
1.Crisscrossed Captions:画像とテキストの意味的類似性の探求(2/3)まとめ
・類似性が高いと予想される新しいペアを抽出し、そのペアを人が評価する事にした
・キャプションの類似性が高い画像同士は類似性が高い可能性があるのでペアにした
・同様に類似性が非常に高いとペア間で異なった形式同士(画像と文章)をペアにした
2.Crisscrossed Captionsの作り方
以下、ai.googleblog.comより「Crisscrossed Captions: Semantic Similarity for Images and Text」の意訳です。元記事の投稿は2021年5月6日、Zarana ParekhさんとJason Baldridgeさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Robert Bye on Unsplash
ランダムに画像とキャプションのペアを選択しても類似していない可能性が高いため、類似性が高いと予想される新しいペアを少なくともいくつか含むペアを抽出し、抽出したペアを人が評価する手法を考え出しました。
類似ペアを検索するために特定のモデルに依存する事を減らすために、間接サンプリング手法(後述)を使います。この手法では、異なるエンコード方法を使用して画像とキャプションをエンコードし、同じ形式間の類似性を計算して、類似性行列を作成します。
画像はGraph-RISE embeddingsを使用してエンコードされますが、キャプションは、Universal Sentence Encoder(USE)とGloVe embeddingsに基づく平均的なbag-of-words(BoW)手法を使用してエンコードされます。各MS-COCOのサンプルには5つのコキャプションがあるため、コキャプションのエンコーディングからサンプル毎に平均して1つの特徴表現を作成し、全てのキャプションペアを画像ペアにマッピングできるようにします。(同じ形式同士のペア選択方法については以下で詳しく説明します)
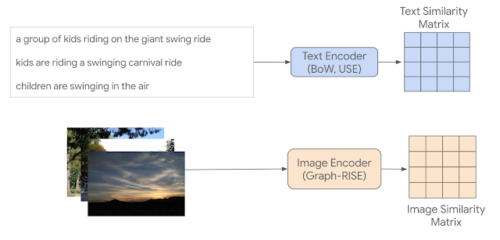
上:平均化されたコキャプションエンコーディングを使用して構築されたテキストの類似性配列(各セルが類似性スコアに対応)。
したがって、各テキストエントリは単一の画像に対応し、5kx5kマトリックスになります。2つの異なるテキストエンコーディング方法が採用されましたが、簡単にするために1つのテキスト類似性マトリックスのみを表示しています。
下:データセット内の各画像の画像類似性マトリックス。結果は5kx5kマトリックスになります。
間接サンプリング手法の次のステップは、計算された画像類似性を使用して、人間が評価を行うためにキャプションのペアをサンプリングするために使用することです(またはその逆)。
例えば、テキストの類似性配列から計算された類似性の高い2つのキャプションを選択し、それぞれの画像を取得します。その結果、外観は異なりますが、テキストが描写している画像が類似している新しい画像のペアが生成されます。例えば、「恥ずかしそうに横を向いている犬」や「黒い犬が頭を横に持ち上げてそよ風を楽しんでいる」というキャプションは、モデルの類似性がかなり高いため、下の図の2匹の犬の対応する画像は 画像の類似性評価のために選択することができます。
このステップでは、類似性が高いと計算された2つの画像を使って、新しいキャプションのペアを生成することもできます。つまり、人間が評価を行いために、形式同士の新しいペア(少なくとも一部は非常に類似しています)を間接的にサンプリングしています。
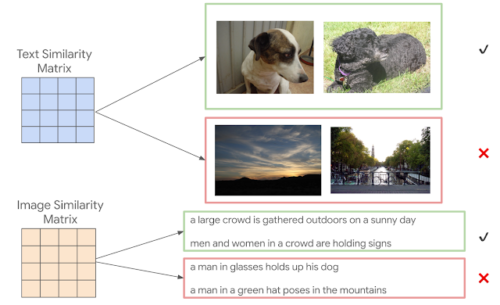
上:計算されたキャプションの類似性に基づいて、画像のペアが選択されます。
下:キャプションのペアは、それらが説明する画像の計算された類似性に基づいて選択されます。
最後に、これら形式同士の新たなペアとその人間による評価を使用して、人間による評価を行うために異なった形式同士の新しいペアを選択します。
これを行うには、既存の画像とキャプションのペアを使用して形式間(intermodality)をリンクします。たとえば、キャプションペアの例(i, j)が人間によって非常に類似していると評価された場合、例iから画像を選択し、例jからキャプションを選択して、人間による評価を行うための新しい形式間ペアを取得します。また、サンプリングには、類似性が最も高い形式間ペアを使用します。これには、類似性が高い新しいペアが少なくともいくつか含まれているためです。 最後に、既存のすべての形式間ペアとコキャプションの大規模なサンプルに対する人間による評価も追加します。
以下の表は、各評価に対応するSISとSITSのペアの例を示しています。5が最も類似しており、0が完全に類似していません。






SIS(中央列)およびSITS(右)タスクに基づ人間由来の類似性スコア
(左列の番号は5が非常に類似、0は完全に非類を意味しています)
これらの例は説明を目的としたものであり、CxCデータセットには含まれていないことに注意してください。
3.Crisscrossed Captions:画像とテキストの意味的類似性の探求(2/3)関連リンク
1)ai.googleblog.com
Crisscrossed Captions: Semantic Similarity for Images and Text
2)www.aclweb.org
Crisscrossed Captions: Extended Intramodal and Intermodal Semantic Similarity Judgments for MS-COCO
3)github.com
google-research-datasets / Crisscrossed-Captions
