
1.C4_200M:文法エラー訂正用の合成データセット(2/2)まとめ
・タグ付き破損モデルは再現したいエラーの種類をエラータイプタグで入力できる
・そのため現実世界で実際に見られる書き込みエラーの分布を再現する事ができる
・英語を母国語とする人としない人がやる文法エラーは異なるため習熟度調整も可能
2.タグ付き破損モデルとは?
以下、ai.googleblog.comから「The C4_200M Synthetic Dataset for Grammatical Error Correction」の意訳です。元記事の投稿は2021年8月10日、Felix StahlbergさんとShankar Kumarさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Brett Jordan on Unsplash
私たちが提案するタグ付き破損モデルは、このアイデアに基づいており、クリーンな文と共にエラータイプタグ(error type tag)を入力として受け取ります。エラータイプタグは、再現したいエラーの種類を説明します。
そして、指定されたエラータイプを含む文法的に誤ったバージョンの入力文を生成します。異なる文章に対して異なるエラータイプを選択すると、従来の破損モデルと比較して、破損の多様性が高まります。
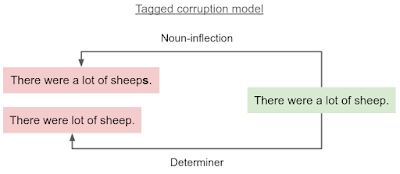
タグ付き破損モデルは、エラータイプタグに応じて、クリーンな入力文(緑)の破損した文(赤)を生成します。限定詞エラー(determiner error)は「a」を削除する可能性があり、名詞の語尾変化エラー(noun-inflection error)は誤った複数形「sheeps」を生成する可能性があります。
このモデルをデータ生成に使用するために、最初にC4コーパスから2億のクリーンな文をランダムに選択しました。次に各センテンスにエラータイプタグを割り当てました。各エラーの頻度は小規模な開発データセットであるBEA-devのエラー出現頻度に相対に合わせています。
BEA-devは、さまざまな英語能力レベルをカバーするために慎重に収集されたデータセットであるため、そのエラー分布は、現実世界で実際に見られる書き込みエラーの頻度を再現している事が期待できます。次に、タグ付き破損モデル(tagged corruption model)を使用して、修正元センテンスを合成しました。
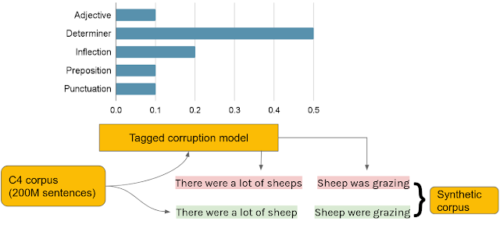
タグ付き破損モデルを使用した合成データの生成
C4から選択したクリーンな文(緑)は、合成GECトレーニングコーパスの破損した文(赤)とペアになっています。破損した文は、開発セット(棒グラフ)のエラータイプの頻度に従って、タグ付き破損モデルを使用して生成されています。
結果
私たちの実験では、タグ付き破損モデルは、2つの標準的な開発セット(CoNLL-13とBEA-dev)のタグなし破損モデルよりthree F0.5-points(適合率と再現率でより適合率を重視したGEC研究の標準指標)優れており、広く使用されている2つの学術テストセットであるCoNLL-14とBEAテストセットで最先端のスコアを更新します。
更に、タグ付き破損モデルを使用すると、標準のGECテストセットで向上が得られるだけでなく、GECシステムをユーザーの習熟度レベルに適合させることもできます。これは、たとえば、英語を母国語とする作家のエラータグの分布が、英語を母国語としない人の分布とは大幅に異なる場合が多いため、役立つ可能性があります。たとえば、ネイティブスピーカーは句読点やスペルの間違いを多くする傾向がありますが、限定詞のエラー(たとえば、「a」、「an」、「the」などが欠落した記事や余分な記事)は、ネイティブでないライターが書いたテキストでより一般的です。
結論
ニューラルシーケンスモデルはデータを大量に消費することで有名ですが、文法エラー訂正のための注釈付きトレーニングデータが利用できることは稀です。新しいC4_200Mコーパスは、さまざまな文法エラーを含む合成データセットであり、GECシステムの事前トレーニングに使用すると最先端のパフォーマンスが得られます。データセットをリリースすることにより、GECの研究者に強力なベースラインシステムをトレーニングするための貴重なリソースを提供したいと考えています。
3.C4_200M:文法エラー訂正用の合成データセット(2/2)関連リンク
1)ai.googleblog.com
The C4_200M Synthetic Dataset for Grammatical Error Correction
2)aclanthology.org
Synthetic Data Generation for Grammatical Error Correction with Tagged Corruption Models
3)github.com
google-research-datasets / C4_200M-synthetic-dataset-for-grammatical-error-correction

