
1.DeepCTRL:ニューラルネットワークにルールを教えて制御する試み(1/3)まとめ
・ニューラルネットワークはデータから物理法則等を学習できるが誤差が大きい
・エネルギー保存の法則など、ルールを直接学習できると効率が向上するはず
・DeepCTRLはデータやモデルに依存せずにルールをモデルに学習させる手法
2.DeepCTRLとは?
以下、ai.googleblog.comより「Controlling Neural Networks with Rule Representations」の意訳です。元記事は2022年1月28日、Sungyong SeoさんとSercan O. Arikさんによる投稿です。
ルールを気にして行動しているように見えるアイキャッチ画像のクレジットはPhoto by Chris Chow on Unsplash
ディープニューラルネットワーク(DNN:Deep Neural Networks)は、学習データのサイズとカバー範囲が大きくなるほど、より正確な結果が得られます。
高品質で大規模なラベル付きデータセットに投資することは、モデル改良の1つの方法ですが、もう1つは事前知識(簡潔に「ルール(rules)」と呼ばれます)を活用することです。
ルールとは、経験則に基づく推論、方程式、連想論理、または制約などの事前知識の事です。
物理学でよくある例として、二重振り子システムの次の状態を予測するという課題がモデルに与えられたとしましょう。モデルは経験的データのみからある時点におけるシステムの全エネルギーを推定することを学習するかもしれませんが、既知の物理的制約(例えばエネルギー保存の法則)を反映する方程式が与えられない限り、エネルギー量を過大評価してしまう事が多いです。
確立された物理法則を、モデルはそれ自体で捕捉する事ができないのです。DNNが単にデータから学ぶだけでなく、関連する知識を吸収できるように、このようなルールを効果的に教えるにはどうしたらよいでしょうか?
NeurIPS 2021で発表した「Controlling Neural Networks with Rule Representations」では、データ型やモデルアーキテクチャに依存しない、入出力に対して定義されたあらゆる種類のルールをモデルに適用するために用いられるアプローチ、Deep Neural Networks with Controllable Rule Representations(DeepCTRL)が紹介されています。
DeepCTRLの主な利点は、ルールをどの程度強く守らせるかを変更するために再トレーニングを必要としないことです。推論実行時に、ユーザは望ましい精度に基づいてルールの強度を調整することができます。
また、入力を微妙に摂動させる新手法を提案し、DeepCTRLを微分できない制約の下でも一般化するのに役立てます。物理学や医療など、ルールを組み込むことが重要な実世界の領域において、深層学習にルールを教えるDeepCTRLの有効性を実証しています。
DeepCTRLは、モデルがルールにより忠実に従うようにする一方で、下流タスクでの精度向上も実現するため、学習済みモデルの信頼性とユーザーの信用を向上させます。さらに、DeepCTRLは、データサンプル上でのルールの仮説検定や、データセット間で共有されたルールに教師なし適応するといった、新しい使用例を可能にします。
ルールから学習することのメリットは多面的です。
・ルールは、最小限のデータしかないケースに対して付加情報を提供し、テストの精度を向上させることができます。
・DNNの普及の大きなボトルネックは、その推論の根拠や矛盾を人間が理解できない事です。矛盾を最小限に抑えることで、ルールはDNNの信頼性とユーザーの信用を向上させることができます。
・DNNは、人間が感知できないようなわずかな入力の変化にも敏感に反応してしまいます。ルールを用いることで、モデルの探索空間がさらに制約され、仕様不足(Underspecification)を減らすことができ、これらの変化の影響を最小化することができます。
ルールとタスクを一緒に学習
従来のルールの実装方法は、損失を計算する際にルールを含めることでルールを組み込んでいました。このアプローチには3つの限界があり、私たちはこれを解決することを目指しています。
(i)学習前にルールの強さを定義する必要がある(そのため、データがどれだけルールを満たしているかに基づいて学習済みモデルを柔軟に操作する事ができません)
(ii)学習時の設定とミスマッチがあると推論時にルールの強度を対象データに適応させる事ができません
(iii)ルールベースの目的が学習可能パラメータに対して微分可でなければなりません(ラベル付きデータから学習するため)
以上の3点です。
DeepCTRLは、ルール表現をデータ表現と組み合わせて作成することで、標準的な学習手法を修正します。これは、推論時にルール強度を制御できるようにするための鍵です。学習中、これらの表現は、αで示される制御パラメータと確率的に連結され、単一の特徴表現となります。推論時にαを変更することで、未知データに対するモデルの振る舞いを制御することができます。
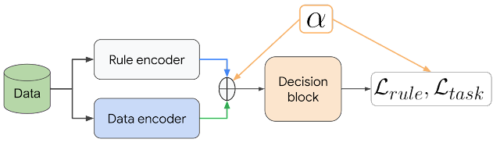
DeepCTRLはデータエンコーダとルールエンコーダを対にして、2つの潜在的な特徴表現を生成し、それらは対応する目的と結合される。制御パラメータαは推論時に調整可能であり、各エンコーダの相対的な重みを制御する。
3.DeepCTRL:ニューラルネットワークにルールを教えて制御する試み(1/3)関連リンク
1)ai.googleblog.com
Controlling Neural Networks with Rule Representations
2)arxiv.org
Controlling Neural Networks with Rule Representations

