
1.教師あり学習を使って外れ値を発見する(2/3)まとめ
・通常の対照学習は、異常値ではない通常のサンプルの特徴表現が球上に均一に分散される
・1クラス対照学習では支障が出るため分布増強(DA:Distribution Augmentation)を提案
・増強されたデータが空間を占有して通常データが均一に分布する事を回避可能となる
2.二段階フレームワークによる1クラス分類性能の向上
以下、ai.googleblog.comより「Discovering Anomalous Data with Self-Supervised Learning」の意訳です。元記事は2021年9月2日、Chun-Liang LiさんとKihyuk Sohnさんによる投稿です。
2分割しようと思っていましたが3分割に妥協しました。
アイキャッチ画像のクレジットはPhoto by Yan Laurichesse on Unsplash
セマンティックな異常検出
2つの代表的な自己教師特徴表現学習アルゴリズム、回転予測(rotation prediction)と対照学習(contrastive learning)を実験することにより、異常検出のための2段階フレームワークの有効性をテストします。
回転予測とは、入力画像の回転角度を予測するモデルの機能を指します。 他のコンピュータビジョンアプリケーション分野でのその有望なパフォーマンスのために、エンドツーエンドの訓練された回転予測ネットワークは、1クラス分類の研究に広く採用されています。
既存のアプローチは通常、特徴表現を学習するために組み込まれた回転予測分類器を再利用して異常検出を実行します。これらの組み込みの分類器は1クラス分類用にトレーニングされていないため、これは最適ではありません。
対照学習では、モデルは、異なる画像同士の特徴表現を遠ざかるようにしながら、同じ画像の一部を変換したバージョン同士の特徴表現を近くなるようにする事を学習します。
トレーニング中、画像はデータセットから取得され、それぞれが単純な拡張(ランダムな切り抜きや色の変更など)で2回変換されます。
ただし、通常の対照学習は、異常値ではない通常のサンプルの特徴表現は球上に均一に分散されるような解決策に収束します。
ほとんどの1クラスアルゴリズムは、テスト対象のサンプルと通常のトレーニングサンプルの近さをチェックすることによって外れ値か否かを決定するため、これは問題になります。すべての通常のサンプルが空間全体に均一に分布している場合、外れ値であるサンプルも常にいくつかの通常のサンプルの近くに表示されてしまうためです。
これを解決するために、1クラス対照学習のための分布増強(DA:Distribution Augmentation)を提案します。モデルは、トレーニングデータのみから特徴表現を学習するのではなく、トレーニングデータと水増ししたトレーニングサンプルの和集合から学習します。水増ししたサンプルは元のトレーニングデータとは異なったサンプルと見なされます。
分布の増強には、回転操作や水平反転操作などの幾何学的変換を採用しています。DAを使用すると、一部の領域が拡張データで占められているため、トレーニングデータが表現空間に均一に分散されなくなります。
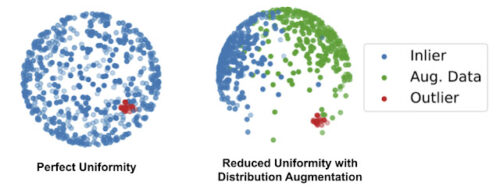
左:標準的な対照学習から導かれる完全均一性の図解
右:提案された分布増強(DA)による均一性の低下。増強されたデータが空間を占有して、球全体にわたって元の通常データ(青)が均一に分布する事を回避します。
CIFAR10とCIFAR-100、Fashion MNIST、Cat vs Dogなど、コンピュータービジョンで一般的に使用されるデータセットのAUC(area under receiver operating characteristic curve)の下の領域の観点から、1クラス分類のパフォーマンスを評価します。
1つのクラスの画像が通常値(inliers)として示され、残りのクラスの画像は外れ値(outliers)として示されます。例えば、犬の画像が通常値である場合、猫の画像が外れ値としてどの程度検出されるかがわかります。
| CIFAR-10 | CIFAR-100 | f-MNIST | Cat v.s. Dog | |
| Ruff et al. (2018) | 64.8 | – | – | – |
| Golan and El-Yaniv (2018) | 86 | 78.7 | 93.5 | 88.8 |
| Bergman and Hoshen (2020) | 88.2 | – | 94.1 | – |
| Hendrycks et al. (2019) | 90.1 | – | – | – |
| Huang et al. (2019) | 86.6 | 78.8 | 93.9 | – |
| 2-stage framework: rotation prediction | 91.3±0.3 | 84.1±0.6 | 95.8±0.3 | 86.4±0.6 |
| 2-stage framework: contrastive (DA) | 92.5±0.6 | 86.5±0.7 | 94.8±0.3 | 89.6±0.5 |
1クラス分類法の性能比較
値は、5回の実行における平均AUCとその標準偏差です。AUCの範囲は0~100で、100が完全な検出です。
回転予測アプローチに通常使用される組み込みの回転予測分類器が最適解ではない事を考慮すると、提案されたフレームワークの第2段階で、特徴表現を学習するために第1段階で使用された組み込みの回転分類器を1クラスの分類器に置き換えるだけで、パフォーマンスが86から91.3AUCに大幅に向上することは注目に値します。 より一般的には、2段階フレームワークは、上記のすべてのベンチマークで最先端のパフォーマンスを実現します。
通常のサンプルの特徴表現の領域境界を学習する従来のOC-SVMを使用すると、2段階のフレームワークにより、画像レベルのAUCで測定した既存の作業よりも高いパフォーマンスが得られます。
3.教師あり学習を使って外れ値を発見する(2/3)関連リンク
1)ai.googleblog.com
Discovering Anomalous Data with Self-Supervised Learning
2)arxiv.org
Learning and Evaluating Representations for Deep One-class Classification
CutPaste: Self-Supervised Learning for Anomaly Detection and Localization
Self-Trained One-class Classification for Unsupervised Anomaly Detection
3)github.com
google-research / deep_representation_one_class
