
1.PAIRED:3つのエージェントを使って強化学習の効率を向上(2/2)まとめ
・強化学習のシミュレーション環境を多様化して現実への転移を容易にする手法が求めらている
・トレーニング環境を自動的に作成する教師なし環境デザイン(UED)は1つの解決策
・PAIREDは与えられるタスクが段々と困難になるためUEDにとって理想的な手段となる
2.PAIREDの性能
以下、ai.googleblog.comより「PAIRED: A New Multi-agent Approach for Adversarial Environment Generation」の意訳です。元記事の投稿は2021年3月5日、Natasha JaquesさんとMichael Dennisさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Juliana Amorim on Unsplash
前項で説明した方法(ドメインのランダム化、ミニマックス後悔法、PAIRED)は、同じ理論的フレームワークである教師なし環境設計(UED:Unsupervised Environment Design)を使用して分析できます。これについては、論文内で詳しく説明しています。UEDは環境設計と決定理論の関係を描き、ドメインのランダム化が不十分な理由の原則と同等であり、ミニマックス敵対法がマキシミン原理(Maximin Principle)に従い、PAIREDがミニマックス後悔法(minimax regret)を最適化していることを示すことができます。この定式化により、決定理論のツールを使用して、各方法の利点と欠点を理解できます。
以下に、これらの各アイデアが環境デザインでどのように機能するかを示します。
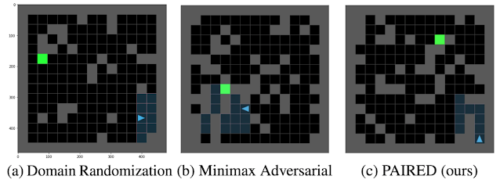
ドメインのランダム化(a)は、エージェントの学習の進行に合わせて調整されていない非構造化環境を生成します。ミニマックス敵対法(b)は、不可能な環境を作り出す可能性があります。PAIRED(c)は、挑戦的で構造化された環境を生成しますが、それでもエージェントが解決することが可能です。
カリキュラムの生成
ミニマックス後悔法について興味深いのは、最初は簡単で、その後、次第に困難になるように環境を構築してカリキュラムを生成するように敵対者を動機付けることです。
ほとんどのRL環境では、報酬関数は、タスクをより効率的に、またはより少ないタイムステップで完了するとより高いスコアを提供します。これが本当である場合、後悔が敵対者を動機付けて、主人公がまだ解決できない最も簡単な環境を作成することを示すことができます。
これを確認するために、競争者が完璧であり、常に可能な限り最高のスコアを取得すると仮定しましょう。その場合、主人公はヒドイ状況です。全てでゼロのスコアを取得します。こうなると、後悔は環境の難しさにかかっています。
より簡単な環境はより少ないタイムステップで完了することができるので、それらは競争者がより高いスコアを得るのを可能にします。従って、簡単な環境で失敗した後悔は、難しい環境で失敗した後悔よりも大きくなります。
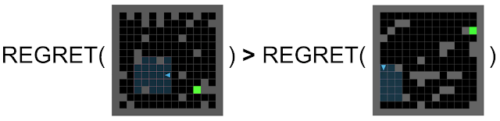
後悔を最大化することによって、敵対者は主人公が解決できない簡単な環境を探します。主人公が各環境を解決することを学んだら、敵対者は主人公が解決できない少し難しい環境を見つけることに移らなければなりません。従って、敵対者は次第に困難なタスクのカリキュラムを生成します。
結果
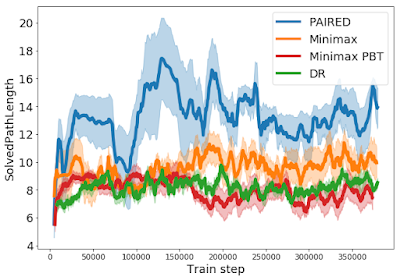
以下の学習曲線にカリキュラムが表示されています。これは、エージェントが正常に解決した迷路の最短経路の長さをグラフ化したものです。ミニマックスやドメインのランダム化とは異なり、PAIREDの敵対者は、ますます長くなるが解決できる可能性のある迷路のカリキュラムを作成し、PAIREDエージェントがより複雑な行動を学習できるようにします。
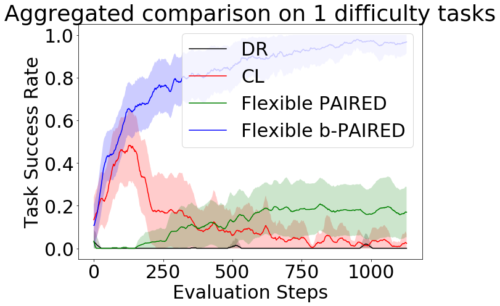
しかし、これらの異なるトレーニング手法は、エージェントが未知のテストタスクによりよく一般化するのに役立ちつのでしょうか?
以下に、一連の困難なテストタスクでの各アルゴリズムのゼロショット転移パフォーマンスを示します。転移環境の複雑さが増すにつれて、PAIREDと比較対象手法の間のパフォーマンスの差が広がります。ラビリンス(Labyrinth)やメイズ(Maze)のような非常に難しいタスクの場合、PAIREDは時々タスクを解決できる唯一の手法です。これらの結果は、PAIREDを使用して深層強化学習の一般化を改善できるという有望な証拠を提供します。

確かに、これらの単純な格子迷路の世界では、多くのRLメソッドが解決しようとしている実際のタスクの複雑さを反映していません。これについては、「Adversarial Environment Generation for Learning to Navigate the Web」で取り上げています。
これは、RLエージェントにWebページを操作するように教えるなど、より複雑な問題に適用した場合のPAIREDのパフォーマンスを調べています。PAIREDの改良版を提案し、それを使用して敵対者を訓練し、段々と困難になるWebサイトのカリキュラムを生成する方法を示します。

上記では、トレーニングの初期、中期、後期に敵対者によって構築されたWebサイトを見ることができます。これらのウェブサイトは、ページあたりの使用要素が非常に少ない状態から多数の要素を同時に使用するようになり、タスクが次第に難しくなります。このカリキュラムでトレーニングされたエージェントが、標準化されたWebナビゲーションタスクに一般化でき、75%の成功率を達成できるかどうかをテストし、従来の最強のカリキュラム学習手法と比較して4倍の改善を実現します。
結論
Deep RLは、シミュレートされたトレーニング環境で実行する事に非常に優れていますが、現実世界の複雑さをカバーするシミュレーションをどのように構築できるでしょうか?
1つの解決策は、このプロセスを自動化することです。トレーニング環境の分布を自動的に作成するためのさまざまな方法を説明するフレームワークとして教師なし環境デザイン(UED:Unsupervised Environment Design)を提案し、UEDがドメインランダム化やミニマックス敵対的トレーニングなどの以前の作業を包含していることを示しました。
PAIREDはUEDにとって良いアプローチだと思います。後悔の最大化(regret maximization)は段々と困難なタスクのカリキュラムにつながり、エージェントが未知のテストタスクに正常に転移できるように準備できるためです。
謝辞
「Emergent Complexity and Zero-shot Transfer via Unsupervised Environment Design」の共著者であるMichael Dennis, Natasha Jaques, Eugene Vinitsky, Alexandre Bayen, Stuart Russell, Andrew Critch, そして Sergey Levineに感謝します。
また「Adversarial Environment Generation for Learning to Navigate the Web」の共著者であるIzzeddin Gur, Natasha Jaques, Yingjie Miao, Jongwook Choi, Kevin Malta, Manoj Tiwari, Honglak Lee, Aleksandra Faustにも感謝します。
加えて、Michael Chang, Marvin Zhang, Dale Schuurmans, Aleksandra Faust, Chase Kew, Jie Tan, Dennis Lee, Kelvin Xu, Abhishek Gupta, Adam Gleave, Rohin Shah, Daniel Filan, Lawrence Chan, Sam Toyer, Tyler Westenbroek, Igor Mordatch, Shane Gu, DJ Strouse, and Max Kleiman-Weinerに、本作業に貢献するディスカッションを行ってくれた事を感謝します。
3.PAIRED:3つのエージェントを使って強化学習の効率を向上(2/2)関連リンク
1)ai.googleblog.com
PAIRED: A New Multi-agent Approach for Adversarial Environment Generation
2)arxiv.org
Emergent Complexity and Zero-shot Transfer via Unsupervised Environment Design
Adversarial Environment Generation for Learning to Navigate the Web
3)github.com
google-research/

