
1.Deep-MARC:初めてみる物体をマスクする能力を向上する秘訣(1/2)まとめ
・境界ボックス形式ではなくマスク形式のラベルを作成する際に性能が低下する要因を特定
・一部のみがマスク形式ラベルを持つ部分的教師あり設定でも高パフォーマンスを出せる
・デモモデルは初めて見るクラスでも指定されたボックス内から正確なマスク予測が可能
2.Deep-MACとは?
以下、ai.googleblog.comより「Revisiting Mask-Head Architectures for Novel Class Instance Segmentation」の意訳です。元記事は2021年9月15日、Vighnesh BirodkarさんとJonathan Huangさんによる投稿です。
アイキャッチ画像のクレジットはスタジオジブリの作品静止画集より天空の城ラピュタ。私にとっては何度見たかも覚えていないくらいの名シーンですがDeep-MACにとっては初見と思いますが、どこまで正確に切り出してマスクする事ができるでしょうか?
なお、通常、物体認識モデルは現実世界の画像に対して高い精度を持っていてもイラストやアニメーションに対してはかなり精度が落ちます。それぞれの鳩は?シータは?パズーは?パズーの持ってるトランペットは?正解は後半!
インスタンスセグメンテーションは、画像内の画素を個々のインスタンス(実体)にグループ化し、クラスラベル(人、動物、車などの数える事が可能な物体に、たとえば、car_1とcar_2などの一意の識別子を割り当てます)を使ってそれらを識別するタスクです。
インスタンスセグメンテーションは主要なコンピュータビジョンタスクである自動運転車、ロボット工学、医用画像、写真編集など、多くの下流アプリケーションにとって重要です。
近年、ディープラーニングはMaskR-CNNのようなアーキテクチャでインスタンスセグメンテーションの問題を解決する上で大きな進歩を遂げました。ただし、これらの方法は、巨大なラベル付きインスタンスセグメンテーションデータセットの収集に依存しています。
ただし、Extreme clicking(訳注:境界ボックスを物体ギリギリの矩形で指定してラベル付けするのではなく、四角をクリックして指定する手法)などの方法で1実体あたり7秒で収集できる境界ボックス形式のラベル(bounding box labels)とは異なり、インスタンスセグメンテーションラベル(maskと呼ばれます)の収集には、実体あたり最大80秒かかる可能性があり、コストがかかり、この分野の研究へ参入する際の高い障壁となります。また、関連するタスクであるパノプティックセグメンテーションには、さらに多くのラベル付きデータが必要です。
部分的教師あり(partially supervised)インスタンスセグメンテーション設定では、クラスの一部分のみがインスタンスセグメンテーションマスクでラベル付けされ、残りの大部分のクラスは境界ボックスでのみラベル付けされます。
これは、手動で作成したマスクデータへの依存を減らす可能性があるアプローチです。インスタンスセグメンテーションモデルを開発する際にラベルをマスクする手間を減らし、参入障壁を大幅に下げます。
ただし、この部分的教師ありアプローチでは、トレーニング時に存在しなかった新しいクラスを処理するためにより強力に一般化したモデルが必要になります。例えば、動物のマスクのみを使用してトレーニングし、モデルが建物や植物の正確なインスタンスセグメンテーションを生成する事ができるようにする必要があります。
更に、クラスにとらわれないMask R-CNNをトレーニングするなどのナイーブなアプローチは、マスクラベルを持たない実体のマスク損失を無視するようにしても、うまく機能しませんでした。
たとえば、典型的な「VOC / Non-VOC」ベンチマークでは、COCOの20クラスのサブセット(既知クラス(seen classes)と呼ばれます)のマスクでトレーニングし、残りの60クラス(初見クラス(unseen classes)と呼ばれます)でテストしました。
Resnet-50バックボーンを備えた一般的なMask R-CNNは、初見クラスで最大18%のmask mAP(平均精度、高いほど良い)を達成しますが、完全教師あり設定では、同じクラスではるかに高い34%以上のmask mAPを達成できます。
ICCV 2021で発表される論文「The surprising impact of mask-head architecture on novel class segmentation」では、初見クラスでMaskR-CNNのパフォーマンスが低下する主な原因を特定します。そして、完全教師あり設定とのパフォーマンスギャップを埋めるために連携して機能する2つの実装が容易な修正(トレーニング手順の修正が1つ、マスクヘッドアーキテクチャの修正が1つ)を提案します。
私たちのアプローチは、原則として「切り抜いてからセグメント化するモデル(crop-then-segment models)」として適用されることを示します。つまり、画像全体の特徴を計算し、その後、実体毎に切り抜く範囲を次段階のmask予測ネットワーク(マスクヘッドネットワーク(mask-head network)と呼ばれます)に渡す、mask R-CNNまたは mask R-CNN的なアーキテクチャです。
これらの調査結果をまとめると、以前の研究の際で提案された「より複雑な補助損失関数」、「オフラインの事前トレーニング」、または「重み伝達関数」を必要とせずに、現在の最先端のmask mAPスコアを大幅に(4.7%)改善するMaskR-CNNベースのモデルを提案します。
また、Deep-MACとDeep-MARCと呼ばれるモデルの2つのバージョンのコードベースをオープンソース化し、以下のビデオデモのようなmaskをインタラクティブに作成するColabを公開しました。
デモモデルであるDeepMACは、トレーニング時に存在しなかった初めて見るクラスでも、ユーザーが指定したボックスから正確なマスクを予測することを学習します。githubに登録してあるColabでご自分で試してみてください。画像クレジット:Chris Briggs、Wikipedia、Europeana
部分的教師設定で実体部分を画像から切り抜く事の影響
切り抜いてからセグメント化するモデル(crop-then-segment models)における重要なステップは切り抜きです。
mask R-CNNは、特徴マップと検証済みマスク(ground truth mask)を各実体に対応する境界ボックスから切り抜く事によってトレーニングされます。
これらの切り抜かれた特徴は、最終的なマスク予測を計算する別のニューラルネットワーク(マスクヘッドネットワークと(mask-head network)呼ばれます)に渡され、マスク損失関数を使って検証済みマスクと比較されます。
切り抜きの際には2つの選択肢があります。
(1)実体の周辺を囲む検証済み境界ボックス(ground truth bounding box of an instance)から直接切り抜く
(2)モデルによって予測された境界ボックスから切り抜く(proposals(提案)と呼ばれます)
テスト時には、検証済み境界ボックスが利用可能であるとは想定されていないため、切り抜きは常にproposalsを使って実行されます。
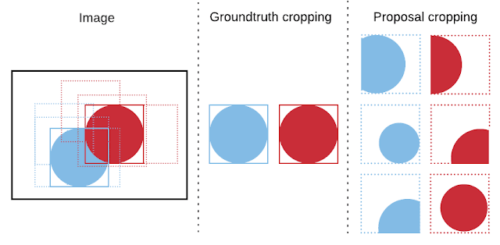
検証済み境界ボックスからの切り抜きと、トレーニング中にモデルによって予測されたproposalsからの切り抜き。標準的なmask R-CNNの実装では両方のタイプの切り抜きが使用されますが、検証済み境界ボックスのみから切り抜きすると、初見カテゴリで大幅に強力なパフォーマンスが得られることを示しています。
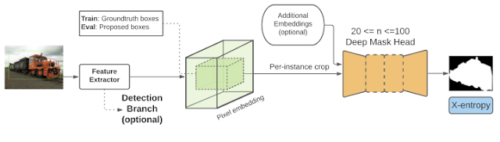
mask R-CNNのようなアーキテクチャの一般的なモデルを検討しますが、通常のmask R-CNNトレーニング設定とは小さいながらも重大な違いがあります。トレーニング時に(proposalsボックスではなく)検証済みボックスを使用して切り抜きます。
3.Deep-MARC:初めてみる物体をマスクする能力を向上する秘訣(1/2)関連リンク
1)ai.googleblog.com
Revisiting Mask-Head Architectures for Novel Class Instance Segmentation
2)arxiv.org
The surprising impact of mask-head architecture on novel class segmentation
3)github.com
Novel class segmentation demo with Deep-MAC
4)www.ghibli.jp
スタジオジブリ作品静止画

