における継続的な進歩は、最新のMLモデルやアプリケーションを大規模に強化するために不可欠でした。
これらの改良型アクセラレータは、従来のコンピューティングシステムよりも数桁優れたピーク性能(FLOPsなど)を発揮します。しかし、最新のハードウェアが提供するピーク性能と、そのハードウェア上でMLモデルを実行したときに実際に得られる性能の間には、急速にギャップが広がっています。
このギャップを解決する一つのアプローチは、ハードウェア性能(例:処理能力(throughput)、応答速度(latency))とモデル品質の両方を最適化するハードウェアに特化したMLモデルを設計することです。
近年、MLモデルのアーキテクチャ設計を自動化するための新たなパラダイムであるNAS(Neural Architecture Search)では、ハードウェア性能を最適化目標に含める等、実行プラットフォームを考慮した多目的最適化アプローチが採用されています。
このアプローチは、実際にモデル性能を向上させることができましたが、基盤となるハードウェアアーキテクチャの詳細は、モデルからはわかりません。そのため、強力なデータセンタ内に設置する機械学習用アクセラレータ(DC ML accelerators)用に、ハードウェアに特化した最適化を行い、ハードウェアに優しいMLモデルアーキテクチャを構築するという未開拓の可能性が残されています。
CVPR 2021で発表された「Searching for Fast Model Families on Datacenter Accelerators」では、NASをモデルのアーキテクチャを実行するハードウェアに自動的に適応させる、最先端の「ハードウェアを意識したNAS(hardware-aware NAS)」に進歩させました。
私たちが提案するアプローチは「これ以上ハードウェア性能を引き出すためにはモデルの品質を落とすしかないレベルの最適化(パレート最適化(Pareto optimization)と呼ばれます)」を達成するモデル群を見つけるものです。
これを達成するために、単一モデルとモデル群の両方を発見するためのNAS探索空間の設計に、ハードウェアアーキテクチャの深い理解を注入します。
ハードウェアと従来のモデル・アーキテクチャの性能差の定量的分析を行い、性能最適化の目標として、性能を図る値(FLOPs)ではなく、真のハードウェア性能(すなわち、処理能力、応答速度)を使用することの利点を実証しています。
この先進的なハードウェア対応NASを活用し、EfficientNetアーキテクチャをベースに、EfficientNetXと呼ばれるモデル群を開発し、TPUやGPU上でのパレート最適化MLモデルに対する本手法の有効性を実証しました。
DC MLアクセラレータ用のプラットフォームを意識したNAS
高性能を実現するために、MLモデルは最新のMLアクセラレータに適応する必要があります。プラットフォーム対応型NASは、NASの3つの柱、
(i)探索目的
(ii)探索空間
(iii)探索アルゴリズム(下図)
にハードウェアアクセラレータの特性に関する知識を統合するものです。
私たちは新しい探索空間に注目しました。探索空間には、モデルを構成するために必要な土台が含まれており、MLモデルアーキテクチャとアクセラレータハードウェアアーキテクチャの間を結ぶ重要な繋がりであるためです。
TPU/GPUに特化した探索空間をTPU/GPUに馴染む演算操作を含めて構築し、NASにハードウェアの意識を吹き込みます。
例えば、アクセラレータ内の異なるハードウェアコンポーネントが可能な限り効率的に連携するよう、並列性を最大化することが重要な適応策となります。
これには、行列/テンソル計算を行うTPUの行列乗算ユニット(MXU:Matrix Multiplication Units)やGPUのTensorCore、ベクトル処理を行うTPUのベクトル処理ユニット(VPU:Vector Processing Units)、GPUのCUDAコアなどが含まれます。
また、最高の性能を発揮するためには、モデルの演算強度(arithmetic intensity、高帯域幅メモリ上で演算性能と並列性を最適化する事)の最大化が重要です。
ハードウェアのポテンシャルを最大限に活用するためには、MLモデルはこれらのハードウェアコンポーネントの内部および全体で高い並列性を達成することが重要です。
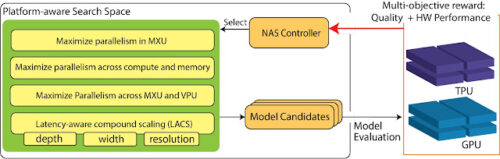
TPU/GPU上のプラットフォーム対応NASの概要、探索空間と探索目的を強調しています。
3.Platform-Aware NAS:ハードウェア性能を最高に引き出すニューラル・アーキテクチャ探索(1/2)関連リンク
1)ai.googleblog.com
Unlocking the Full Potential of Datacenter ML Accelerators with Platform-Aware Neural Architecture Search
2)openaccess.thecvf.com
Searching for Fast Model Families on Datacenter Accelerators(PDF)

