
1.データの力で古典的機械学習が量子機械学習を凌駕(2/2)まとめ
・量子カーネルは暗記を促進してしまうため古典的手法で簡単に扱える形状に苦しむことが多い
・量子embeddingを古典的な表現に投影する投影量子カーネル法を開発した
・十分なデータが提供されれば多くの量子問題が古典的学習法で容易に処理できる事がわかった
2.量子コンピューターが有利なデータセットとは?
以下、ai.googleblog.comより「Quantum Machine Learning and the Power of Data」の意訳です。元記事は2021年6月22日、Jarrod McCleanさんとHsin-Yuan (Robert) Huangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Jaanus Jagomägi on Unsplash
量子カーネルの投影アプローチ
幾何テストによって明らかにされた洞察の1つは、従来の量子カーネルは、理解ではなく暗記を促進してしまうため、古典的手法で簡単に扱える形状に苦しむことが多いということでした。
これにより、量子embeddingを古典的な表現に投影する投影量子カーネル(projected quantum kernel)を開発する事になりました。この特徴表現は、古典的なコンピューターで直接計算するのはまだ難しいですが、量子空間に完全にとどめるのと比較すれば、多くの実用的な利点があります。
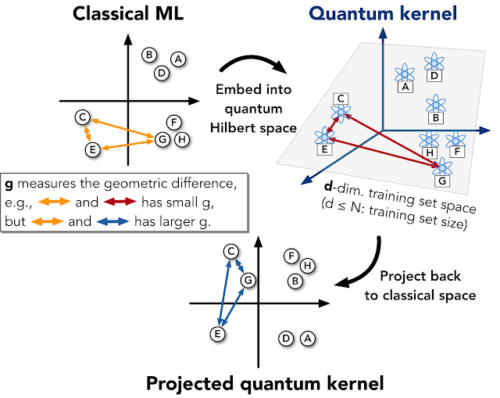
量子優位性の可能性を定量化する幾何定数 gは、ここで紹介した投影量子カーネルを含む、いくつかのembeddingについて示されています。
古典的な空間に選択的に投影することにより、古典的にシミュレートするのがまだ難しい量子形状の側面を保持することができます。
しかし、投影により、元の量子カーネルよりも、入力のわずかな変化に関してより適切に動作する距離関数、つまりカーネルの開発がはるかに簡単になっています。さらに、投影された量子カーネルは、古典的に開発された強力な非線形カーネル(2次関数のような)とより良い統合を容易にします。これを元の量子空間で行うのははるかに困難です。
この投影された量子カーネルには、既存のembeddingの非線形関数を記述する能力の向上、データポイントの数に応じてカーネルを二次から線形に処理するために必要なリソースの削減、およびより大きなサイズでより適切に一般化する能力など、以前のアプローチに比べて多くの利点があります。カーネルはまた、幾何学定数gを拡張するのに役立ち、量子超越性の最大の可能性を確保するのに役立ちます。
データセットは学習の利点を示します
幾何テストは、考えられるすべてのラベル関数の潜在的な利点を定量化しますが、実際には、特定のラベル関数に関心があることがほとんどです。学習理論的アプローチを使用して、特定のタスクの汎化誤差も制限しました。これには、起源が明確に量子であるタスクも含まれます。
量子コンピューターの利点は、同時に多くの量子ビットを使用できることに依存していますが、以前のアプローチでは量子ビット数の規模拡張性が不十分であるため、適度に大きな量子ビットサイズ(> 20)でタスクを検証して、手法が実際の問題の解決に繋がる可能性があることを確認することが重要です。
私たちの研究では、オープンソースツールであるTensorFlow-Quantumによって実現された最大30量子ビットを検証し、ペタフロップスのコンピューティングへの規模拡張を可能にしました。
興味深いことに、十分なデータが提供されれば、最大30量子ビットであっても、多くの生来の量子問題が古典的な学習方法で容易に処理されることが示されました。したがって、1つの結論は、量子問題に見えるいくつかの問題であっても、データによって強化された古典的な機械学習方法は、量子コンピューターの能力に匹敵する可能性があるということです。
しかしながら、投影された量子カーネルと幾何的構築を組み合わせて、古典的なモデルよりも量子モデルの経験的な学習利点を示すデータセットを構築することができました。したがって、将来の量子問題でそのようなデータセットを見つけることは未解決の問題のままですが、これが当てはまる可能性があるラベル関数の存在を示すことができました。
この問題は設計されたものなので、量子計算の優位性を発揮するためにembeddingをより大きく、より挑戦的なものにする必要がありますが、本研究は、量子機械学習でデータが果たす役割を理解する上で重要なステップを表しています。
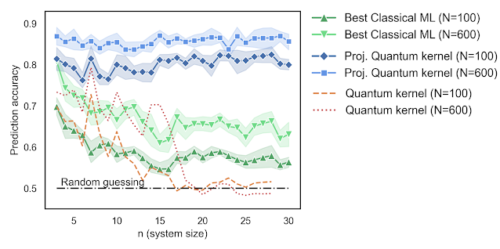
量子モデルでの学習の利点の可能性を最大化するように設計された問題の量子ビット数(n)と予測精度。データは、2つの異なるサイズのトレーニングデータ(N)について示されています。
この問題については、量子ビット数(n)をスケールアップし、投影された量子カーネルの予測精度を、既存のカーネルアプローチおよびデータセット内の最高の古典的な機械学習モデルと比較しました。さらに、これらの結果からの重要なポイントは、量子コンピューターが有利なデータセットの存在を示したものの、多くの量子問題では、古典的な学習方法が依然として最良のアプローチであったということです。データが特定の問題にどのように影響するかを理解することは、それが考慮されていない従来の計算問題とは異なり、学習問題における量子優位性を議論するときに考慮すべき重要な要素です。
結論
量子コンピューターが機械学習を支援する能力を検討するとき、データの可用性が根本的に問題を変えることを示しました。私たちの研究では、これらの質問を調べるための実用的なツールセットを開発し、それらを使用して、既存のアプローチに比べて多くの利点がある新しい投影量子カーネル法(projected quantum kernel method)を開発しました。私達はこれまでで最大の数値デモンストレーションである30量子ビットを量子embeddingの潜在的な学習上の利点を調べるために構築しました。実際のアプリケーションでの完全な計算上の利点はまだわかっていませんが、この研究は、前進するための基盤を確立するのに役立ちます。興味のある読者は、この研究を簡単に構築できるように、論文と関連するTensorFlow-Quantumチュートリアルの両方を確認することをお勧めします。
謝辞
この論文の共著者であるMichael Broughton, Masoud Mohseni, Ryan Babbush, Sergio Boixo, Hartmut NevenおよびGoogle QuantumAIチーム全体に感謝します。さらに、Richard Kueng, John Platt, John Preskill, Thomas Vidick, Nathan Wiebe, Chun-Ju Wu, and Balint Patoからの貴重なヘルプとフィードバックに感謝します。
3.データの力で古典的機械学習が量子機械学習を凌駕(2/2)関連リンク
1)ai.googleblog.com
Quantum Machine Learning and the Power of Data
2)www.nature.com
Power of data in quantum machine learning

