
1.アフリカ大陸の多種多様な建物を衛星画像から検出(2/2)まとめ
・精度の向上にはmixupとNoisyStudent、及びガウス畳み込みに基づいた境界明確化が貢献
・地域差はあるがアフリカ大陸に存在する建物の大きさとその数(5億1600万)を抽出できた
・最終的な結果はOpen Buildings Datasetとして利用可能な状態で無料公開されている
2.MixupとNoisyStudentの利用
以下、ai.googleblog.comより「Mapping Africa’s Buildings with Satellite Imagery」の意訳です。元記事の投稿は2021年7月28日、John Quinnさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by angelo moleele on Unsplash
基本モデルを使用した最初の実験では、たとえば建物のような外観を持つさまざまな自然界および人工的な特徴のために、適合率と再現率が低くなりました。
私たちはパフォーマンスを向上させる方法をいくつか見つけました。
1つは、正則化手法としてmixupを使用する事でした。mixupでは、加重平均をとることによってランダムなトレーニング画像を混合して新しいトレーニング画像を合成します。
mixupは元々画像分類のために提案された手法ですが、これをセマンティックセグメンテーションに使用するように変更しました。正則化は、建物のセグメンテーションタスクで一般的に重要です。
これは10万のトレーニング画像を使用しても、トレーニングデータは、モデルがテスト時に提示される地形、大気、および照明条件の完全な変化を捕捉しておらず、したがって過剰適合してしまう傾向があるためです。これは、トレーニング画像のmixupとランダムなデータ水増しによって軽減されます。
効果的であることがわかったもう1つの方法は、教師なし自己学習(unsupervised self-training)の使用でした。アフリカ全土から1億枚の衛星画像のセットを準備し、これらをフィルタリングして、ほとんどが建物を含む870万枚の画像のサブセットにしました。
このデータセットは、NoisyStudent手法を使用した自己トレーニングに使用されました。
Noisy Studentでは、最初にトレーニングされた最良の建物検出モデルの出力が「教師」として使用され、ノイズを使って水増しされた画像から同様に予測を行う「生徒」モデルがトレーニングします。
実際、これにより誤検知が減少し、検出出力が鮮明になることがわかりました。生徒モデルは、建物に対する信頼度を高く出力し、背景に対する信頼度を低く出力しています。
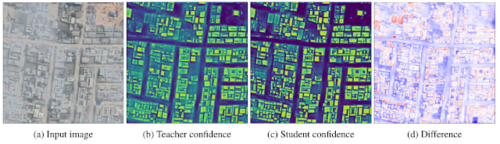
典型的な画像の生徒モデルと教師モデルのモデル出力の違い
パネル(d)で、赤い領域は、学生モデルが教師モデルよりも建物である可能性が高いと判断した領域であり、青い領域は背景である可能性が高い領域です。
最初に直面した問題の1つは、モデルが「ぼろぼろの」検出を作成する傾向があり、境界を明確に描写せず、隣接する建物をいっしょくたにする傾向があることでした。
これに対処するために、元のU-Net論文内の別のアイデアを適用しました。それは、距離加重(distance weighting)を使用して損失関数を適応させ、境界付近で正しい予測を行うことの重要性を強調することです。
トレーニング中、距離加重は、損失に重みを追加することにより、境界をより強調します。特に、ほとんどが接触している実体同士がある場合はそうです。 建物を検出する場合、これにより、モデルが建物間の境目を正しく識別することができます。これは、多くの近接した構造が結合されないようにするために重要です。元のU-Netの距離加重定式化は有用でしたが、計算に時間がかかることがわかりました。そこで、境界部のガウス畳み込みに基づいた代替案を開発しました。これは、より高速でより効果的でした。
論文内には、これらの各手法の詳細が記載されています。
結果
アフリカ大陸全体のいくつかの異なる地域で、都市部、田園地方、中程度の人口密度のさまざまなカテゴリでモデルのパフォーマンスを評価しました。さらに、潜在的な人道的アプリケーションの準備を目的として、避難民と難民居住地のある地域でモデルをテストしました。適合率と再現率は地域によって異なるため、大陸全体で一貫したパフォーマンスを達成することは継続的な課題です。
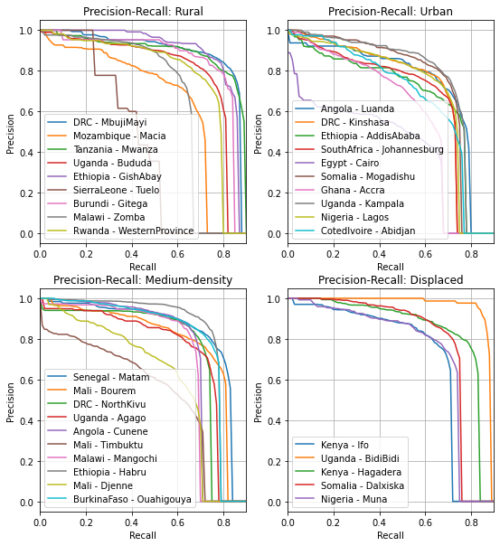
適合率-再現率曲線。
0.5交差IoUのしきい値で測定
スコアが低くなる領域の検出を目視チェックした結果、さまざまな原因に気づきました。農村地域では、ラベル付けの誤りが問題でした。たとえば、ほとんど建物が存在しないエリア内にある唯一の建物は、ラベル付け作業者が見つけるのが難しい場合があります。都市部では、モデルは大きな建物を別々の建物に分割してしまう傾向がありました。このモデルは、建物を背景と区別するのが難しい砂漠エリアの地形でもパフォーマンスが低下していました。
平均精度(mAP:mean average precision)で測定して、どの手法が最終的なパフォーマンスに最も貢献したかを理解するために、アブレーション研究を実施しました。距離加重、mixup、およびImageNet事前トレーニングの使用は、教師あり学習のパフォーマンス向上に貢献している最大の要因でした。これらの手法を使用しなかった切除モデルのmAPの差は、それぞれ-0.33、-0.12、および-0.07でした。教師なし自己トレーニングにより、+0.06mAPがさらに向上しました。
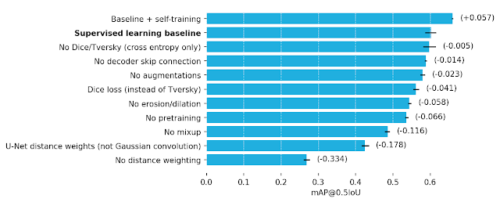
トレーニング手法のアブレーション研究結果
一番上の行は、自己教師学習を組み合わせた最良のモデルのmAPパフォーマンスです。2番目の行は、教師あり学習のみを使用した最良のモデル(比較基準)を示しています。比較基準から各最適化手法を順番に無効化することで、mAPテストのパフォーマンスに各手法が与えている影響を観察します。距離加重(Distance weighting)が最も重要な効果をもたらしていました。
オープンビルディングデータセットの作成
最終的なデータセットを作成するために、アフリカ大陸全体の衛星画像(大陸の64%である1940万km2をカバーする86億枚の画像タイル)に最高の建物検出モデルを適用し、5億1600万の異なる建物を検出しました。
各建物の輪郭は多角形形状として簡略化され、Plus Codeに関連付けられています。Plus Codeは、住所に似た数字と文字で構成される地理識別子であり、正式な住所システムがない地域の建物を識別するのに役立ちます。また、特定の精度レベルを達成するための信頼スコアと推奨しきい値に関するガイダンスも含まれています。
建物のサイズは以下に示すように異なり、面積は小さめな傾向があります。小さな構造物を含めることは、たとえば、非公式の居住地や難民施設の分析をサポートするために重要です。
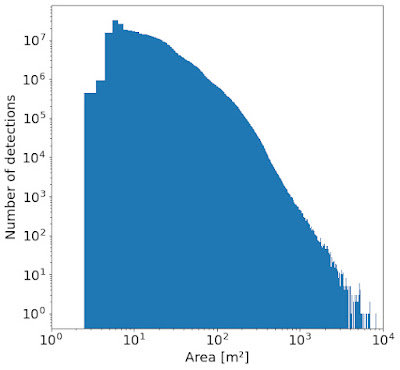
アフリカ大陸の建物の専有面積サイズの分布
このデータは無料で入手できるため、どのように使用されるかを楽しみにしています。将来的には、使用法とフィードバックに応じて、新しい特徴と地域を追加する可能性があります。
謝辞
この作業は、AI for Social Goodの取り組みの一部であり、ガーナのGoogle Researchが主導しました。共同研究者に感謝します。Wojciech Sirko, Sergii Kashubin, Marvin Ritter, Abigail Annkah, Yasser Salah Eddine Bouchareb, Yann Dauphin, Daniel Keysers, Maxim Neumann そして Moustapha Cisse。
調整を手伝ってくれたAbdoulaye Diack, Sean Askay, Ruth Alcantara そして Francisco Moneoに感謝します。Rob Litzke, Brian Shucker, Yan Mayster and Michelina Palloneは、地理的なインフラストラクチャに関して貴重な支援を提供してくれました。
3.アフリカ大陸の多種多様な建物を衛星画像から検出(2/2)まとめ
1)ai.googleblog.com
Mapping Africa’s Buildings with Satellite Imagery
2)arxiv.org
Continental-Scale Building Detection from High Resolution Satellite Imagery
3)sites.research.google
Open Buildings
4)maps.google.com
Plus Codes


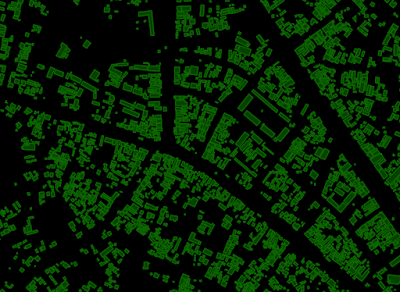
近隣の境目を強調するための距離加重スキーム:U-Net(左)と境界のガウス畳み込み(右)