
1.Project Guideline:視力の弱い人が一人で走れるようにする(1/2)まとめ
・失明または弱視状態の人にとって支援者なしに一人でランニングすることは困難
・Project Guidelineは路面に案内線が塗装されている様々な環境でランナーをガイド可能
・8歳で盲目になったThomas Panekさんはセントラルパークを一人で5Km完走
2.Project Guidelineとは?
以下、ai.googleblog.comより「Project Guideline: Enabling Those with Low Vision to Run Independently」の意訳です。元記事の投稿は2021年5月18日、Xuan Yangさんによる投稿です。
走れる喜びを表現したアイキャッチ画像のクレジットはPhoto by cameron-venti on Unsplash
失明または弱視状態で生活している世界中の2億8500万人にとって、一人で運動することは困難な場合があります。今年の初めに、Guiding Eyes for the Blind社と共同で開発された初期段階の研究プロジェクトであるProject Guidelineを発表しました。このプロジェクトは、機械学習を使用して、路面に案内線が塗装されている様々な環境でランナーをガイドします。
Guidelineテクノロジーを実行するスマートフォンとヘッドフォンのペアのみを使用して、Guiding Eyes for the Blind社のCEOのThomas Panekは、数十年ぶりに、ニューヨーク市のセントラルパーク内の5kmを支援者なしで一人で完走することができました。
完全な予測が不可能な環境で視覚障害者を安全かつ確実に導くには、多くの課題に取り組む必要があります。
以下では、ガイドラインの背後にあるテクノロジーと、Thomasを屋外で独立してランニングする事を可能にしたオンデバイスの機械学習モデルを作成することができたプロセスについて説明します。
このプロジェクトはまだ開発中ですが、携帯電話が提供するオンデバイステクノロジーが、目の不自由な人や弱視の人に信頼性の高い適応体験と、移動能力を強化する提供する方法を探るのに役立つことを願っています。

Project Guidelineを使用して屋外で単独でランニングするThomas Panekさん
(遺伝により8歳から法的に盲目と見なされる状態になってしまった方です)
プロジェクトガイドライン
ガイドラインシステムは、カスタムベルトと留め具を使用してユーザーの腰に装着するモバイルデバイス、ペンキまたはテープで記された走行経路上のガイドライン、および骨伝導ヘッドホンで構成されています。
ガイドラインテクノロジーの中核となるのは、モバイルデバイスのカメラからフレームを入力として受け取り、フレーム内のすべての画素を「ガイドライン」または「ガイドラインではない」の2つのクラスに分類するオンデバイスのセグメンテーションモデルです。
この単純な確信マスク(confidence mask)は全てのフレームに適用され、ガイドラインアプリは、位置データを使用せずに、通路上の案内線に対してランナーがどのように進んでいるかを予測できます。
この予測と進行中のスムージング/フィルタリング機能に基づいて、アプリはランナーに音声信号を送信して、ランナーがそのまま案内線に従うか、向きを変えて案内線が示す方向に向かう事を助けます。
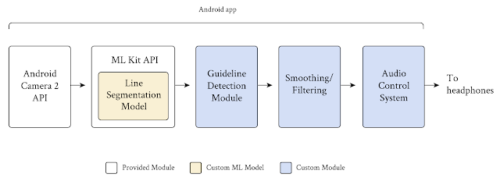
プロジェクトガイドラインは、Androidに組み込まれているCamera 2 APIおよびMLKit APIを使用し、カスタムモジュールを追加して、ガイドラインをセグメント化し、その位置と方向を検出し、誤った信号をフィルタリングし、ステレオオーディオ信号をリアルタイムでユーザーに送信します。
ガイドラインシステムを構築する準備を行う中で、いくつかの重要な課題に直面しました。
システムの精度
視覚障害者や弱視者のコミュニティに属する人々が移動する際、ユーザーの安全が最も重要な課題です。様々な場所や様々な環境条件下でランナーの安全を確保するために、正確で一般化されたセグメンテーション結果を生成できる機械学習モデルが必要です。
システムのパフォーマンス
ユーザーの安全性に対処することに加えて、システムはパフォーマンスが高く、効率的で、信頼性が高い必要があります。ランナーにリアルタイムのフィードバックを提供するには、少なくとも15フレーム/秒(FPS)を処理する必要があります。また、携帯電話のバッテリーを使い切る事なく少なくとも3時間実行できる必要があり、ウォーキング/ランニング経路がデータ通信サービスのない地域を通る場合は、インターネット接続がなくともオフラインで動作する必要があります。
学習用データの欠如
セグメンテーションモデルをトレーニングするために、黄色い線が付いた道路と走行経路で構成される大量のビデオが必要でした。モデルを一般化するには、データの多様性はデータ量と同じくらい重要であり、さまざまな時間帯、さまざまな照明条件、さまざまな気象条件、さまざまな場所などでビデオフレームを撮影する必要があります。
以下では、これらの各課題に対する解決策を紹介します。
ネットワークアーキテクチャ
処理速度と消費電力の要件を満たすために、DeepLab v3フレームワーク上にラインセグメンテーションモデルを構築し、MobilenetV3-Smallをバックボーンとして利用しながら、「ガイドライン」と「背景」のいずれかだけを分類するように出力を簡素化しました。
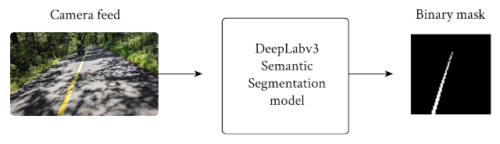
モデルはRGBフレームを取り、画素単位でグレースケールマスクを生成します。色の濃淡は予測の信頼性を表します。
処理速度を上げるために、DeepLabセグメンテーションモデルへの入力として、カメラからの入力を1920×1080画素から513×513画素に縮小します。モバイルデバイスで使用するためにDeepLabモデルをさらに高速化するために、最後のアップサンプルレイヤーをスキップし、65×65ピクセルの予測マスクを直接出力しました。これらの65×65ピクセルの予測マスクは、後処理への入力として提供されます。両方の段階で入力解像度を最小化することで、セグメンテーションモデルの実行時間を改善し、後処理を高速化できます。
3.Project Guideline:視力の弱い人が一人で走れるようにする(1/2)関連リンク
1)ai.googleblog.com
Project Guideline: Enabling Those with Low Vision to Run Independently
2)docs.google.com
Project Guideline inquiry form
3)blog.google
How Project Guideline gave me the freedom to run solo

