
1.SSD:半教師あり蒸留を使ってGoogle検索を改善(2/2)まとめ
・Noisy Studentとknowledge distillationは似ているが後者はノイズを混入しない
・半教師あり蒸留は、生徒に蒸留する前に同等以上の規模の教師を自己訓練する2段階手法
・半教師あり蒸留はGoogle検索のような非常に大規模な製品でも検索品質向上に結びついた
2.SSDとは?
以下、ai.googleblog.comより「From Vision to Language: Semi-supervised Learning in Action…at Scale」の意訳です。元記事は2021年7月14日、Thang LuongさんとJingcao Huさんによる投稿です。
蒸留をイメージしたアイキャッチ画像のクレジットはPhoto by Joey Huang on Unsplash
Noisy Studentとknowledge distillationを併用
Noisy Studentはknowledge distillation(知識蒸留)に似ています。知識蒸留は、知識を大きなモデル(つまり教師モデル)から小さなモデル(生徒モデル)に転移するプロセスです。
知識蒸留の目標は速度を向上させることです。教師モデルと比較して品質をそれほど犠牲にすることなく、本番環境で高速に実行できる生徒モデルを構築する事が目標となります。
蒸留の最も簡単な設定では、1人の教師が関与し、同じデータを使用しますが、実際には、複数の教師または生徒用の個別のデータセットを使用する事ができます。
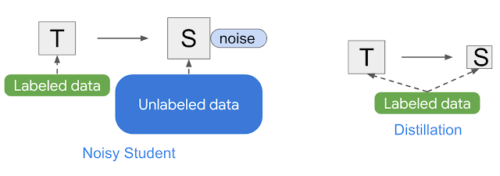
Noisy Studentとknowledge distillationの簡単な概要
Noisy Studentとは異なり、知識蒸留はトレーニング中にノイズを追加せず(つまり、データ水増しやモデルの正則化を行わない)、通常は、より小さな生徒モデルをトレーニングします。対照的に、Noisy Studentは「知識拡大(knowledge expansion)」の手法と考えることができます。
半教師あり蒸留
本番環境に製品展開するモデルをトレーニングするための別の戦略は、Noisy Studentのトレーニングを2回適用することです。
最初に大きな教師モデルT’を取得し、次に小さな生徒Sを派生させます。このアプローチにより、教師あり学習を使用したトレーニングやNoisy Studentのトレーニングのみを使用したトレーニングよりも優れたモデルが生成できます。
具体的には、530万パラメーターのEfficientNet-B0から6,600万パラメーターのEfficientNet-B7までの視覚タスクを扱うEfficientNetシリーズに適用すると、この戦略は、特定のモデルサイズ毎にはるかに優れたパフォーマンスを実現します。(詳細については、Noisy Studentの論文の表9を参照してください)
Noisy Studentのトレーニングをうまく機能させるには、RandAugment(視覚タスク用)やSpecAugment(音声タスク用)などのデータ水増しが必要です。しかし、自然言語処理などの特定のアプリケーションでは、このようなタイプの入力ノイズは簡単には利用できません。
これらのアプリケーションでは、Noisy Studentトレーニングを簡略化してノイズを使わないようにする事ができます。その場合、上記の2段階のプロセスは、私達が「半教師あり蒸留(SSD:Semi-Supervised Distillation)」と呼ぶ、より単純な方法になります。
最初に、教師モデルはラベルのないデータセットの疑似ラベルを推測し、そこから元の教師モデルと同じかそれ以上のサイズの新しい教師モデル(T’)をトレーニングします。本質的に自己訓練であるこのステップの後に、知識の蒸留が続き、製品展開するためのより小さな生徒モデルを学習させます。
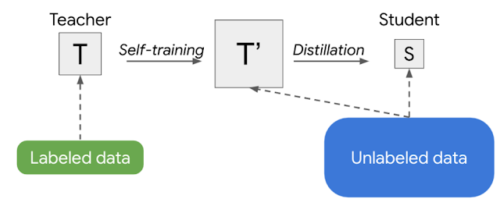
半教師あり蒸留(SSD)の概略図
これは、生徒(S)に蒸留する前に、同等以上の規模の教師(T’)を自己訓練する2段階のプロセスです。
Google検索の改善
視覚タスクで成功したことで、次のステップは、言語理解タスクです。Google検索のような言語理解が必要なアプリケーションは、より幅広いユーザーに影響を与える事が出来ます。
この場合、言語をよりよく理解するためにBERTに基づいて構築された、検索時に重視されるランキングに関する箇所に焦点を当てます。このタスクはSSDに適していることがわかりました。
SSDをランキング決定部に適用して、候補となる検索結果と検索文の関連性をよりよく理解する事ができました。SSDは2020年に展開されたGoogle 検索に関する上位施策の中で最高のパフォーマンス向上の1つを達成しました。
以下は、改善されたモデルがより良い言語理解を示す検索結果の一例です。
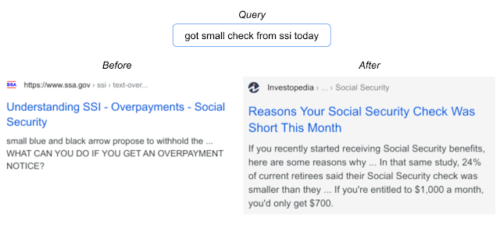
SSDの実装により、ユーザーは検索語により関連性のある文書を見つけることができます。
将来の研究と課題
製品レベルの大規模検索における半教師あり蒸留(SSD)の成功例を紹介しました。SSDは、業界での機械学習の使用状況を、主に教師あり学習から半教師あり学習に変え続けると信じています。私たちの結果は有望ですが、ノイズの多い現実の世界でラベルのないデータを効率的に利用し、さまざまな領域に適用する方法については、まだ多くの研究が必要です。
謝辞
Zhenshuai Ding, Yanping Huang, Elizabeth Tucker, Hai Qian, Steve Heeは、このプロジェクトの立ち上げの成功に多大な貢献をしました。このプロジェクトは、Google BrainチームとGoogle Searchチームの両方のメンバー( Shuyuan Zhang, Rohan Anil, Zhifeng Chen, Rigel Swavely, Chris Waterson, Avinash Atreya)からの貢献がなければ成功しませんでした。
本研究に関するフィードバックを提供してくれたQizhe XieとZihang Daiに感謝します。また、Quoc Le, Yonghui Wu, Sundeep Tirumalareddy, Alexander Grushetsky, Pandu Nayakのリーダーシップサポートに感謝します。
3.SSD:半教師あり蒸留を使ってGoogle検索を改善(2/2)関連リンク
1)ai.googleblog.com
From Vision to Language: Semi-supervised Learning in Action…at Scale
2)arxiv.org
Self-training with Noisy Student improves ImageNet classification

