
1.GoEmotions:きめ細かい感情分類を行うためのデータセット(2/2)まとめ
・クラスタリングすると曖昧な感情はポジティブな感情に関係している事が判明
・喜びと興奮、緊張と恐怖、悲しみと嘆き、苛立ちと怒りなども密接な相関関係
・絵文字を感情表現と見なしてTwitter投稿を利用する事などは今後の方向性
2.GoEmotionsによる感情分類
以下、ai.googleblog.comより「GoEmotions: A Dataset for Fine-Grained Emotion Classification」の意訳です。元記事の投稿は2021年10月28日、Dana AlonさんとJeongwoo Koさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Tengyart on Unsplash
GoEmotionsの分類が基礎的なデータと一致することを検証するために、主成分分析(PPCA:Principal Preserved Component Analysis)を実行しました。
これは、2組の評価者の間で最も高い共同変動(joint variability)を示す感情判断の線形結合を抽出することで、2つのデータセットを比較する手法です。
これにより、評価者間の一致度が高い感情を次元として明らかにすることができます。PPCAは以前、ビデオや音声における感情認識の主要な次元を理解するために使用されましたが、ここでは文章における感情の主要な次元を理解するために使用します。
その結果、各成分が有意(すべての次元でp値<1.5e-6)であることがわかりました。
これは、各感情がデータのユニークな部分を捉えていることを示しています。これは、音声における感情認識に関する従来の研究では、感情の30の次元のうち12の次元のみが有意であるとされていたことを考えると、決して些細なことではありません。
私たちは、定義された感情のクラスタリングを、評価者の判断の相関に基づいて調べました。この方法では、2つの感情が評価者によって頻繁に共選(co-selected)されている場合、それらは一緒にクラスタリングされます。
その結果、私達の分類法では感情を定義していないにもかかわらず、感情(ネガティブ、ポジティブ、曖昧)の観点から関連する感情が集まっており、評価の質と一貫性を示していることがわかりました。
例えば、ある評価者があるコメントに対して「興奮」を選んだ場合、別の評価者は「恐怖」ではなく「喜び」などの相関関係のある感情を選ぶ可能性が高いと考えられます。驚くべきことに、曖昧な感情はすべてクラスター化され、ポジティブな感情とより密接にクラスター化されました。
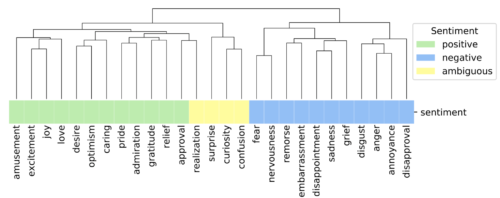
同様に、喜び(joy)と興奮(excitement)、緊張(nervousness)と恐怖(fear)、悲しみ(sadness)と嘆き(grief)、苛立ち(annoyance)と怒り(anger)など、強度の点で関連性のある感情も密接な相関関係があります。
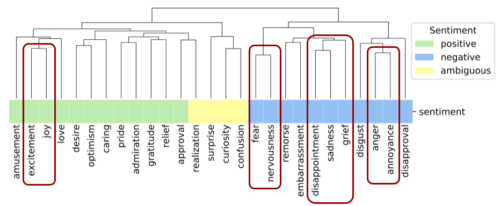
私達の論文では、GoEmotionsを用いた追加の分析とモデリング実験を行っています。
今後の研究:人間によるラベリング作業を代替
GoEmotionsは人間が注釈をつけた大規模な感情データを提供していますが、経験則的(heuristics)な手法を用いて自動的に弱いラベリングを行う感情データセットも存在します。
主な経験則的な手法は、感情関連のTwitterタグを感情カテゴリとして使用するもので、安価に大規模なデータセットを生成することができます。しかし、このアプローチには複数の理由で限界があります。
例えば、Twitterで使用されている言葉は他の多くの言語領域とは明らかに異なるため、データの応用性が制限されます。また、ハッシュタグは人間が生成したものであり、直接使用すると、完全または部分的に意味が重複するケースがあり、分類上の不整合が発生しやすいです。更にこのアプローチがTwitterに特化しているため、他の言語資料への適用が制限されること、などです。
そこで私達は、ユーザーの会話に埋め込まれた絵文字を感情カテゴリに利用するという、より簡単に利用できる代替手段を提案します。このアプローチは、絵文字が適度に出現する言語資料であれば、会話を含むすべての言語資料に適用できます。絵文字はTwitterのタグに比べて標準化されており、まばらではないため、不整合が少なくなります。
なお、提案されているTwitterタグや絵文字の使用は、いずれも感情理解を直接目的としたものではなく、会話表現のバリエーションを目的としたものです。例えば、以下の会話では、🙏は感謝の気持ちを、🎂はお祝いの表現を、🎁は「プレゼント」の文字通りの置き換えを表しています。
同様に、多くの絵文字は感情に関連した表現に関連付けられていますが、感情は微妙で多面的なものであり、多くの場合、1つの絵文字では感情の複雑さを完全に表現することはできません。さらに、絵文字は感情以外の様々な表現を捉えています。これらの理由から、私たちは感情(emotions)ではなく表現(expressions)として考えています。
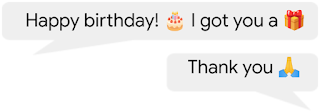
このようなデータは、表現力豊かな会話エージェントの構築や、文脈に応じた絵文字の提案などに有用であり、特に今後の課題として注目されています。
結論
GoEmotionsデータセットは、細かい感情予測のための大規模な、手動で注釈付けされたデータセットを提供しています。私達の分析により、注釈付けの信頼性と、Redditのコメントで表現された感情の高いカバー率が実証されました。GoEmotionsが言語ベースの感情研究者にとって貴重なリソースとなり、実務者が幅広いユーザーの感情に対応した創造的な感情駆動型アプリケーションを構築できるようになることを期待しています。
謝辞
本投稿では、Dora Demszky(Googleでのインターン時代)、Dana Alon(以前はMovshovitz-Attias)、Jeongwoo Ko、Alan Cowen、Gaurav Nemade、Sujith Raviによる研究を紹介しています。Peter Youngには、インフラおよびオープンソースの貢献に感謝します。この研究プロジェクトをサポートしてくださったErik Vee、Ravi Kumar、Andrew Tomkins、Patrick Mcgregor、Learn2Compressチームに感謝します。
3.GoEmotions:きめ細かい感情分類を行うためのデータセット(2/2)関連リンク
1)ai.googleblog.com
GoEmotions: A Dataset for Fine-Grained Emotion Classification
2)arxiv.org
GoEmotions: A Dataset of Fine-Grained Emotions
3)github.com
google-research/goemotions/

