
1.Pathdreamer:馴染のない建物内で何処に何がありそうか予測するAI(2/2)まとめ
・Pathdreamerはベースラインと比較して成功率を10%高くする事ができる
・現実世界を実際に移動するエージェントより成功率は低いが時間とリソースを節約可能
・複雑で具体的なナビゲーションタスクに世界モデルを使用する事が有望である可能性を示せた
2.Pathdreamerの性能
以下、ai.googleblog.comより「Pathdreamer: A World Model for Indoor Navigation」の意訳です。元記事の投稿は2021年9月22日、Jing Yu KohさんとPeter Andersonさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Andrew Teoh on Unsplash
ガイダンス画像をもっともらしい現実的な出力に変換するために、Pathdreamerは2段階で動作します。
最初の段階である構造ジェネレーターはセグメンテーションと深度画像を作成し、2番目の段階である画像ジェネレーターはこれらをRGB出力にレンダリングします。
概念的には、最初の段階は風景のもっともらしい高レベルのセマンティック表現を提供し、2番目のステージはこれをリアルなカラー画像にレンダリングします。どちらの段階も畳み込みニューラルネットワークに基づいています。
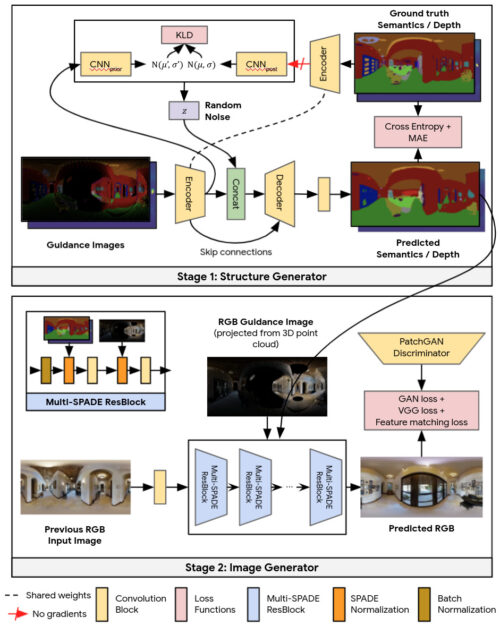
Pathdreamerは2段階で動作します。最初の段階である構造ジェネレーターはセグメンテーションと深度の画像を作成し、2番目の段階である画像ジェネレーターはこれらをRGB出力にレンダリングします。構造ジェネレーターは、モデルが不確実性の高い領域で多様な風景を合成できるように、ノイズ変数を条件としています。
多様な生成結果
角を曲がったところや見えない部屋など、不確実性の高い領域では、さまざまな風景が可能です。確率的ビデオ生成からのアイデアを取り入れて、Pathdreamerの構造ジェネレーターは、ガイダンス画像に捕捉されていない次の場所に関する確率的情報を表すノイズ変数(noise variable)を条件とします。
Pathdreamerは、複数のノイズ変数をサンプリングすることで、さまざまな風景を合成し、エージェントが特定の軌道に対して複数のもっともらしい結果をサンプリングできるようにします。これらの多様な出力は、第1段階の出力(セマンティックセグメンテーションと深度画像)だけでなく、生成されたRGB画像にも反映されます。
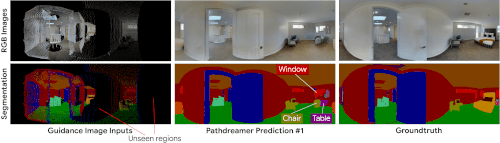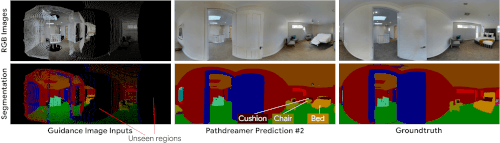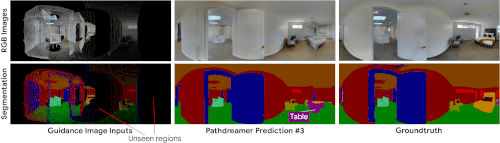
Pathdreamerは、不確実性の高い領域に対して、複数の多様でもっともらしい画像を生成できます。左端の列のガイダンス画像は、エージェントが以前に見た画素を表しています。黒い画素部分は、Pathdreamerが複数のランダムノイズベクトルをサンプリングすることによって多様な出力をレンダリングする、以前に見た事がない領域を表します。実際には、生成された出力は、エージェントが環境をナビゲートするときに、新しい観測によって通知されます。
Pathdreamerは、Matterport3Dの画像と3D環境の再構築でトレーニングされており、リアルな画像と連続したビデオシーケンスを合成することができます。出力画像は高解像度で360度であるため、既存のナビゲーションエージェントが任意のカメラ視野で使用できるように簡単に変換できます。詳細およびPathdreamerを自分で試すには、オープンソースとしてgithubで公開されているコードを確認することをお勧めします。
視覚的なナビゲーションタスクへの適用
視覚的な世界モデルとして、Pathdreamerは下流タスクのパフォーマンスを向上させる強力な可能性を示しています。これを実証するために、PathdreamerをVision-and-Language Navigation(VLN)タスクに適用します。このタスクでは、具現化されたエージェントが自然言語の指示に従って、現実的な3D環境の場所に移動する必要があります。
私たちは、Room-to-Room(R2R)データセットを使用して、事前計画の有用性を確かめる実験を行いました。
実験では命令に従うエージェントは環境内で実行可能な多くのナビゲート可能な軌道をシミュレートします。そして、ナビゲーション命令に対してそれぞれの軌道をランク付けし、実行するのに最適なランク付けされた軌道を選択します。
3つの設定で実験を行いました。
Ground-Truth設定では、エージェントは実際の環境と対話することによって、つまり実際に移動することによって計画を立てます。
ベースライン設定では、エージェントは、建物内のナビゲート可能なルートをエンコードするナビゲーショングラフを操作することにより、移動せずに事前に計画を立てますが、視覚的な観察は提供しません。
Pathdreamer設定では、エージェントはナビゲーショングラフを操作することで移動せずに事前に計画を立て、Pathdreamerによって生成された対応する視覚的観測も受け取ります。
3つのステップ(約6m)を事前に計画すると、Pathdreamer設定でVLNエージェントは50.4%のナビゲーション成功率を達成し、Pathdreamerなしのベースライン設定での40.6%の成功率よりも大幅に高くなります。
これは、Pathdreamerが実際の屋内環境に関する有用でアクセス可能な視覚的、空間的、および意味的知識をエンコードしていることを示唆しています。完璧な世界モデルのパフォーマンスを示す上限として、Ground-Truth設定(実際の移動による計画)では、エージェントの成功率は59%に達しますが、この設定では、エージェントが物理的に多くの軌道を探索するためにかなりの時間とリソースを費やす必要があることに注意してください。
これは、現実世界で行うと法外なコストがかかる可能性があります。
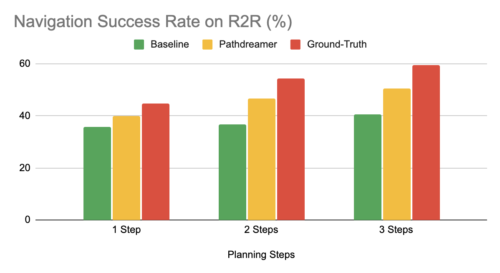
Room-to-Room(R2R)データセットを使用して、指示に従うエージェントのいくつかの計画設定を評価します。Pathdreamer(Pathdreamer setting)によって合成された対応する視覚的観測を備えたナビゲーショングラフを使用して事前に計画することは、ナビゲーショングラフのみ(Baseline setting)を使用して事前に計画するよりも効果的であり、完全に現実と一致する世界モデルを使用して事前に計画する(Ground-Truth setting)とベースライン設定の差の約半分の利点を獲得します。
結論と今後の作業
これらの結果は、複雑で具体的なナビゲーションタスクにPathdreamerなどの世界モデルを使用する事が有望である可能性を示しています。Pathdreamerが、指定された物体やVLNタスクのナビゲーションなど、具体的なビゲーションタスクに挑戦するためのモデルベースのアプローチの障壁を解除するのに役立つことを願っています。
PathdreamerをObject-Navタスク、continuous VLNタスク、ストリートレベルのナビゲーションなどの他の具体的なナビゲーションタスクに適用することは、将来の研究の自然な方向性です。また、Pathdreamerモデルのアーキテクチャとモデリングの方向性の改善に関するさらなる調査、および屋外環境を含むがこれに限定されない、より多様なデータセットでのテストも想定しています。Pathdreamerの詳細については、GitHubリポジトリにアクセスしてください。
謝辞
本プロジェクトは、Jason Baldridge, Honglak Lee, Yinfei Yangとの共同研究です。プロジェクト全体を通じてフィードバックを提供してくれたAustin Waters, Noah Snavely, Suhani Vora, Harsh Agrawal, David Ha、他の多くの皆さんに感謝します。また、Google Researchチームからの全般的なサポートにも感謝しています。
最後に、3番目の図のアニメーションを作成してくれたTom Smallに感謝します。
3.Pathdreamer:馴染のない建物内で何処に何がありそうか予測するAI(2/2)関連リンク
1)ai.googleblog.com
Pathdreamer: A World Model for Indoor Navigation
2)arxiv.org
Pathdreamer: A World Model for Indoor Navigation
3)github.com
google-research / pathdreamer
4)www.youtube.com
Pathdreamer: A World Model for Indoor Navigation (ICCV 2021)

