
1.スプレッドシート内で使用される数式を周辺セルから予測
・Google スプレッドシートの数式は便利だが初心者は間違いをしやすい
・目標セル周辺の豊富な文脈情報に基づいて数式を自動生成するモデルを開発
・このモデルは既にユーザーが一般的に利用できるようになっている
2.Google Spreadシートの数式提案機能を実現するAI
以下、ai.googleblog.comより「Predicting Spreadsheet Formulas from Semi-structured Contexts」の意訳です。元記事の投稿は2021年10月20日、Rishabh SinghさんとMax Linさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by ThisisEngineering RAEng on Unsplash
何億人もの人々がスプレッドシートを使用しており、それらのスプレッドシートの数式を使用すると、ユーザーはデータに対して高度な分析と変換を実行できます。
数式言語(formula languages)は汎用プログラミング言語よりも単純ですが、これらの数式を作成することは、特にエンドユーザーにとって、面倒でエラーになりやすい可能性があります。スプレッドシート内のデータパターンを理解して列の欠落値を自動的に埋めるツールを以前に開発しましたが、数式を作成するプロセスをサポートするようには構築されていません。
ICML 2021で公開された「SpreadsheetCoder: Formula Prediction from Semi-structured Context」では、目標となるセル周辺の豊富な文脈情報に基づいて数式を自動的に生成することを学習する新しいモデルについて説明します。
ユーザーが目標セルに「=」記号が先頭に付いた数式を書き始めると、システムは、スプレッドシートの更新履歴から数式のパターンを学習することにより、そのセルに関連する可能性のある数式を生成します。
モデルは、ターゲットセルの隣接する行と列、およびヘッダー行に存在するデータを文脈情報として使用します。これは、最初に隣接セルとヘッダーセルで構成されるスプレッドシートテーブルのコンテキスト構造をembedding 化する事によって行われ、次にこのembedding化された文脈情報を使用して目的のスプレッドシート数式を生成します。
数式は2つのコンポーネントとして生成されます。
(1)演算子の並び(SUM, IFなど)
(2)演算子が適用されるセル範囲(「A2:A10」など)
このモデルに基づく機能は、Googleスプレッドシートのユーザーが一般的に利用できるようになりました。
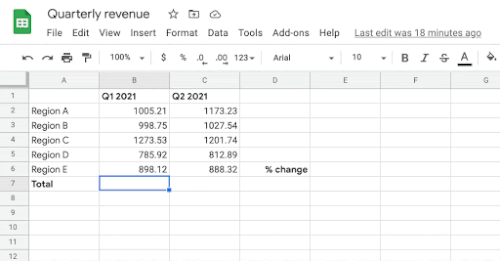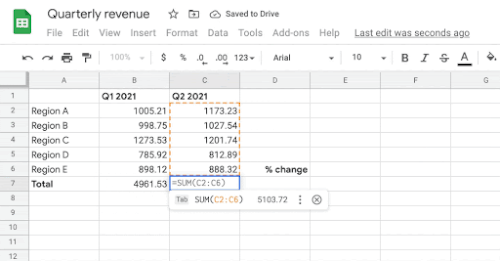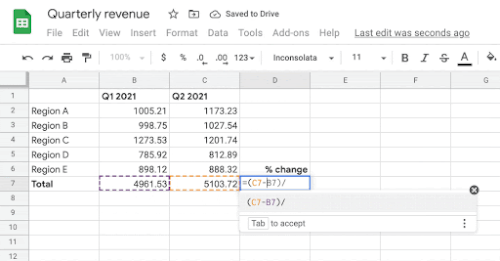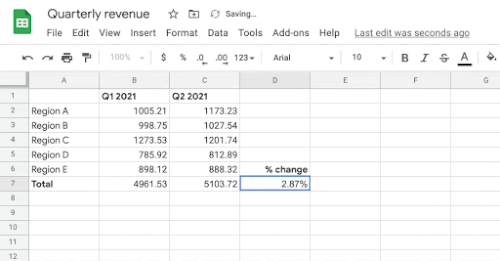
セルB7、C7、およびD7に数式を入力するユーザーの意図を前提として、システムは、ユーザーがこれらのセルに書き込みたいと思う可能性が最も高い数式を自動的に推測します。
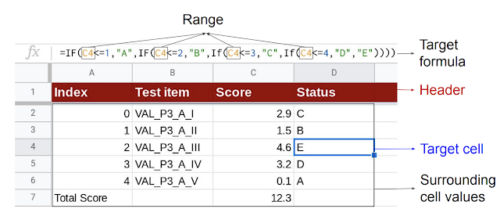
ターゲットセル(D4)が与えられると、モデルはヘッダーと周囲のセル値を文脈情報として使用して、対応する一連の演算子と範囲で構成されるターゲット数式を生成します。
モデルのアーキテクチャ
このモデルは、エンコーダー・デコーダー構造(encoder-decoder architecture)を使用します。この構造では、エンコーダーに複数のタイプの文脈情報(隣接する行、列、ヘッダーなどに含まれる情報など)を柔軟に埋め込むことができ、これを使用して、デコーダーは目的の式を生成できます。
表形式の文脈情報のembeddingを計算するために、最初にBERTベースのアーキテクチャを使用して、ターゲットセルの上下のいくつかの行を(ヘッダー行とともに)エンコードします。
各セルのコンテンツには、そのデータ型(数値型、文字列型など)とその値が含まれ、同じ行に存在するセルのコンテンツは、BERTエンコーダーを使用してembedding化されるトークンシーケンスに連結されます。
同様に、ターゲットセルの左側と右側にいくつかの列をエンコードします。最後に、2つのBERTエンコーダーで行方向と列方向の畳み込みを実行して、コンテキストの集約表現を計算します。
デコーダーは、LSTM(long short-term memory)アーキテクチャーを使用して、最初に数式の概略(範囲のない数式演算子で構成される)を予測し、トークンのシーケンスとして目的のターゲット数式を生成します。
次に、ターゲットセルに関連するセルアドレスを使用して、対応する範囲を生成します。さらに、Attentionメカニズムを活用して、予測を行う前にLSTM出力レイヤーに連結されたヘッダーおよびセルデータのAttentionベクトルを計算します。
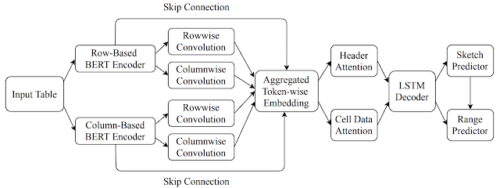
数式予測モデルの全体的なアーキテクチャ
モデルは、隣接する行と列に存在するデータに加えて、ヘッダーなどの高レベルのシート構造からの追加情報も活用します。モデル予測にTPUを使用することで、数式の提案を生成する際の待ち時間を短縮し、より少ないマシンでより多くのリクエストを処理できるようになります。
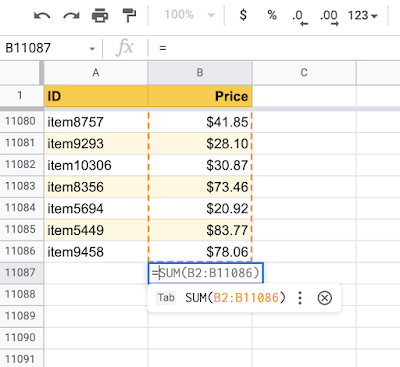
モデルは、高レベルのスプレッドシート構造を活用して、数千行にまたがる範囲を学習できます。
結果
本ホワイトペーパーでは、Google社員が作成して共有したスプレッドシートを学習用データとしてモデルをトレーニングしました。
数式を含む46,000のGoogleスプレッドシートを、トレーニング用に42,000、検証用に23,000、テスト用に17,000に分割しました。このモデルは、完全な数式では42.5%のtop-1精度と数式の概略では57.4%のtop-1精度を達成し、これらは両方とも、最初のユーザー調査で実際に役立つのに十分高いことがわかりました。
アブレーション調査を実行しました。この調査では、モデルを構成するさまざまな部品を削除してモデルのいくつかの簡略化版をテストし、行ベースおよび列ベースの文脈情報をembeddingとして使用する事とヘッダー情報を使用することが、モデルのパフォーマンスを向上させるために重要であることがわかりました。
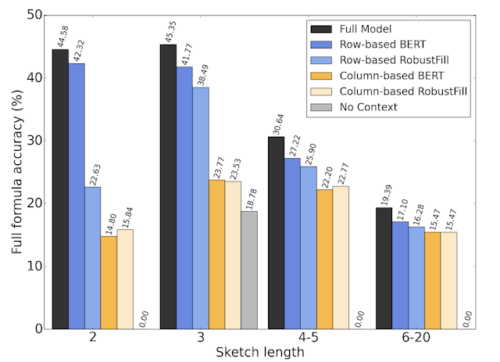
様々なモデルの構成要素を削除するとターゲットとなる数式の長さが増加するにつれてパフォーマンスがどうなるか調査した結果
結論
私たちのモデルは、数式の予測を容易にするために、スプレッドシート内の表データの2次元構造を、テーブルヘッダーなどの高レベルの構造情報とともに特徴表現として学習することの利点を示しています。
より多くの表形式の構造を組み込むための新しいモデルアーキテクチャの設計と、スプレッドシートでのバグ検出や自動チャート作成などのより多くのアプリケーションをサポートするためのモデルの拡張の両方に関して、いくつかの刺激的な研究の方向性があります。
また、ユーザーがこの機能をどのように使用するかを確認し、将来の改善のためにフィードバックから学ぶことを楽しみにしています。
謝辞
Alexander Burmistrov, Xinyun Chen, Hanjun Dai, Prashant Khurana, Petros Maniatis, Rahul Srinivasan, Charles Sutton, Amanuel Taddesse, Peilun Zhang, Denny Zhouを含む、他のチームメンバーの重要な貢献に感謝します。
3.スプレッドシート内で使用される数式を周辺セルから予測関連リンク
1)ai.googleblog.com
Predicting Spreadsheet Formulas from Semi-structured Contexts
2)proceedings.mlr.press
SpreadsheetCoder: Formula Prediction from Semi-structured Context

