
1.WIT:ウィキペディアベースの画像-テキストデータセット(2/2)まとめ
・WITは108言語のデータを備えた、初の大規模多言語マルチモーダルデータセット
・WITは文脈情報を提供する初のデータセットで文脈の影響をモデル化するのに役立つ
・WITは多様な概念が幅広くカバーされており挑戦的なベンチマークとして機能
2.WITの特徴
以下、ai.googleblog.comより「Announcing WIT: A Wikipedia-Based Image-Text Dataset」の意訳です。元記事は2021年9月21日、Krishna SrinivasanさんとKarthik Ramanさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Mark Stoop on Unsplash
英語以外の多くの言語に対応
108言語のデータを備えた、WITは、最初の大規模で多言語のマルチモーダルデータセットです。
| # of Image-Text Sets | Unique Languages | # of Images | Unique Languages |
| > 1M | 9 | > 1M | 6 |
| 500K – 1M | 10 | 500K – 1M | 12 |
| 100K – 500K | 36 | 100K – 500K | 35 |
| 50K – 100K | 15 | 50K – 100K | 17 |
| 14K – 50K | 38 | 13K – 50K | 38 |
WIT:多言語にわたるカバー率の統計

12言語超で存在する12超のウィキペディアページに存在する画像の例
ヴォルフガング アマデウス モーツァルトのウィキペディアページより
文脈情報も提供する最初の画像-テキストデータセット
ほとんどのマルチモーダルデータセットは、特定の画像に対して単一の説明文のみ(または似た説明文を複数のバージョンで)提供します。WITは、文脈情報を提供する最初のデータセットであり、研究者が画像の説明文や画像選択に対する文脈の影響をモデル化するのに役立ちます。
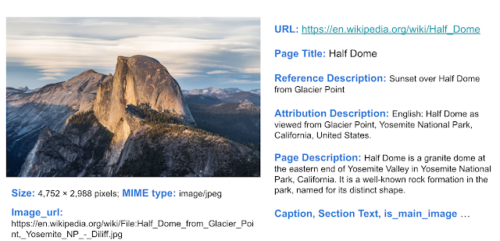
画像-テキストデータと追加の文脈情報を示すWITデータセットの例
特に、研究に役立つ可能性のあるWITの主要な文書項目には次のものがあります。
・テキストによる説明文(Text captions)
WITは、3種類の画像説明文を提供しています。これには、(文脈に影響される可能性のある)「参照元の説明(Reference description)」、(文脈に依存しない可能性が高い)「属性の説明(Attribution description)」および「画像が表示できない際に代わりに表示される説明(Alt-text description)」が含まれます。
・文脈情報
これには、ページタイトル、ページの説明(page description)、URL、およびセクションタイトルとテキストを含むウィキペディアセクションに関するページ内の局所的な情報が含まれます。
以下に示すように、WITはこれらのさまざまな分野にわたって幅広い範囲をカバーしています。
| Image-Text Fields of WIT | Train | Val | Test | Total / Unique |
| Rows / Tuples | 37.1M | 261.8K | 210.7K | 37.6M |
| Unique Images | 11.4M | 58K | 57K | 11.5M |
| Reference Descriptions | 16.9M | 150K | 104K | 17.2M / 16.7M |
| Attribution Descriptions | 34.8M | 193K | 200K | 35.2M / 10.9M |
| Alt-Text | 5.3M | 29K | 29K | 5.4M / 5.3M |
| Context Texts | – | – | – | 119.8M |
WITの主要な項目には、テキストによる説明文と文脈情報の両方が含まれます。
高品質なトレーニングセットと挑戦的な評価ベンチマーク
ウィキペディアの多様な概念が幅広くカバーされているということは、最先端のモデルであっても、WIT評価セットが挑戦的なベンチマークとして機能することを意味します。
画像-テキスト検索の場合、従来のデータセットを使った場合のmean recall scoreは80代でしたが、WITテストセットの場合、データが豊富な言語では40代、データが不足している言語では30代でした。WITが、研究者がより強力でより堅牢なモデルを構築するのに役立つことを願っています。
WITを使ってWikimediaと共催するKaggleの競技会
さらに、Wikimediaリサーチおよび数人の外部の協力者と提携して、WITテストセットを使った競技会を組織していることをお知らせします。このコンテストはKaggleで開催されます。競技会の目的は画像-テキスト検索タスクです。画像とテキストによる説明文のセットが与えられた際、各画像に適切な説明文を選ぶ事を求められます。
この分野での研究を可能にするために、ウィキペディアは、300画素の解像度の画像と、ほとんどのトレーニングおよびテストデータセット用のResnet-50ベースの画像embeddingsを提供してくれました。Kaggleは、WITデータセット自体に加えて、このすべての画像データをホストし、colabノートブックを提供しています。
さらに、競技参加者は、コードを共有して共同作業を行うために、Kaggleのディスカッションフォーラムにアクセスできます。これにより、マルチモダリティに関心のある人なら誰でも簡単に実験を開始して実行できます。 KaggleプラットフォームのWITデータセットとウィキペディアの画像から何が得られるかを楽しみにしています。
結論
WITデータセットは、研究者がより優れたマルチモーダル多言語モデルを構築し、より優れた学習および表現手法を特定するのに役立ち、最終的には、視覚言語データよりも実際のタスクで機械学習モデルを改善できると考えています。
ご不明な点がございましたら、wit-datasetまでメールでお問い合わせください。WITデータセットをどのように使用しているかについてお聞かせください。
謝辞
Google Researchの共著者であるJiecao Chen, Michael BenderskyとMarc Najorkに感謝します。Beer Changpinyo, Corinna Cortes, Joshua Gang, Chao Jia, Ashwin Kakarla, Mike Lee, Zhen Li, Piyush Sharma, Radu Soricut, Ashish Vaswani, Yinfei Yang、およびレビュー担当者の洞察に満ちたフィードバックとコメントに感謝します。
Wikimedia ResearchのMiriam RediとLeila Ziaの競技会の協力、画像画素と画像embeddingsデータを提供してくれたことに感謝します。Kaggleでこのコンテストを開催するのを手伝ってくれたAddison HowardとWalter Readeに感謝します。
また、Diane Larlus(Naver Labs Europe(NLE))、Yannis Kalantidis(NLE)、Stéphane Clinchant(NLE)、EPFLのTiziano Piccardiにも感謝します。サウサンプトン大学のLucie-Aimée KaffeeおよびYacine Jernite(Hugging Face)は、コンペに貴重な貢献をしてくれました。
3.WIT:ウィキペディアベースの画像-テキストデータセット(2/2)関連リンク
1)ai.googleblog.com
Announcing WIT: A Wikipedia-Based Image-Text Dataset
2)dl.acm.org
WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning
3)github.com
google-research-datasets / wit

