
1.MMCC:ラベル付けされていない動画から将来を予測する(2/2)まとめ
・MMCCはラベル無しで時間的なサイクルを見つけるようにモデルを学習させる
・学習完了後MMCCはビデオの複雑な変化を捉えて意味のある状態変化を識別可能
・時間的に離れた行動を予測したり画像の集まりを時系列に並べるゼロショットが可能
2.MMCCのゼロショット能力
以下、ai.googleblog.comより「Making Better Future Predictions by Watching Unlabeled Videos」の意訳です。元記事は2021年11月11日、Dave EpsteinさんとChen Sunさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Icons8 Team on Unsplash
モデルが未来から現在を予測したときに、実際の現在との間に生じる不一致が、周期的整合性における損失です。直感的には、この学習目標は、予測された未来がその過去について十分な情報を含んでいて反転可能であることを要求しており、同じ実体に対する意味のある変化に対応する予測(例えば、トマトがマリナラソースになるとか、ボウルの中の小麦粉と卵が生地になるとか)につながります。
さらに、クロスモーダルエッジを含めることで、将来の予測がどちらのモーダルでも意味のあるものになります。時間的エッジ関数とクロスモーダルエッジ関数を直接学習するために、ソフトアテンションテクニックを使用しています。ソフトアテンションでは、まず各ノードがエッジのターゲットノードになる可能性を出力し、次にすべての可能な候補の中から加重平均を取ることでノードを「選択」します。
重要なのは、この循環グラフ制約は、モデルが学習すべき時間的エッジの種類をほとんど仮定せず、最終的に一貫したサイクルを形成することができることです。これにより、意味のある変化を手動でラベル付けすることなく、将来の予測に重要な長期的な時間的ダイナミクスを出現させることができる。
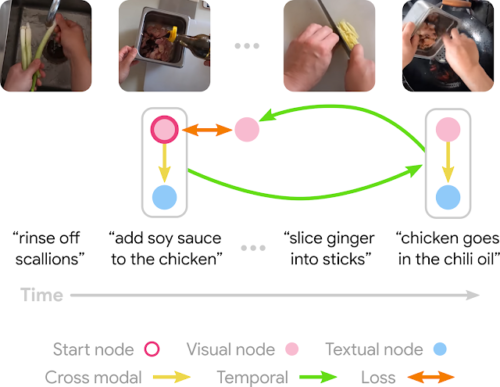
学習目標の一例。鶏肉を醤油で味付けした後に鶏肉をチリオイルに入れる事は、鶏肉の調理において隣り合った2つのステップであるため、サイクルグラフが構築されることが期待されます。(HowTo100Mの動画)
実世界のビデオにおけるサイクルの発見
MMCCは、明示的な検証済みラベルを使用せずに、長いビデオシーケンスとランダムにサンプリングされた開始条件(フレームまたはテキストの抜粋)のみを使用して、時間的なサイクルを見つけるようにモデルに要求します。学習完了後、MMCCは、ビデオの複雑な変化を捉えて意味のあるサイクルを識別することができます。

フレームが入力されると(左)、MMCCはビデオのナレーションから関連するテキストを選択し、フレームとテキストの両方から得た情報を使って未来のフレームを予測します。(中)。次に、このフレームの未来に関連するテキストを見つけ、そのテキストを使って過去の画像を予測します(右)。MMCCは、物体や風景が時間とともにどのように変化するかという知識を用いて、「サイクルを閉じる(closes the cycle)」ことで、その遷移が開始した画像で終了します。(ビデオはHowTo100Mより)
このモデルは、動画のフレームではなくナレーション付きのテキストを与えても、関連する遷移を見つけることができます。(HowTo100Mのビデオ)
ゼロショット能力を応用
MMCCが動画全体の時間的に意味のある遷移を識別するために、動画内の各フレームのペア(A, B)に対して、モデルの予測に基づいて「遷移した可能性が高いスコア」を定義付けします。BがAの未来に関するモデルの予測に近いほど、割り当てられるスコアは高くなります。そして、このスコアに基づいてすべてのペアをランク付けし、過去に見たことのない映像から検出された現在と未来のフレームのうち、最も高いスコアのペアを以下に表示します。

8つのランダムな動画から最高得点のペアが選んだ結果です。このモデルの幅広いタスクでの汎用性が示されています。(HowTo100Mの動画)
これと同じ方法で、時系列に並んでいないビデオフレームの集まりを、微調整なしで時系列にソートすることができます。これは、各フレーム間で隣接するフレームの総合的な信頼性スコアを最大化する順序を見つけることで行います。

左:3つの動画のフレームをシャッフルしたもの
右 MMCCがフレームのシャッフルを並べなおしたところ。各フレームの下に真の順序が示されています。MMCCが検証済みラベルと異なった順番を予測した場合でも、その予測が妥当であると思われることが多く、他の有りうる順序と見なす事ができます(HowTo100Mの動画)
未来予測の評価
ここでは、数分前の行動を予測するモデルの能力を評価しました。
Top-k recall指標を使用しました。これは、モデルが正しい未来を検索する能力を測定する指標です(高いほど良い)。
CrossTaskは、主要な行動を指示するラベルを持つビデオデータセットですが、MMCCは、将来起こりうる行動を推測するという点で、これまでの自己教師付きの最新モデルよりも優れていました。
| Recall | |||
| Model | Top-1 | Top-5 | Top-10 |
| Cross-modal | 2.9 | 14.2 | 24.3 |
| Repr. Ant. | 3 | 13.3 | 26 |
| MemDPC | 2.9 | 15.8 | 27.4 |
| TAP | 4.5 | 17.1 | 27.9 |
| MMCC | 5.4 | 19.9 | 33.8 |
まとめ
私達は、ナレーション付きの教育ビデオを循環させることで、時間的な変遷を学習する自己教師あり学習手法を紹介しました。
このモデルのアーキテクチャは単純であるにもかかわらず、視覚や言語における意味のある長期的な遷移を発見することができ、時間的に離れた行動を予測したり、画像の集まりを時系列に並べるような難しい下流タスクを、追加でトレーニングせずとも適用することができます。
このモデルをエージェントに転移し、エージェントが長期的な計画を立てることができるようにする事などは将来的に興味深い研究の方向性です。
謝辞
Dave Epstein, Jiajun Wu, Cordelia Schmid, and Chen Sunを中心としたチームで研究を行いました。Alexei Efros, Mia Chiquier, そして Shiry Ginosar にはフィードバックを、Allan Jabriには図のデザインのインスピレーションをいただきました。また、ビデオの時間経過サイクルについて初期の段階で洞察に富んだ議論をしてくださったDídac SurísとCarl Vondrickに感謝します.
3.MMCC:ラベル付けされていない動画から将来を予測する(2/2)関連リンク
1)ai.googleblog.com
Making Better Future Predictions by Watching Unlabeled Videos
2)arxiv.org
Learning Temporal Dynamics from Cycles in Narrated Video

