
1.ALIGN:ノイズの多い文章を教師に使って視覚と言語で共通する特徴表現を学習(2/3)まとめ
・ALIGNは微調整なしでテキストを使った画像検索や画像とテキストを同時に使った検索を実現
・微調整を行うとALIGNはBiTやViTなどのほとんどの汎用モデルよりも高い精度を実現
・ImageNetとその亜種を使ったゼロショット分類のtop1精度もCLIPを上回った
2.ALIGNのゼロショット性能
以下、ai.googleblog.comより「ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision」の意訳です。元記事の投稿は2021年5月11日、Chao JiaさんとYinfei Yangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by davide ragusa on Unsplash
ALIGN:A Large-scale ImaGe and Noisy-Text Embedding
より大きく、より強力なモデルを簡単に構築するために、画像とテキストのペアの視覚的表現と言語表現を並べて学習するシンプルなデュアルエンコーダアーキテクチャを採用しています。
画像およびテキストエンコーダーは、対照的な損失(正規化されたソフトマックスとして定式化)を介して学習します。これは、一致している画像とテキストのペアのembeddingsを近づくように促し、一致しない画像とテキストのペアのembeddings(同じバッチ内で)が離れるように促します。
大規模なデータセットにより、モデルサイズをEfficientNet-L2(画像エンコーダー)およびBERT-large(テキストエンコーダー)と同じ大きさにスケールアップして、ゼロからトレーニングすることができます。学習した特徴表現は、下流の視覚タスクや視覚言語間タスクに使用できます。

Imagenet(Krizhevsky et al. 2012)とVTAB(Zhai et al. 2019)の概要図
結果の特徴表現は、視覚のみまたは視覚言語間タスク転移に使用できます。微調整なしで、ALIGNはクロスモーダル検索(画像からテキストへの検索、テキストから画像への検索、さらには画像とテキストの共同クエリを使用した検索)を強化します。以下の例をご覧ください。

検索と特徴表現の評価
テキストおよび画像エンコーダバックボーンにBERT-LargeおよびEfficientNet-L2を使用して学習したALIGNモデルは、以下に示すように、ゼロショット設定と微調整設定の両方で、複数の画像テキスト検索タスク(Flickr30KおよびMS-COCO)でSotAパフォーマンスを実現します。
| Flickr30K (1K test set) R@1 | MS-COCO (5K test set) R@1 | ||||
| Setting | Model | image → text | text → image | image → text | text → image |
| Zero-shot | ImageBERT | 70.7 | 54.3 | 44 | 32.3 |
| UNITER | 83.6 | 68.7 | – | – | |
| CLIP | 88 | 68.7 | 58.4 | 37.8 | |
| ALIGN | 88.6 | 75.7 | 58.6 | 45.6 | |
| Fine-tuned | GPO | 88.7 | 76.1 | 68.1 | 52.7 |
| UNITER | 87.3 | 75.6 | 65.7 | 52.9 | |
| ERNIE-ViL | 88.1 | 76.7 | – | – | |
| VILLA | 87.9 | 76.3 | – | – | |
| Oscar | – | – | 73.5 | 57.5 | |
| ALIGN | 95.3 | 84.9 | 77 | 59.9 | |
Flickr30KおよびMS-COCOデータセット(ゼロショットと微調整の両方)での画像対テキスト検索結果(recall@1)。ALIGNは、クロスモダリティAttentionモデル(大規模な検索アプリケーションに用いるには処理が複雑すぎる)を含む従来の手法を大幅に上回っています。
ALIGNは、強力な画像特徴表現モデルでもあります。 以下に示すように、固定した特徴表現を使用すると、ALIGNはCLIPをわずかに上回り、ImageNetで85.5%のtop1精度のSotAスコアを達成します。
微調整により、ALIGNは、BiTやViTなどのほとんどの汎用モデルよりも高い精度を実現します。ImageNetトレーニングと大規模なラベルなしデータ間のより深い相互作用を必要とするメタ疑似ラベル(Meta Pseudo Labels)よりも劣るだけです。
| Model (backbone) | Acc@1 w/ frozen features | 1 | Acc@5 |
| WSL (ResNeXt-101 32x48d) | 83.6 | 85.4 | 97.6 |
| CLIP (ViT-L/14) | 85.4 | – | – |
| BiT (ResNet152 x 4) | – | 87.54 | 98.46 |
| NoisyStudent (EfficientNet-L2) | – | 88.4 | 98.7 |
| ViT (ViT-H/14) | – | 88.55 | – |
| Meta-Pseudo-Labels (EfficientNet-L2) | – | 90.2 | 98.8 |
| ALIGN (EfficientNet-L2) | 85.5 | 88.64 | 98.67 |
ImageNet分類結果を教師あり学習(微調整)と比較
ゼロショット画像分類
従来、画像分類の問題は各クラスを独立したIDで扱い、クラス毎にある程度の数のラベル付きデータを用意して少なくとも小数回、分類レイヤーをトレーニングする必要があります。
しかし、クラス名は実際には自然言語のフレーズであるため、トレーニングデータが存在しなくても、画像分類のためにALIGNの画像対文章検索機能に自然に拡張できます。
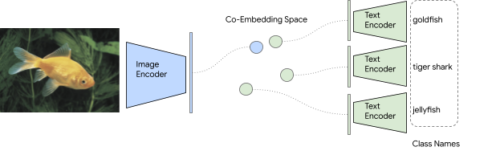
事前にトレーニングされた画像およびテキストエンコーダーは、整列されたembedding空間内で最も近いクラス名を取得することにより、画像を分類するタスクに直接使用できます。このアプローチでは、定義されたクラス空間で事前にトレーニングする必要はありません。
ImageNet検証データセットでは、Open AIのCLIPに似ていますが、ALIGNは76.4%のtop1ゼロショット精度を達成し、分布シフト(distribution shifts)を伴うImageNetの様々な亜種で優れた堅牢性を示します。CLIPと同様にテキストプロンプトエンジニアリングとアンサンブルを使用しました。
| ImageNet | ImageNet-R | ImageNet-A | ImageNet-V2 | |
| CLIP | 76.2 | 88.9 | 77.2 | 70.1 |
| ALIGN | 76.4 | 92.2 | 75.8 | 70.1 |
ImageNetとその亜種を使ったゼロショット分類のtop1精度
3.ALIGN:ノイズの多い文章を教師に使って視覚と言語で共通する特徴表現を学習(2/3)関連リンク
1)ai.googleblog.com
ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
2)arxiv.org
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
3)www.ghibli.jp
ハウルの動く城(2004)

ゼロショット可能なGPT-3やCLIPはテキスト入力の表現によって、分類精度が変わる事が知られていて、入力文章の表現を工夫する事をテキストプロンプトエンジニアリング(text prompt engineering)と呼びます。毎度のジブリ画像の例で恐縮ですが、ジブリ映画の画像群から人が描写されている画像を抜き出したかったので、CLIPにgirlとかboyとかmanとかwoman, person, humanなどの人を表す単語群と、Landscapeやbuilding、house、wall、streetなどの背景を表現する単語群を与えてゼロショット分類して貰ったらそこそこ良い精度(写真を使ってトレーニングした通常の画像分類モデルはアニメ画像をほぼ分類できないのでこれだけでも凄い事)なのですが、以下の画像だけmanもwomanもhumanもpersonもダメ、どうしても人間が写っている画像と認識してくれなかったんです。
ハウルの動く城のハウルなのですが、理由、わかりますでしょうか?
当初、中性的な絵なので、男性と女性の判別がつきにくいのでどっちかわからずに誤認識してしまうのかなぁ、と思って致し方なしとスルーしてしまったのですが、たまたま天啓を受けて気づきました。
これ、わかったら、テキストプロンプトエンジニアリング実務検定3級資格を差し上げます。