
1.拡散モデルを使用してGANより忠実度の高い画像を生成(2/2)まとめ
・CDMはSR3を使って高解像度の自然画像を生成できるクラス条件付き拡散モデル
・複数の拡散モデルを繋ぎ合わせて低解像度から徐々に解像度を上げて高品質画像を生成
・CDMの品質を改善するためコンディショニング拡張と呼ぶ新しいデータ水増し手法も導入
2.S3とCDM
以下、ai.googleblog.comより「High Fidelity Image Generation Using Diffusion Models」の意訳です。元記事の投稿は2021年6月16日、Jonathan HoさんとChitwan Sahariaさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by NASA on Unsplash
CDMを使ったクラス条件付きImageNet生成
自然画像の超解像を実現する際のSR3の有効性を示したので、さらに一歩進んで、これらのSR3モデルをクラス条件付き画像生成に使用します。
CDMは、高解像度の自然画像を生成するためにImageNetデータでトレーニングされたクラス条件付き拡散モデルです。
ImageNetは難しい、高エントロピーのデータセットであるため、複数の拡散モデルのカスケードとしてCDMを構築しました。このカスケードアプローチでは、複数の生成モデルを複数の空間解像度で連鎖させます。1つの拡散モデルが低解像度でデータを生成し、その後、一連のSR3超解像拡散モデルが生成された画像の解像度を徐々に最高の解像度に上げます。
従来の研究(自己回帰モデルやVQ-VAE-2など)や同時期の拡散モデルの研究で示されているように、カスケードによって高解像度データの品質とトレーニング速度が向上することはよく知られています。以下の定量的な結果が示すように、CDMは、拡散モデルにおけるカスケードの有効性をさらに強調し、サンプルの品質と画像分類などの下流工程タスクでの有用性を示します。

拡散モデルを含む一連のカスケードパイプラインの例
最初のモデルは低解像度の画像を生成し、残りは最終的な高解像度の画像へのアップサンプリングを実行します。ここでのパイプラインは、クラス条件付きImageNet生成用であり、32 x 32解像度のクラス条件付き拡散モデルで始まり、SR3を使用した2倍および4倍のクラス条件付き超解像が続きます。

カスケードクラス条件付きImageNetモデルから生成された256 x 256画像の一例
カスケードパイプラインにSR3モデルを含めることに加えて、CDMのサンプル品質結果をさらに改善する、私達がコンディショニング拡張(conditioning augmentation)と呼ぶ新しいデータ水増し手法も導入します。
CDMの超解像モデルは学習はデータセット内の画像を使いますが、生成時はベースモデルによって生成された低解像度画像に対して超解像を実行する必要があります。これらの低解像度画像は、学習時に使った元画像と比較して十分に高品質ではない可能性があります。これにより、超解像モデルに学習時とテスト時の不一致(train-test mismatch)が発生します。
コンディショニング拡張とは、カスケードパイプライン内の各超解像モデルの低解像度入力画像にデータ水増しを適用することを指します。これらの水増し(この場合はガウスノイズとガウスぼかしが含まれます)は、各超解像モデルが低解像度の条件付き入力に過剰適合することを防ぎ、最終的にCDMの高解像度のサンプル品質を向上させます。
全体として、CDMは、クラス条件付きImageNet生成のFIDスコアと分類精度スコアの両方の点でBigGAN-deepおよびVQ-VAE-2よりも優れた忠実度の高いサンプルを生成します。CDMは、ADMやVQ-VAE-2などの他のモデルとは異なり、サンプルの品質を高めるために分類子を使用しない純粋な生成モデルです。サンプル品質の定量結果については、以下を参照してください。
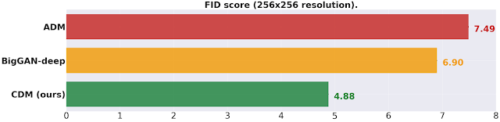
サンプル品質を高めるために追加の分類器を使用しない手法の比較
256×256の解像度でクラス条件付きImageNet FIDスコア
BigGAN-deepは、最良値を切り捨てた値です。(低いほど良いです)
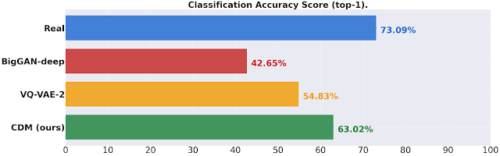
256×256の解像度でのImageNet分類精度スコアの比較
生成されたデータでトレーニングされた分類器を検証セットを使って精度測定した結果です。
CDMで生成されたデータは、既存の方法よりも大幅に向上し、現実のデータと生成されたデータの間の分類精度のギャップを埋めます。(高いほど良いです)
結論
SR3とCDMを使用して、拡散モデルのパフォーマンスを超解像およびクラス条件付きのImageNet生成ベンチマークで最先端に押し上げました。さまざまな生成モデリングの問題について、拡散モデルの限界をさらにテストできることをうれしく思います。私たちの研究の詳細については、github.ioで公開された各Webページをご覧ください。
謝辞
共著者のWilliam Chan, Mohammad Norouzi, Tim Salimans, David Fleetに感謝します。また、Ben Poole, Jascha Sohl-Dickstein, Doug Eckそして、Google Research、Google Brain Teamの研究に対する議論と支援に感謝します。
また、本稿のアニメーション作成を手伝ってくれたTom Smallに感謝します。
3.拡散モデルを使用してGANより忠実度の高い画像を生成(2/2)関連リンク
1)ai.googleblog.com
High Fidelity Image Generation Using Diffusion Models
2)arxiv.org
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Improved Denoising Diffusion Probabilistic Models
3)iterative-refinement.github.io
SR3:Image Super-Resolution via Iterative Refinement
4)cascaded-diffusion.github.io
Cascaded Diffusion Models for High Fidelity Image Generation

