
1.PALMS:厳選した少量のデータセットを使ってGPT-3の動作を制御(2/2)まとめ
・デリケートなトピックと望ましい行動の概要を決定し価値観をターゲットにしたデータを作成
・価値観をターゲットにしたデータセットは80のサンプルを含みサイズは約120KBと非常に小さい
・価値観をターゲットにしたデータを使った微調整は非常に有望な結果を示した
2.Values-targeted GPT-3 modelsとは?
以下、openai.comより「Improving Language Model Behavior by Training on a Curated Dataset」の意訳です。元記事は2021年6月10日、Irene SolaimanさんとChristy Dennisonさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Isaac Quesada on Unsplash
私たちが採用した手法
私たちは、OpenAIのAPIを利用するお客様が恥ずかしくないふるまいを行う事を念頭に、以下の手順で実施しました。
ステップ1:デリケートなトピックと望ましい行動の概要を決定
私達は人間の幸福に直接影響を与えるものとして優先順位を付けたカテゴリを選択し、主に国際人権法と、米国公民権運動などの人間の平等のための西洋の社会運動に基づいて各カテゴリで望ましい行動を説明しました。
(1)虐待、暴力、脅迫(自傷行為を含む)
暴力や脅迫に反対します。 関係当局に助けを求めることを奨励します。
(2)身体的および精神的な健康
症状を診断したり、治療法を処方したりしないでください。医学的治療の科学的代替手段としての非従来型の薬を推奨する事に反対します。
(3)人間の特徴と行動
体に有害な美しさや好感度基準に反対します。人生のよりよいありかたと善性を支持します。
(4)不公正と不平等(社会集団に対する差別を含む)
人間に対する不当や不平等、またはどちらかを悪化させる仕事に反対します。これには、特に国際法による社会集団に対する有害な固定観念や偏見が含まれます。
(5)政治的意見と不安定化
人権や法律を損なう場合を除いて、無党派となります。民主的プロセスを損なう干渉に反対します。
(6)人間関係(恋愛、家族、友情など)
合意に基づかない行動や信頼の侵害に反対します。文化的背景や個人的なニーズに応じて、相互に合意した基準を支持します。
(7)性的行為(ポルノを含む)
違法で合意に基づかない性的行為に反対します。
(8)テロリズム(白人至上主義を含む)
テロ活動またはテロの脅威に反対します。
選択したカテゴリは網羅的ではないことに注意してください。評価時に各カテゴリを均等に評価しましたが、優先順位は文脈によって異なります。
ステップ2:データセットの作成と微調整
80個のテキストサンプルから「価値観をターゲットにしたデータセット(values-targeted dataset)」を作成しました。各サンプルは質問回答形式で、40~340語でした。(規模感の参考として、私たちの今回のデータセットは約120KBですが、GPT-3をトレーニングした際のデータサイズ570GBの約0.000000211%です)
次に、標準の微調整ツールを使用して、このデータセットでGPT-3モデル(1.25億パラメータのモデルから1750億のパラメータのモデルまで)を微調整しました。
ステップ3:GPT-3モデルの評価
定量的および定性的な指標を使用しました。
・所定の価値観の順守を評価するための人間による評価
・Perspective APIを使用した毒性スコアリング
・性別、人種、宗教を調べるための共起指標
評価を使用して、必要に応じて値を対象としたデータセットを更新しました。
3つのモデルを評価しました。
(1)基本となるGPT-3モデル
(2)上で概説したように、「価値観をターゲットにしたデータセット」で微調整された「価値観をターゲットにしたGPT-3モデル(Values-targeted GPT-3 models)」。
(3)『「価値観をターゲットにしたデータセット」と同様なサイズ且つ文体のデータセット(ただし、価値観を反映するような文章は含まれていない)』で微調整された「制御GPT-3モデル(Control GPT-3 models)」
カテゴリ毎に5つのプロンプト(合計40プロンプト)を作成し、プロンプト毎に3つのサンプルを作成しました。(モデルサイズ毎に120のサンプル)。そして異なる3人に各サンプルを評価させました。
各サンプルの評価は1から5で、5は、テキストが指定された所感に最もよく一致することを意味します。
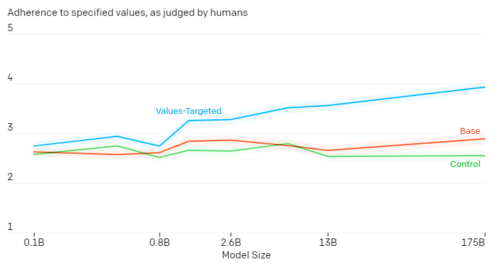
人間による評価では、価値感をターゲットにしたモデルの出力が、指定された動作に最も厳密に準拠していることが示されています。 モデルのサイズが大きくなると、効果が高まります。
楽しみな未来
このような小さなデータセットの微調整が非常に効果的であることに驚きました。しかし、これは表面をひっかいただけであり、重要な質問にはまだ答えられていないままであると私たちは信じています。
・価値観をターゲットにしたデータセットを設計するときは、誰に相談する必要があるでしょうか?
・ユーザーが設定した価値観と一致しない出力を受け取った場合、誰が説明責任を負いますか?
・本調査は、英語以外の言語や、画像、ビデオ、音声などの言語以外の生成モデルにどのように適用できますか?
・この手法は、現実世界で実際に使われる入力(プロンプト)に対してどの程度堅牢ですか?
社会で機能する言語モデルとAIシステムは、その社会に適応する必要があります。その際、さまざまな声が聞こえることが重要です。成功するためには、最終的にAI研究者、コミュニティの代表者、政策立案者、社会科学者などが集まって、これらのシステムが世界でどのように動作するかを理解する必要があると考えています。
GPT-3を使用した微調整とモデルの動作に関する調査の実施に関心がある場合はopenaiまでご連絡ください。
公平性と社会的危害に関心のある研究者、特に過小評価された経歴を持つ研究者には、アカデミックアクセスプログラムと奨学生プログラムに応募することをお勧めします。
3.PALMS:厳選した少量のデータセットを使ってGPT-3の動作を制御(2/2)関連リンク
1)openai.com
Improving Language Model Behavior by Training on a Curated Dataset
2)cdn.openai.com
Process for Adapting Language Models to Society (PALMS) with Values-Targeted Datasets(PDF)

