1.KYD:データセット探索用の新ツール(2/2)まとめ
・画像説明文内の「男性のまなざし」について調査し従来の研究結果を裏付ける事ができた
・高齢者は現実世界の集団内での存在に比べてデータセット内で過小評価されている事も判明
・KYDを使用してデータセットをよりよく理解し、潜在的なバイアスと公平性の懸念を軽減可能
2.Know Your Dataの使用例
以下、ai.googleblog.comより「A Dataset Exploration Case Study with Know Your Data」の意訳です。元記事の投稿は2021年8月9日、Mark DíazさんとEmily Dentonさんによる投稿です。
バイアスに関するお話を読んでwebbigdata.jpで使用させて頂いているアイキャッチ画像は西洋の素材に偏っているので、意識した方が良いのかなぁ、とも思ったのですが、日本のフリー素材は絶対数が少ないので他サイトや広告(特に怪しい広告)と被ってしまうんですよねぇ。
アイキャッチ画像のクレジットはPhoto by Elisabeth Wales on Unsplash
様々な活動で描かれた社会集団に関するバイアスを調べることに加えて、注釈作業者が男性または女性として認識した人々の外見をどのように説明するかについてのバイアスも調査しました。
視覚メディアに埋め込まれた「男性のまなざし(訳注:male gaze、映画などで女性を男性から見た欲望の対象として描く事)」を調べたメディア学者に触発されて、COCOで女性として認識される個人を欲望の対象として位置付ける形容詞を使用して記述される頻度を調べました。
KYDを使用すると、性別のバイナリ表現に関連する単語(「女性(female)/女の子(girl)/女の人(woman)」と「男性(male)/男の人(man)/男の子(boy)」など)と身体的魅力の評価に関連する単語の同時発生を簡単に調べることができました。
重要なのは、これらは人間の注釈作業者によって書かれた説明文です。注釈作業者は、画像内の人々の性別について主観的な評価を行い、魅力の記述子を選択しています。「魅力的(attractive)」、「美しい(beautiful)」、「可愛い(pretty)」、「セクシー(sexy)」という言葉は、男性として認識されている人々と比較して、女性として認識されている人々を表す際に過大評価されていることがわかりました。これは、視覚メディア内で性別がどのように見られているかについて以前の研究が述べていることを裏付けています。
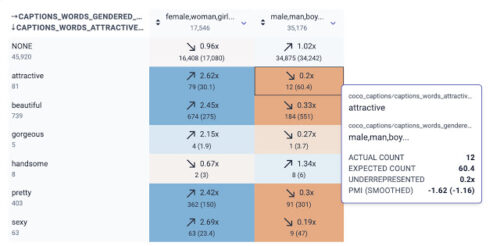
魅力を表す単語と性別の単語の関係を示すKYDのスクリーンショット
例えば、「魅力的(attractive)」と「男性/男の人/男の子」は12回同時に出現しています。
本来ならば60回程度出現するはずです(倍率0.2倍)
しかしながら、「魅力的(attractive)」と「女性/女の人/女の子」は本来の出現回数の2.62倍出現します。
KYDでは、問題の関係(relation)をクリックすることで、各関係の画像を手動で検査することもできます。例えば、説明文内に該当用語(例えば「女性」と「美しい」)が含まれている画像を見ることができます。
年齢バイアスの調査
65歳以上の成人は、現実世界の集団内での存在に比べてデータセット内で過小評価されていることが示されています。年齢表現を改善するための最初のステップは、開発者がデータセットで年齢表現を評価できるようにすることです。KYDは、さまざまな活動を説明する説明文内で使われている単語を調べ、年齢を説明する単語との関係を分析することで、高齢者を描いた説明文の例の範囲を評価するのに役立ちました。
さまざまな環境や活動で成人に対する説明文の事例を用意することは、画像に対する説明文や歩行者検出などのさまざまなタスクにとって重要です。
KYDが明らかにした最初の傾向は、さまざまな活動を詳述する説明文で、注釈作業者が人々を高齢者として説明することはめったにないということです。relationsタブには、システムが検出できるようにするために重要となる可能性のあるさまざまな身体活動を説明する動詞に「高齢者(elderly)」、「古い/年をとった(old)」、「年上の(older)」が発生しない傾向も示されています。
注意すべき重要な点は、「若い(young)」と比較して、「古い(old)」は、持ち物や衣類など、人間以外のものを表すために使用されることが多いため、これらの関係は、人を表さないいくつかの用例も捉えてしまっていることです。
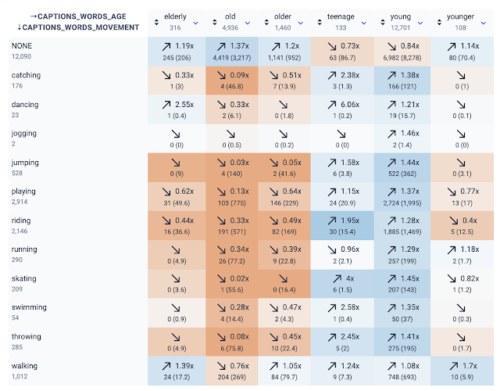
KYDのスクリーンショットからの年齢と活動に関連する単語の関係
ここで調べた高齢者への言及を含む説明文内の過小評価は、高齢者を描いた画像が比較的不足していることと、画像で人々を説明するときに注釈作業者が高齢者に関連する用語を省略している傾向に起因している可能性があります。「古い(old)」と「走っている(running)」が交差する点を手動で検査すると、負の関係が示されますが、高齢者の画像がないことと、乗物の画像数が多いことがわかります。
KYDを使用すると、関係を定量的および定性的に簡単に検査して、データセットの長所と改善すべき領域を特定できます。
結論
MLデータセットの内容を理解することは、不公平なデータセットバイアスの下流タスクへの影響を軽減するための適切な戦略を開発するための重要な最初のステップです。上記の分析は、いくつかの潜在的な緩和策を示しています。たとえば、特定の活動と社会的グループとの相関関係は、訓練されたモデルが社会的ステレオタイプを再現するように導いてしまう可能性があります。これは、「データセットバランシング(dataset balancing)」、つまり、過小評価されたグループ/活動の組み合わせを増やす事で潜在的に軽減される可能性があります。
ただし、注釈作業者によってさまざまな性別がどのように記述されているかを分析した結果、データセット内でバランスを取る事のみに焦点を当てた緩和策では不十分です。画像に描かれている人々に対する注釈作業者の主観的な判断が最終的なデータセットに反映されていることがわかりました。
これは、画像に注釈を付ける作業のやり方をより深く検討する必要があることを示唆しています。画像説明文データセットを開発しているデータ実践者のための1つの解決策は、人種、性別、およびその他のアイデンティティカテゴリに敏感な画像に関する説明を書くためにガイドラインを開発して統合することの検討です。
これらのケーススタディでは、KYD機能の一部のみを取り上げています。たとえば、Cloud Vision APIシグナルもKYDに統合されており、注釈作業者が直接ラベル付けしていないシグナルを推測するために使用できます。より広範なMLコミュニティが、独自のKYDケーススタディを実行し、その結果を共有することをお勧めします。
KYDは、Googleの成長するResponsible AIツールキットなど、MLコミュニティ全体で開発されている他のデータセット分析ツールを補完します。KYDを使用してデータセットをよりよく理解し、潜在的なバイアスと公平性の懸念を軽減するML実践者を楽しみにしています。 KYDに関するフィードバックがある場合は、knowyourdata-feedbackまでメールでご連絡ください。
謝辞
この投稿の分析と記述は、Emily Denton, Mark Díaz, and Alex Hannaの平しい貢献により実施されました。この投稿への貢献とレビューをしてくれたMarie Pellat, Ludovic Peran, Daniel Smilkov, Nikhil Thorat そして Tsung-Yi に感謝します。
3.KYD:データセット探索用の新ツール(2/2)関連リンク
1)ai.googleblog.com
A Dataset Exploration Case Study with Know Your Data
2)knowyourdata.withgoogle.com
Know Your Data
3)www.tensorflow.org
責任ある AI | Responsible AI Toolkit | TensorFlow