
1.自動進化する強化学習でDDQNを凌駕する(2/2)まとめ
・発見されたアルゴリズムの中でDQNRegとDQNClippedが優れたパフォーマンスを出した
・これらはDQNが一般的にQ値を過大評価してしまう事を各々の方法で回避している
・進化の元ネタとしてDQNを与えるとこれら2つのアルゴリズムが一貫して出現した
2.DQNRegとDQNClipped
以下、ai.googleblog.comより「Evolving Reinforcement Learning Algorithms」の意訳です。元記事の投稿は2021年4月22日、John D. Co-ReyesさんとYingjie Miaoさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Varshesh Joshi on Unsplash
学習したアルゴリズム
発見されたアルゴリズムの中で優れた一般化パフォーマンスを示した事例を2つ、以下で説明します。
1つ目はDQNRegで、通常の2乗ベルマンエラーにQ値の加重ペナルティを追加することでDQNに基づいています。
2つ目に学習した損失関数DQNClippedはより複雑ですが、その主要項(Dominant Term)は単純な形式、つまりQ値の最大値とベルマン誤差の2乗(定数を法として)です。
どちらのアルゴリズムも、Q値を正則化する方法と見なすことができます。DQNRegはソフト制約を追加しますが、DQNClippedは、Q値が大きくなりすぎた場合に、Q値を最小化する一種の制約付き最適化として解釈できます。Q値を過大評価することが潜在的な問題である場合、この学習された制約がトレーニングの初期段階で始まることを示します。この制約が満たされると、損失は代わりに元の2乗ベルマンエラーを最小化します。
綿密な分析によると、DQNのような比較対象手法は一般的にQ値を過大評価していますが、今回学習したアルゴリズムはさまざまな方法でこの問題に対処しています。 DQNRegはQ値を過小評価しますが、DQNClippedは、過大評価せずにゆっくりと真の値に近づけるという点で、double dqnと同様の動作をします。
進化の元ネタとしてDQNを与えると、これら2つのアルゴリズムが一貫して出現する事は指摘する価値があります。ゼロから学習させると本手法は、TDアルゴリズムを再発見します。
完全を期すために、進化中に発見された上位1000の実行アルゴリズムのデータセットをgithubで公開しています。好奇心旺盛な読者は、これらの学習された損失関数の特性をさらに調査することができます。
過大評価された値は、一般的に値ベースのRL(value-based RL)の課題です。
私達の手法は、Q値を正則化して過大評価を減らすアルゴリズムを見つけて学習します。
学習したアルゴリズムの一般化パフォーマンス
通常、RLにおける一般化とは、様々なタスクに対して一般化するトレーニング済みのポリシーを指します。
ただし、本研究では、アルゴリズムの一般化パフォーマンスに関心があります。これは、一連の環境でアルゴリズムがどの程度うまく機能するかを意味します。
一連の古典的な制御環境では、学習したアルゴリズムは、密な報酬タスク(CartPole、Acrobot、LunarLander)で比較対象手法と一致し、よりまばらな報酬タスクであるMountainCarでDQNよりも優れています。
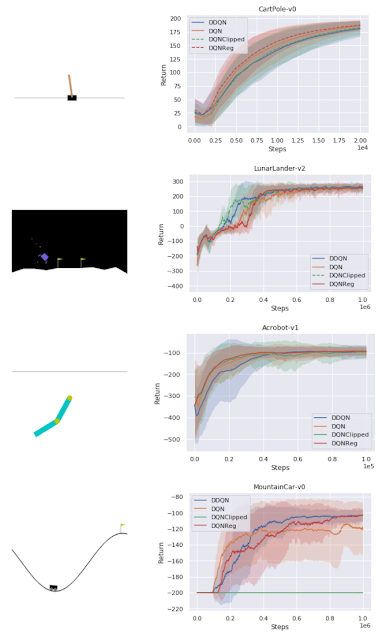
学習したアルゴリズムと従来のアルゴリズムのパフォーマンス比較
様々な異なるタスクをテストする一連のスパース報酬MiniGrid環境では、サンプルの効率と最終的なパフォーマンスの点で、DQNRegがトレーニング環境とテスト環境の両方で比較対象手法を大幅に上回っています。実際、その効果は、サイズ、構成、ゲーム内に出現する新たな障害物の存在など、異なるテスト環境でより顕著になります。
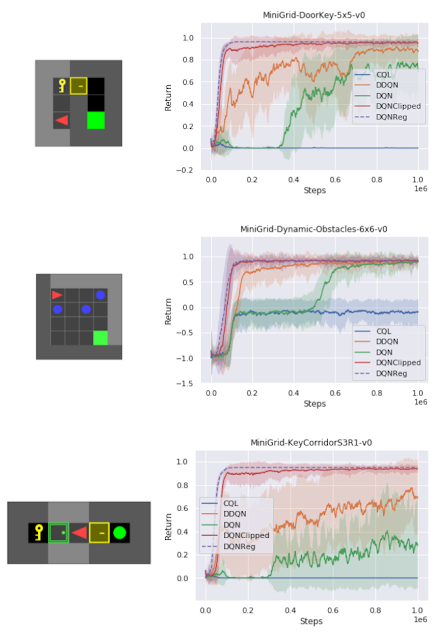
トレーニング環境のパフォーマンスとトレーニングステップの関係
DQNRegは、サンプル効率と最終的なパフォーマンスにおいて、比較対象手法に匹敵するか、上回ることができます。
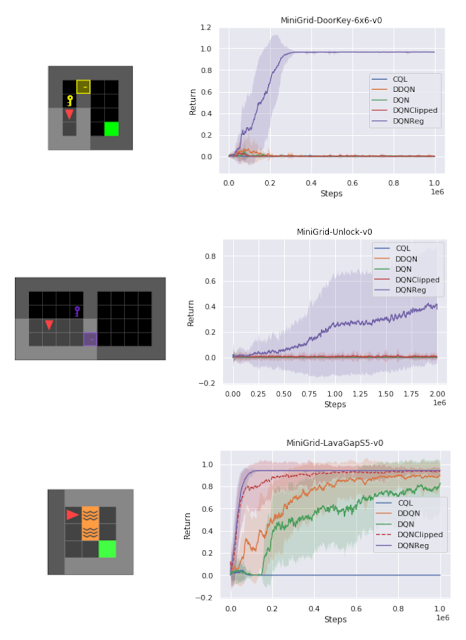
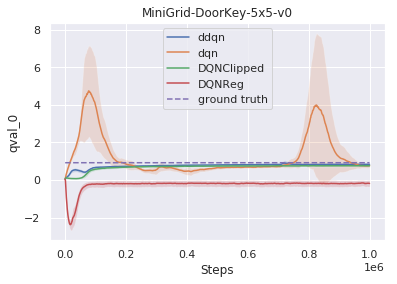
DQNRegは、初見のテスト環境で比較対象手法を大幅に上回る事ができます。
いくつかのMiniGrid環境で、通常のDDQNと学習したアルゴリズムであるDQNRegのパフォーマンスを視覚化しました。これらの環境の開始位置、壁の構成、および物体の構成は、リセットのたびにランダム化されるため、エージェントは単に環境を記憶するのではなく、一般化する必要があります。
DDQNは意味のある動作を学習するのに苦労することがよくありますが、DQNRegは最適な動作を効率的に学習できます。
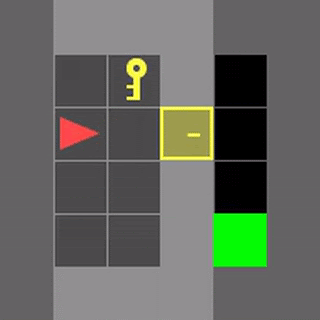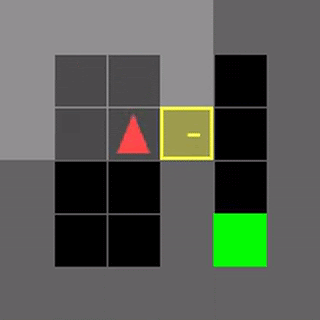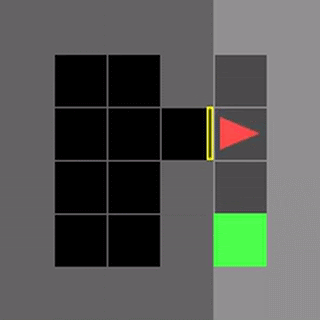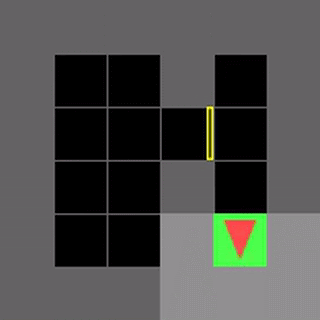


DDQN
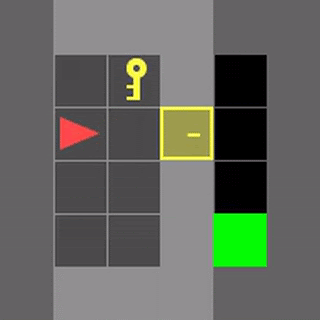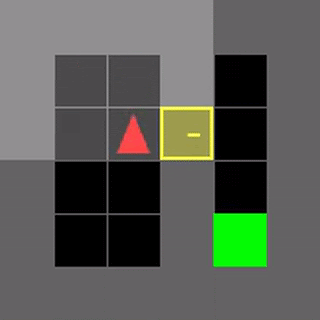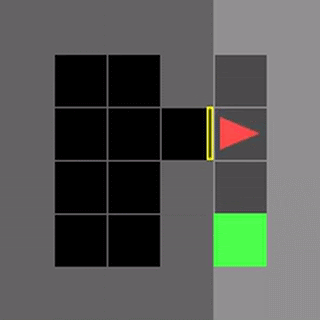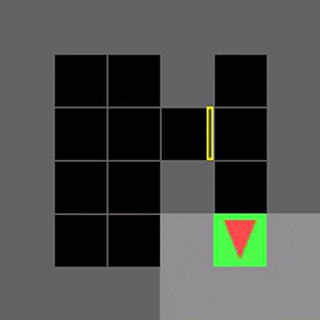


DQNReg
画像ベースのAtari環境でもパフォーマンスの向上が見られました。トレーニングが非画像ベースの環境で行われた場合であってもです。
これは、一般化可能なアルゴリズム表現を使用した安価で多様なトレーニング環境のセットでのメタトレーニングが、根本的なアルゴリズムの一般化を可能にする可能性があることを示唆しています。

| Env | DQN | DDQN | PPO | DQNReg |
| Asteroid | 1364.5 | 734.7 | 2097.5 | 2390.4 |
| Bowling | 50.4 | 68.1 | 40.1 | 80.5 |
| Boxing | 88 | 91.6 | 94.6 | 100 |
| RoadRunner | 39544 | 44127 | 35466 | 65516.0 |
いくつかのAtariゲームの比較対象手法に対する、学習したアルゴリズムDQNRegのパフォーマンス
パフォーマンスは、100万ステップごとに200回以上のテストエピソードで評価されます。
結論
本投稿では、損失関数を計算グラフとして表現し、この表現を介してエージェントの母集団を進化させることにより、新しい解釈可能なRLアルゴリズムを学習する方法について説明しました。
計算グラフの定式化により、研究者は人間が設計したアルゴリズムに基づいて構築し、既存のアルゴリズムと同じ数学的ツールセットを使用して学習したアルゴリズムを研究することができます。学習したアルゴリズムのいくつかを分析し、それらをエントロピー正則化の形式で解釈して、値の過大評価を防ぐことができます。これらの学習されたアルゴリズムは、ベースラインを上回り、初見の環境に一般化する可能性があります。最高のパフォーマンスを発揮するアルゴリズムは、更なる分析研究に利用できます。
今後の研究が、actor criticアルゴリズムやオフラインRLなどのより多様なRL設定にまで及ぶことを願っています。更に、この作業が機械支援アルゴリズムの開発につながることを願っています。計算メタ学習(computational meta-learning)は、研究者が学習したアルゴリズムを追求して自分の作業に組み込むための新しい方向性を見つけるのに役立ちます。
謝辞
共著者のDaiyi Peng, Esteban Real, Sergey Levine, Quoc V. Le, Honglak Lee, そして Aleksandra Faustに感謝します。また、論文に関する有益な初期の議論とフィードバックを提供してくれたLuke Metz、関連する研究アイデアに関する初期の議論をしてくれたHanjun Dai、インフラストラクチャを支援してくれたXingyou Song、Krzysztof Choromanski、Kevin Wu、環境選択を支援してくれたJongwook Choiにも感謝します。
最後に、この投稿のアニメーションをデザインしてくれたTom Smallに感謝します。
3.自動進化する強化学習でDDQNを凌駕する(2/2)関連リンク
1)ai.googleblog.com
Evolving Reinforcement Learning Algorithms
2)arxiv.org
Evolving Reinforcement Learning Algorithms
3)github.com
jcoreyes / evolvingrl

