
1.BERTとTF-Rankingを使ってランキングシステムの透明性と解釈可能性を向上(1/2)まとめ
・ランク付け学習(LTR)は項目のリスト全体を入力として受け取り、有用性を最大化する順序を学習
・LTRは検索および推薦システム、その他eコマースやスマートシティ計画などでも使用されている
・新しいTF-RankingはBERTとLTRを組み合わせるTFR-BERTアーキテクチャを実装している
2.TFR-BERTとは?
以下、ai.googleblog.comより「Advances in TF-Ranking」の意訳です。元記事の投稿は2020年7月27日、Michael BenderskyさんとXuanhui Wangさんによる投稿です。
TF-RankingもGoogle製品の様々なランキング付けに使われているのだろうなと思います。
アイキャッチ画像のクレジットはPhoto by Leslie Jones on Unsplash
TF-Rankingはユーザーが「入力したキーワードの応答として順序付きの項目リストを受け取ることを期待している場面」で役立ちます。
LTRモデルは、一度に1つのアイテムを分類する標準的な分類モデルとは異なり、アイテムのリスト全体を入力として受け取り、リスト全体の有用性を最大化する順序を学習します。
検索システムおよび推薦システムがLTRモデルの最も一般的なアプリケーションですが、リリース以来、TFランキングは、eコマース、SATソルバー(与えられた命題論理式が真になるかどうかを判定するプログラム)、スマートシティ計画など、検索以外のさまざまな領域に適用されています。
ランク付け学習(LTR)の目標は、アイテム(文章、製品、映画など)のリストを入力として受け取り、アイテムのリストを最適な順序(降順)で出力する関数f()を学習することです。アイテムのリストを最適な順序(関連性の降順)で出力します。ここで、緑の陰影はアイテムの関連性レベルを示し、「x」でマークされた赤いアイテムは関連性がありません。
2021年5月に、TF-Rankingのメジャーリリースを公開しました。これにより、TensorFlow2の高レベルAPIであるKerasを使用してLTRモデルをネイティブに構築する事が完全に可能になります。
ネイティブのKerasランキングモデルには、柔軟なModelBuilder、トレーニングデータを設定するためのDataset Builder、提供されたデータセットを使用してモデルをトレーニングするためのパイプラインなど、まったく新しいワークフロー設計があります。
これらのコンポーネントにより、カスタマイズされたLTRモデルの構築がこれまでになく簡単になり、製品開発および研究実験用の新しいモデル構造の迅速な調査が容易になります。もし、あなたがRaggedTensorsを選択している場合、TF-RankingもRaggedTensorsと連携します。
さらに、Orbitトレーニングライブラリを組み込んだ最新のリリースには、2年半のニューラルLTR研究の集大成である多くの改良点が含まれています。以下に、最新版のTF-Rankingで利用可能ないくつかの主要な改善点を示します。
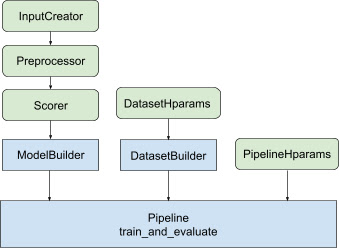
ネイティブのKerasランキングモデルを構築およびトレーニングするためのワークフロー
青いモジュールはTF-Rankingによって提供され、緑のモジュールはカスタマイズ可能です。
TFR-BERTを使用したランク付け学習
近年、BERTのような事前トレーニングされた言語モデルは、さまざまな言語理解タスクで最先端のパフォーマンスを達成しています。これらのモデルの特徴表現力を取り込むために、TF-Rankingは、BERTとLTRの能力を組み合わせてリスト入力の順序を最適化する、新しいTFR-BERTアーキテクチャを実装しています。
例として、入力キーワード(query)と、このクエリに応答してランク付けする可能性のあるn個の文章(document)のリストについて考えてみます。LTRモデルは、<query, document>ペアごとに独立したBERT特徴表現を学習する事はしません。その代わりに、LTRモデルは、ランク付け損失を適用して、真のラベルに基いてランク付けされたリスト全体の有用性を最大化するBERT特徴表現を共同で学習します。
次の図は、このプロセスを示しています。まず、入力キーワードに応答してランク付けするn個の文書のリストをリスト<query, document>の組に平坦化します。これらの組は、事前トレーニングされた言語モデル(BERTなど)に入力されます。
次に、BERTの出力はドキュメント全体で貯蔵され、TFランキングで利用可能な特殊なランキング損失の1つと合同で微調整されます。
私達の経験によると、このTFR-BERTアーキテクチャは、事前トレーニングされた言語モデルのパフォーマンスを大幅に向上させ、特に複数の事前トレーニングされた言語モデルがアンサンブルされている場合に、いくつかの人気のあるランキングタスクで最先端のパフォーマンス実現に至ります。
これにより、ユーザーはこの簡単な例を使用してTFR-BERTを使い始めることができます。
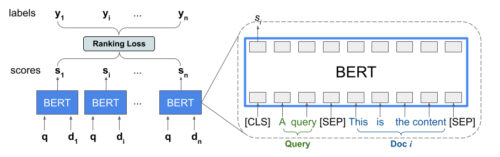
TFR-BERTの概要図
個々の<query、document>ペアのBERT特徴表現を使用して、n個のドキュメントのリストに対する合同LTRモデルを構築します。
3.BERTとTF-Rankingを使ってランキングシステムの透明性と解釈可能性を向上(1/2)まとめ
1)ai.googleblog.com
Advances in TF-Ranking
2)research.google
Are Neural Rankers still Outperformed by Gradient Boosted Decision Trees?
3)github.com
tensorflow / ranking

