
1.Falken:摸倣学習を使用して複雑なゲームを効率的にデバッグ(1/2)まとめ
・機械学習はゲーム開発に大きな影響を与える可能性があるが実務に応用はまだ難しい
・ゲーム開発者がゲームテストエージェントを迅速かつ効率的にトレーニングする手法を発表
・MLの専門知識がなくとも人気ゲームジャンルの多くで機能するポリシーをトレーニング可能
2.機械学習をゲーム開発に応用
以下、ai.googleblog.comより「Quickly Training Game-Playing Agents with Machine Learning」の意訳です。元記事の投稿は2021年6月29日、Leopold HallerさんとHernan Moraldoさんによる投稿です。
カードゲームを機械学習を使ってデバッグする話はちょっと前にありました。あれは比較的シンプルな畳み込みニューラルネットワーク(CNN:Convolutional Neural network)使って実現できたとのお話でしたが、今回はもう少し複雑なゲームが対象で、且つゲームのプレイを聞くと一般的には強化学習(RL:Reinforcement learning)を思い浮かべますが、人間のプレーヤーの操作を真似させるために模倣学習(IL:Imitation Learning)を使ったと言うお話です。
アイキャッチ画像のクレジットはPhoto by Alexander Jawfox on Unsplash
過去20年間で、コンピューターとネットワークの劇的な進歩により、ゲーム開発者はますます拡大で複雑な世界を舞台とする作品を創造できるようになりました。シンプルな直線で表現されたダンジョンは写真画質のオープンワールドに進化し、手動ではなくアルゴリズムでデータを作り上げる事ができる手続き型アルゴリズム(procedural algorithms)は前例のない多様性を備えたゲームを可能にし、インターネットアクセスの拡大はゲームをダイナミックなオンラインサービスに変えました。
残念ながら、ゲームの舞台となる世界の広さと複雑さは、品質保証チームの規模や従来の自動テストの機能よりも急速に拡大しています。これは、製品の品質(リリースの遅延やリリース後のパッチなど)と開発者の生活の質の両方に課題をもたらします。
機械学習(ML:Machine learning)技術は、ゲーム開発に大きな影響を与える可能性を示しており、実行可能な解決策を提供します。これにより、デザイナーはゲームのバランスを取り、アーティストが従来必要だった時間の何分の1かで高品質の資産を作成できるようになります。
さらに、それらは最高レベルのプレーが可能な挑戦的な対戦相手を訓練するために使用することができます。
しかし、一部のML手法は、現在、ゲーム開発の運用チームにとって実行が難しい要件をもたらす可能性があります。これには、ゲーム固有のニューラルネットワークアーキテクチャの設計、MLアルゴリズムの実装に関する専門知識、数十億フレームを含む膨大なトレーニングデータの生成などが含まれます。
逆に、ゲームの開発者の立場であれば、ゲームソースへの直接アクセス、ゲームの熟練者によるデモンストレーション、ビデオゲームの独自のインタラクティブな性質など、ML技術を活用して独自の活動を行う事ができます。
本日は、ゲーム開発者がゲームテストエージェントを迅速かつ効率的にトレーニングするために使用できるMLベースのシステムを紹介します。これにより、開発者は深刻なバグをすばやく見つけることができ、人間のテスターはより複雑で入り組んだ問題に集中できます。
結果として得られるソリューションは、MLの専門知識を必要とせず、最も人気のあるゲームジャンルの多くで機能し、単一のゲームでは1時間未満で、ゲーム状態からゲームアクションを生成するMLポリシーをトレーニングできます。また、これらの手法の機能的な応用法を示すオープンソースライブラリもリリースしました。

サポートされているジャンルには、アーケードゲーム、アクション/アドベンチャー、レーシングゲームなどがあります。
適切な作業を行うための適切なツール
ビデオゲームをテストする最も基本的な形式は、単にゲームをプレイすることです。何度もです。最も深刻なバグ(クラッシュやゲームの舞台から抜け出てしまう事など)の多くは、簡単に検出して修正できます。
難しい課題は、現代のゲームの広大な舞台内でそれらを見つけることです。そのため、大規模に「ゲームをプレイするだけ」のシステムのトレーニングに重点を置くことにしました。
これを行う最も効果的な方法は、「ゲーム全体を直接プレイできる単一の非常に効果的なエージェント」をトレーニングすることではなく、開発者にゲームテストエージェントのアンサンブルをトレーニングする機能を提供することであることがわかりました。それぞれが、ゲーム開発者が「ゲームプレイループ(gameplay loops)」と呼ぶ、数分のタスクを効果的に実行できるテストエージェントです。
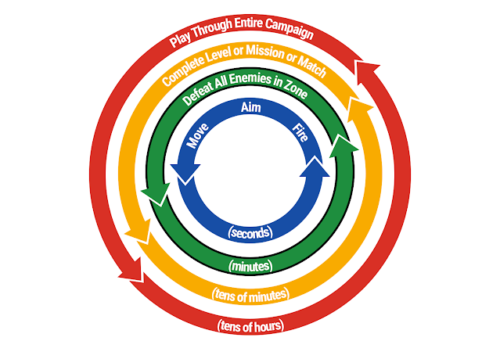
これらのコアゲームプレイ動作は、従来の方法でプログラミングするのは高くつく事ががよくありますが、「直接ゲームをプレイ可能な単一のMLモデル」よりもはるかに効率的にトレーニングできます。
実際には、商用ゲームは主要なゲームプレイループを繰り返して混ぜ合わせる事でより長いループを作成します。つまり、開発者はMLポリシーと少量の単純なスクリプトを組み合わせることで、ゲームプレイの大部分をテストできます。
シミュレーション中心としたセマンティックAPI
MLをゲーム開発に適用する際の最も基本的な課題の1つは、シミュレーション中心のビデオゲームの世界とデータ中心のMLの世界との間の隔たりを埋めることです。
開発者にゲームの状態をゲーム固有の低レベルなML特徴表現に直接変換するように依頼したり(労力がかかりすぎる)、生の画素から学習しようとしたり(トレーニングに必要なデータが多すぎる)する事はしません。
私たちのシステムは、開発者が自然な形で実行できるゲーム開発者向けのAPIを提供します。これにより、プレーヤーが観察する本質的な状態と実行できる行動の意味の観点からゲームを描写できます。この情報はすべて、エンティティ(entities)、レイキャスト(raycasts)、3Dの位置と回転(3D positions and rotations)、ボタン、ジョイスティックなど、ゲーム開発者に馴染みのある概念を介して表現されます。
以下の例でわかるように、APIを使用すると、わずか数行のコードで監視とアクションを指定できます。

レーシングゲームのアクションと観察の例
3.Falken:摸倣学習を使用して複雑なゲームを効率的にデバッグ(1/2)関連リンク
1)ai.googleblog.com
Quickly Training Game-Playing Agents with Machine Learning
2)github.com
google-research / falken

