
1.視覚を聴覚で補うような脳の感覚置換能力を実現する強化学習(1/2)まとめ
・人間は触覚を使って視覚を補う等の驚くべき感覚置換能力を持つが人工知能はこれを持たない
・強化学習は入力データサイズが固定されている事や各要素が意味を持つ事を想定しているため
・感覚置換能力を実現するため順列不変の強化学習エージェントを研究しその性能を検証した
2.感覚の置換とは?
以下、ai.googleblog.comより「Permutation-Invariant Neural Networks for Reinforcement Learning」の意訳です。元記事は2021年11月18日、Google Research TokyoのDavid HaさんとYujin Tangさんによる投稿です。
おそらく人間の脳の構造にヒントを得たのだと思いますが、とても面白いお話です。
従来のモデルが、例えれば、目と脳を直結させるような構成になっていたものを、人間の五感に相当する感覚ニューロンを前段に置く事で、より人間の脳の構成に近づき、より堅牢性と柔軟性が高まったと言う事だと思います。
アイキャッチ画像のクレジットはPhoto by Tony Rojas on Unsplash
Paul Bach-y-Rita, 「Livewired: The Inside Story of the Ever-Changing Brain」より引用
人は、ある感覚モダリティ(例:触覚)を使って、通常は別の感覚(例:視覚)で収集される環境情報を供給するという驚くべき能力を持っています。
この適応能力は「感覚置換(sensory substitution)」と呼ばれ、神経科学の世界ではよく知られた現象です。例えば、物が逆さまに見えることに慣れる、右にハンドルを切ると左に曲がる自転車に乗れるようになる、舌につけた電極から発せられる視覚情報を解釈して「見る」ことができるようになる、といった難しい適応は、習得するまでに数週間から数ヶ月、あるいは数年を要しますが、人間はいずれ感覚を代替して適応できるようになります。


感覚置換の例
左:舌に装着する表示装置(Maris and Bach-y-Rita, 2001; Image: Kaczmarek, 2011)
右:1931年にErismannとKohlerが最初に考案した「逆さまゴーグル」(画像:Wikipedia)。
一方、ほとんどのニューラルネットワークは、感覚置換には全く適応できません。例えば、強化学習(RL:Reinforcement Learning)エージェントの多くは、入力があらかじめ指定された形式であることを必要とし、そうでなければ失敗します。
例えば、強化学習(RL)エージェントの多くは、サイズが定まった入力を想定しており、入力の各要素には、指定された場所の画素強度や、位置や速度などの状態情報といった正確な意味がある事を想定しています。
一般的なRLベンチマークタスク(AntやCart-poleなど)では、現在のRLアルゴリズムで学習されたエージェントは、感覚的な入力が変更されたり、タスクとは無関係なノイズの多い入力が追加されたりすると、失敗してしまいます。
NeurIPS 2021のスポットライトペーパーである「The Sensory Neuron as a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning」では順列不変のニューラルネットワーク(permutation invariant neural network)エージェントを探求します。
このためには、固定された意味を明示的に想定するのではなく、各感覚ニューロン(環境から感覚入力を受け取る受容体)が入力信号の意味と文脈情報を理解する必要があります。私たちの実験は、そのようなエージェントが、追加の冗長またはノイズの多い情報を含む観測、および破損して不完全な観測に対して堅牢であることを示しています。

感覚置換に適応する順列不変の強化学習エージェント
左:Antの28個の観測データの順序は、200タイムステップごとにランダムにシャッフルされます。標準的な方針とは異なり、私達の方針は突然の入力の順列変更に影響されません。
右:冗長でノイズの多い入力を与えられたCart-Poleエージェント(操作可能なWebデモはattentionneuron.github.ioにあります)
これらのエージェントは、AntやCart poleの例のような状態観測環境での感覚置換に加えて、複雑な視覚観測環境(画素観測のみを用いるCarRacingゲームなど)でも感覚置換に適応し、入力画像の背景が常に入れ替わるような状況でもパフォーマンスを発揮できることを示しています。

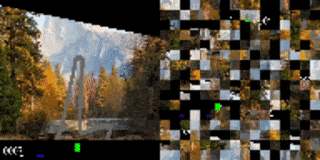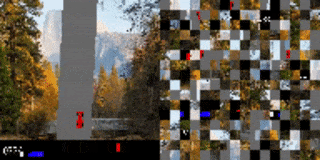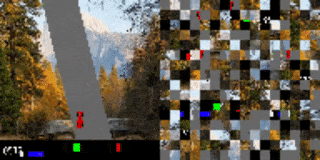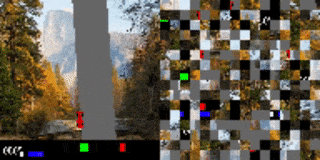
CarRacingからの視覚入力を小さな断片に分割し、その順序をシャッフルしました。追加トレーニングなしに、元のトレーニング用背景(左)を新しい画像(右)に置き換えても,エージェントのパフォーマンスは変わりません。
順列不変のニューラルネットワークの実現方法
私たちの手法は、各時間ステップで環境からの観測値を受け取り、その観測値の各要素を、構成は同じだが個別のニューラルネットワーク(感覚ニューロン(sensory neurons)と呼びます)に入力します。感覚ニューロン同士は固定された関係を持ちません。
それぞれの感覚ニューロンは、特定の感覚入力チャネルからの情報のみを時間経過とともに統合します。それぞれの感覚ニューロンは全体像のごく一部しか受け取っていないため、全体的に一貫した行動をとるためには、コミュニケーションによって自己組織化する必要があります。
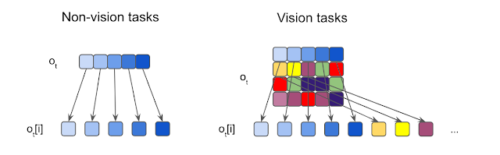
観察の断片化の図
各入力を要素に断片化し、要素を独立した感覚ニューロンに供給します。入力が通常一次元ベクトルである非視覚タスクの場合、各要素はスカラーです。 視覚タスクでは、各入力画像を重複しない断片に切り抜きます。
3.視覚を聴覚で補うような脳の感覚置換能力を実現する強化学習(1/2)関連リンク
1)ai.googleblog.com
Permutation-Invariant Neural Networks for Reinforcement Learning
2)attentionneuron.github.io
The Sensory Neuron as a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning
3)github.com
google / brain-tokyo-workshop

