
1.Agile Data Labeling:それが何であり、なぜそれが必要なのか?(1/3)まとめ
・変化への対応を是とするアジャイル型開発手法はソフトウェア開発に生産性革命をもたらした
・MLプロジェクトにとってデータ整備は重要だが生産性や効率の向上を念頭においた動きはない
・データ整備にアジャイル型開発の概念を取り入れて生産性向上を図る事ができないだろうか?
2.アジャイル型開発とラベル付け作業
以下、www.kdnuggets.comより「Agile Data Labeling: What it is and why you need it」の意訳です。元記事は2021年8月、Jennifer Prendkiさんによる投稿です。
元記事は一瞬だけMost Sharedランキングに入ってましたが、そのランクを維持する事はできず、やはりデータ整備系の記事は重要とは言われていても大きく注目を集める事はないのだなぁ、と実感する出来事でした。
アイキャッチ画像のクレジットはPhoto by Daria Nepriakhina on Unsplash
ソフトウェア開発におけるアジャイル(Agile)の概念は、生産性革命としてIT業界全体に大波を起こしました。アジャイルの概念は機械学習のためにデータセットにラベル付けするという、しばしば困難なタスクに同じ利点を適用できるでしょうか?
アジャイルの概念は確かにテクノロジー業界で人気のあるものですが、データのラベル付けを自然に思い起こす概念ではありません。そして、その理由を理解するのはかなり簡単です。「アジャイル」を取り入れると、通常、効率が高まるのです。しかしながら、機械学習業界で、ラベル付け作業の大変さは不満以外の観点から議論される事はほとんどありません。
アジャイルソフトウェア開発宣言
私たちは、ソフトウェア開発の実践
あるいは実践を手助けをする活動を通じて、
よりよい開発方法を見つけだそうとしている。
この活動を通して、私たちは以下の価値に至った。
プロセスやツールよりも個人と対話を、
包括的なドキュメントよりも動くソフトウェアを、
契約交渉よりも顧客との協調を、
計画に従うことよりも変化への対応を、
価値とする。すなわち、左記のことがらに価値があることを
認めながらも、私たちは右記のことがらにより価値をおく。
(agilemanifesto.orgより引用)
アジャイルマニフェストは、ソフトウェア開発者がそれらをより生産的にすると信じている一連の「ルール」について説明しています。
アジャイルがどのように広く採用されるようになったのかを理解するには、その起源に戻る必要があります。
2001年、17人のソフトウェアエンジニアのグループがユタ州のリゾート地に集まり、業界をより良くする方法についてブレインストーミングを行いました。彼らは、プロジェクトの管理方法が不適切で非効率的であり、過度に規制されていると考えていました。そこで、彼らは前述のアジャイルマニフェストを考案しました。
これは、ソフトウェアエンジニアリングチームのスループット(および健全性のレベル!)を向上させることができると考えた一連のガイドラインです。 アジャイルマニフェストは、進歩を妨げていたプロセスの欠如に対する抗議でした。 そして多くの点で、これはまさにデータのラベル付けに必要なものです。
そこで、彼らは上記のアジャイルマニフェストを考案しました。これは、ソフトウェアエンジニアリングチームのスループット(および健全性のレベル!(level of sanity))を向上させることができると考えた一連のガイドラインです。アジャイルマニフェストは、進歩を妨げていた「プロセスの欠如」に対する抗議でした。そして多くの点で、これはまさにデータのラベル付けに必要なものです。
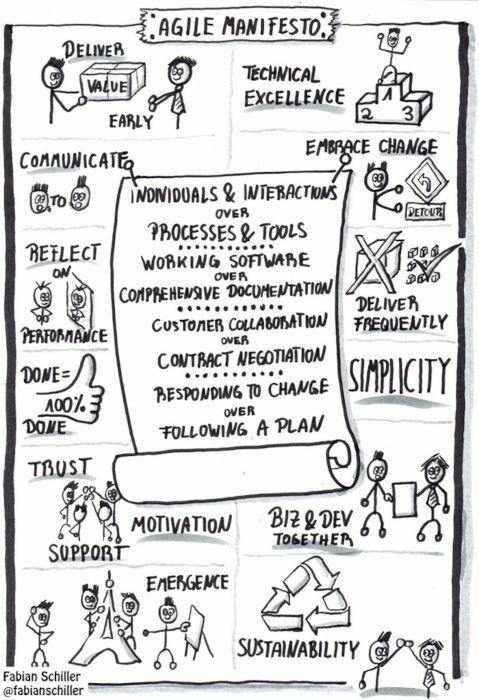
アジャイルマニフェストとそのコア原則について深く掘り下げた図
機械学習に戻りましょう。
過去数十年にわたってこの分野で達成された進歩は、単に気が遠くなるようなものです。これについては疑いがありません。実際、ほとんどの専門家は、テクノロジーの進化が速すぎて、法律や機関が追いつけないことに同意しています。
(確信が持てませんか?偽物動画を簡単に作り出せるDeepFakesが世界平和にもたらす可能性のある悲惨な結果について考えてみてください)
しかしながら、新規AI製品の爆発的な増加にもかかわらず、MLプロジェクトが成功するか否かは1つに帰着します。それはデータです。データを収集、保存、検証、クリーンアップ、または処理する手段がない場合、MLモデルは永遠に遠い夢のままです。世界で最も権威のあるML企業の1つであるOpenAIでさえ、研究者に必要なデータを取得する手段がないと判断した後、部門の1つ(訳注:robotics teamが今年7月にデータ不足を理由に解散されています)を閉鎖することを決定しました。
そして、使用するオープンソースデータセットを見つけることだけが必要だと思う場合は、もう一度考えてみてください。関連するオープンソースデータがほとんど存在しない事例だけではありません。これらのデータセットのほとんども驚くほど誤用されており、製品としてそれらを使用することは無責任に他なりません。
当然のことながら、これまで以上に優れた手頃な価格のハードウェアがあれば、独自のデータセットを収集することはもはやそれほど問題にはなりません。ただし、主要な問題は、注釈を付ける必要があるため、これらのデータをそのまま使用することはできないということです。見た目にもかかわらず、それは簡単な作業ではありません。

物体検出または物体セグメンテーションの学習に使用するためにこの画像のすべての物体に注釈を付けるとしたら、熟練した専門家であっても1時間以上かかる可能性があります。50,000枚の画像に対して同様の作業を行う必要があり、他からの支援なしに注釈の品質を保証する必要を求められた場合を想像してみてください。
3.Agile Data Labeling:それが何であり、なぜそれが必要なのか?(1/3)関連リンク
1)www.kdnuggets.com
Agile Data Labeling: What it is and why you need it
2)agilemanifesto.org
アジャイルソフトウェア開発宣言

