
1.データサイエンティスト向けPython仮想環境ガイドまとめ
・機械学習モデルを開発する際は他の人が作ったライブラリ等を利用させて貰う事が多い
・他の人が作ったライブラリは特定のVersionのpythonやライブラリを必要とする場合がある
・仮想環境を使うと特定のVersionのpythonを複数用意して切り替える事ができるようになる
2.Pythonの仮想環境の解説
以下、towardsdatascience.comより「A Data Scientists Guide to Python Virtual Environments」の意訳です。元記事の投稿は2021年1月10日、Rebecca Vickeryさんによる投稿です。
Pythonで人工知能/機械学習関係のモデルやスクリプトを作成する際は、外部のライブラリ/モジュール/パッケージ/学習済みモデル等をpipコマンド等でインストールして使用する事が多いのですが、これらは特定のバージョンのPythonや特定のバージョンのライブラリがインストールされていないと正常に動作しない事が良くあります。
そのため、不用意にPythonやライブラリを最新版にアップデートしてしまうと、こういった依存関係が壊れてしまい、今まで動いていたモデルやスクリプトが動かなくなってしまう事が良くあるのです。
こういった自体を避けるために「バージョンやライブラリ構成を固定したPythonの開発環境を複数用意して、場合によって使いわけたい」と言う要望が出てきて、これが「仮想環境」と言う考え方に繋がります。
Pythonの仮想環境構築ツールは本記事で言及されているように3つが群雄割拠してます。
通常であれば何か一つ自分にとって最適と感じたものに習熟すれば十分なのですが、モデルやライブラリ等が特定の仮想環境を利用している事を前提とした形式で提供されているケースもあり、そういった場合はそこで使われている仮想環境構築用のツールが何かを把握して対応する必要が出てきます。そのため、3つ全部を覚える必要はありませんが、キーワードだけでも覚えておくと、いつの日か役に立つ可能性があります。
なお、3つの仮想環境構築ツールを自分のPCに全てインストールして平行利用するのはpath等の設定で思わぬトラブルの元になる事が多いので、仮想環境構築ツールを導入する部分も含めてColaboratory化やJupyter notebook化してプロジェクト単位でまとめてしまうのがベターなのかなと思っています。
更に余談ですが、本投稿で解説されているツールはPythonの開発環境を仮想化するツールです。OSやミドルウェアなども含めて丸ごと仮想化するツールとしてはVagrantやDockerなどが有名で、データパイプラインやMLOpsなどの本格的なインフラを構築する際はこれらのツールの導入を検討した方が良いと思います。
アイキャッチ画像はPython(ニシキヘビ)でクレジットはPhoto by Jan Kopřiva on Unsplash
Pythonの仮想環境とは?
仮想環境とは何でしょうか?選択肢には何があるのでしょうか?そしてなぜそれらが必要なのでしょうか?
プログラミング言語のPythonには様々なバージョンがあります。
同様に、すべてのPythonライブラリにも複数のバージョンがあり、ライブラリは特定のバージョンのPythonで動作し、更にそれらを動かすためには特定のライブラリやパッケージが必要になります。これは一連の依存関係として知られています。
あなたが実行する全てのデータサイエンスプロジェクトには、独自のサードパーティが開発したPythonパッケージのセットが必要になる可能性があります。仮想環境は、Pythonのバージョンとプロジェクトの全ての依存関係をカプセル化する自己完結型の環境として機能します。
新しい仮想環境の作成は、新しいデータサイエンスプロジェクトを開始するときに通常実行される最初のステップの1つです。
これらの環境は、プロジェクトの依存関係を整理し、自分のマシンに自己完結させるのに役立つだけではありません。また、プロジェクトを人々の間で簡単に共有できるようにします。仮想環境は、これらすべてのプロジェクトの依存関係に関する情報を保持します。他の人がプロジェクトを自分のPCにダウンロードすると、この情報を使用して、プロジェクトを動かすために必要な環境を正確に再現できます。
Python仮想環境構築入門
Pythonの仮想環境に関しては、いくつかの選択肢があります。各ツールには、独自の長所と短所があります。データサイエンティストとして、あなたは最終的にあなた自身の個人的な好みのオプションを見つける可能性があります。(私の場合はpipenvです)ただし、働いている会社やチームによっては、職業生活の中でいくつかを使用する場合があります。従って、利用可能な主要なツールを理解しておくと便利です。
この記事では、Python仮想環境を作成するための3つの主要なツールを紹介し、それらの使用方法を簡単に紹介します。このチュートリアルに従うには、Pythonとpipがすでにインストールされていることを確認する必要があります。 これを行うには、コマンドラインから次のコマンドを実行します。
python --version pip --version
Pythonをまだインストールしていない場合は、Webサイト「python-guideja.readthedocs.io」のインストールガイドに、私が見つけた中で最良のpythonインストール手順が記載されているので参考にしてください。本投稿に記載されているすべてのコード例は、ターミナル(コマンドライン, CMD)から実行することを目的としています。
Venv
Venvは、プログラミング言語Pythonに標準で付属している軽量の仮想環境を作成するためのモジュールです。Python 3がインストールされている場合、このツールを使用するために特別なものをインストールする必要はありません。
venvの使用方法
新しい環境を作成するには、最初にプロジェクトを保存するディレクトリを作成する必要があります。ターミナルからで次のコマンドを実行します。
mkdir myproject && cd myproject
次に、このディレクトリ内に仮想環境を作成します。 my_venvという単語を仮想環境名前を表します。貴方は別の名前を指定する事ができます。
python3 -m my_venv env
デフォルトでは、これにより最新バージョンのPythonで仮想環境が作成されます。 これを書いている時点では3.7でした。 ただし、特定のPythonバージョンが必要な場合は、以下に示すように指定できます。
python3.5 -m venv env
このツールは、以下に示すような構造を持つenvという新しいディレクトリを作成します。
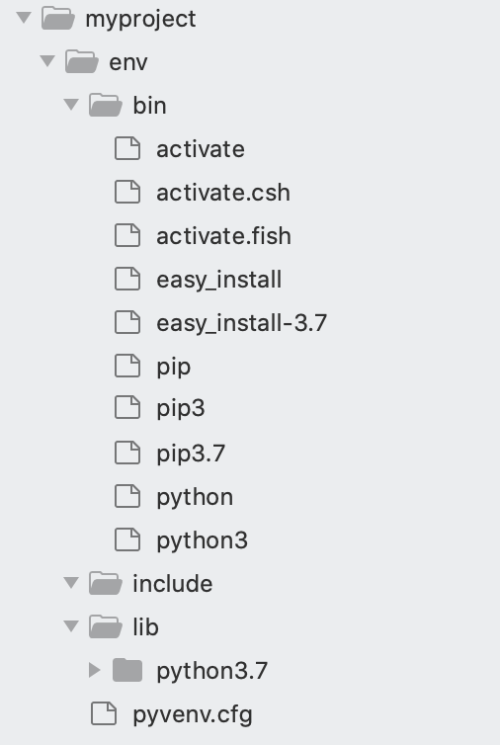
次のステップは、環境をアクティブ化することです。
source env/bin/activate
これで、ターミナルに次のように表示されます。
![]()
プロジェクトでの作業が終了したら、環境を非アクティブ化するには、実行するだけです。
deactivate
新しいパッケージは、pipを使用してアクティブ化された仮想環境にインストールできます。 以下のコードは、pandas を環境にインストールします。
pip install pandas
pandasパッケージとその依存関係が仮想環境のsite-packagesフォルダーにインストールされていることがわかります。
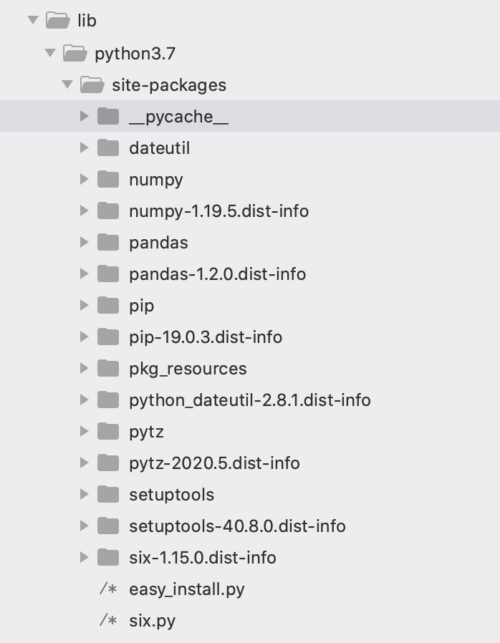
他の人が仮想環境を再現できるようにするには、使用されたすべてのサードパーティパッケージとそのバージョンを記録する方法が必要です。venvでこれを行う最も簡単な方法は、プロジェクトのルートディレクトリに新しい要件ファイルを作成することです。
これを行うには、以下を実行します。
pip freeze > requirements.txt
pip Freezeコマンドは、環境にインストールされているすべてのサードパーティパッケージとバージョンを一覧表示します。
次に、この出力がrequirements.txtという新しいファイルに書き込まれます。この要件ファイルを他の人が使用して、プロジェクトの実行に必要な正確な環境を再作成できるようになりました。 別のユーザーは、プロジェクトをダウンロードし、venvを使用して独自の環境を作成し、要件ファイルを使用して必要なすべてのパッケージをインストールできます。
pip install -r requirements.txt
Pipenv
Pipenvは、よりスマートで、より機能豊富で、より安全な方法を提供するPython仮想環境を作成するもう1つのツールです。Pipenvは、pipfileと呼ばれるものを介してプロジェクトの依存関係を自動的に管理します。手動でrequirements.txtファイルを作成して維持する必要はなく、pipenvは仮想環境の作成時にpipfileを作成し、サードパーティ製のライブラリのインストールまたはアップグレード時に更新します。
さらに、新しいpipenv仮想環境が作成されると、pipfile.lockというファイルも生成されます。上で説明したように、多くのサードパーティ製のライブラリは、他のライブラリの特定のバージョンに依存しています。これらは相互依存(interdependencies)として知られています。pipfile.lockファイルは、これらの相互依存関係の記録を保持し、プロジェクトを壊す可能性のある特定のパッケージが自動的にアップグレードされないようにします。
macOSを使用している場合にpipenvをインストールする最良の方法は、Homebrewを使用することです。これにより、pipenvとそのすべての依存関係が分離された仮想環境にインストールされ、Pythonのインストールに干渉しなくなります。または、pipを介してインストールすることもできます。
brew install pipenv
#または
pip install pipenv
pipenvの使用方法
pipenvの使用を開始するには、最初にプロジェクトディレクトリを作成または複製します。以下ではプロジェクトディレクトリの名前をmypipenvprojectとして作業を進めます。
mkdir mypipenvproject && cd mypipenvproject
次に、以下を実行して、pipenv環境をインストールします。 pipenv環境は、プロジェクトディレクトリと同じ名前になります。
pipenv install
特定のPythonバージョンを使用して環境を作成する場合は、以下のコマンドを使用できます。
pipenv install --python 3.6
これにより、仮想環境が構築され、pipfileおよびpipfile.lockファイルが作成されます。作成した環境に切り替える(アクティブ化)には、次のコマンドを入力するだけです。
pipenv shell
パッケージ/ライブラリをインストールするには、以下のコマンドを実行します。
pipenv install package-name # 例、pandasのインストール pipenv install pandas
ここまで実行してpipfileを開くと、以下の行が追加されていることがわかります。pandasの特定のバージョンをインストールした場合、そのバージョンはこのファイルに記述されます。
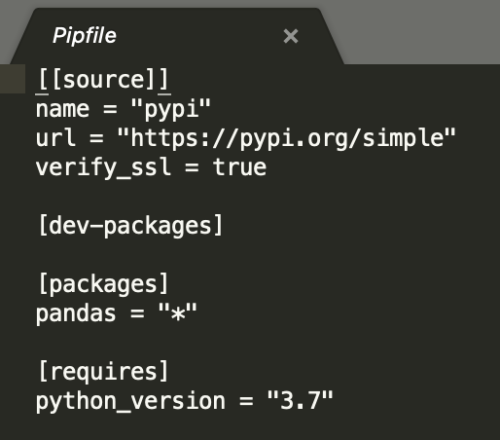
pipenv仮想環境を終了するには、exitと入力するだけです。
あなたのプロジェクトを共有する方法
pipenvを使用すると、別のユーザーが自身のマシンでプロジェクトを再作成する場合に、プロジェクトのクローン/コピーを作成し、プロジェクトのホームディレクトリから次のコマンドを実行する事で再構築できます。
pipenv install pipenv shell
これにより、すべての依存関係がpipfileによりインストールされ、仮想環境に切り替わります。
Conda
Condaは、Python用のオープンソースのパッケージ管理および環境管理マネージャーです。これは、パッケージのインストールと環境の管理のために科学者達に人気のある選択肢です。従って、データサイエンスの仮想環境に関する本記事に含める価値があります。
Condaがインストールされているか不明な場合は、conda -Vを実行してこれを確認できます。詳細なインストール手順についてはdocs.conda.ioのInstallationガイドを参考にしてください。
condaを使用して仮想環境を作成するには、プロジェクトのホームディレクトリから次のコマンドを実行するだけです。
conda create -n myenvname python=3.7
作成した仮想環境myenvnameに切り替えるには以下のコマンドを実行します。
conda activate myenvname
パッケージ/ライブラリをインストールするには、以下のコマンドを実行します。
conda install -n myenvname package_name # 例、pandasのインストール conda install -n myenvname pandas
myenvnameから切り戻すには、以下を実行します。
conda deactivate
pipenvとは異なり、condaはプロジェクトを動かすために必要な条件を記載したファイルを自動的に作成してくれません。conda環境を他の人と共有したい場合は、明示的に作成する必要があります。これを行うには、以下を実行します。
conda list --explicit > spec-file.txt
これにより、condaがvenvにおけるrequirements fileと非常によく似たspec fileと呼ばれるファイルが生成されます。このファイルを使用して、以下を実行することで環境を再作成できます。
conda create --name my_new_envname --file spec-file.txt
まとめ
仮想環境は、データサイエンティストがプロジェクトを整理し、依存関係を分離し、他のユーザーとのコラボレーションを可能にするのに役立ちます。本投稿では、Python仮想環境で最も一般的な3つの選択肢について説明します。それらのそれぞれを試して、どちらが好ましい選択であるかを見つけることは価値があります。
再現可能なデータサイエンスプロジェクトを作成するためのベストプラクティスの詳細については、以前投稿した記事「A Recipe for Organising Data Science Projects」を参照してください。
読んでくれてありがとう!
3.データサイエンティスト向けPython仮想環境ガイド関連リンク
1)towardsdatascience.com
A Data Scientists Guide to Python Virtual Environments
A Recipe for Organising Data Science Projects
2)python-guideja.readthedocs.io
Python を正しくインストールする
3)docs.conda.io
Installation — conda

訳注:Condaは上の二つと少し立ち位置が変わっていてプログラミング言語python専属のコマンドではありません。科学技術計算用の開発言語やライブラリやエディター、ツールなどをあらかじめ同梱してGUIで簡単に操作できるようにしたAnacondaというソフトウェアがあり、condaはこのソフトウェア群に含まれているツールです。
AnacondaはGUIで操作が出来るのでWindowsユーザなど、コマンドラインの操作にあまり慣れていない方にとっては取っつきやすいのとRやJupyter notebookやpython用のエディターなど科学技術計算用に人気のある様々なソフトが一つにまとまっていて導入が容易なため人気があり、私も一番最初にPythonをインストールしたのはAnaconda経由でした。
Anacondaが使っている仮想環境構築用のコマンドがcondaなのですが、condaはライブラリ(パッケージ)のインストール時にも使われるコマンドなので、試したいと思っていたライブラリ/モデルのインストールマニュアルに「conda ~」のように記載されていた場合は、conda環境が暗黙の前提になっている可能性が高いです。その場合、pipコマンドで他のライブラリをインストールすると依存関係が壊れたりケースがあります。なるべくライブラリのインストールなどもcondaを使って作業した方がトラブルを避けやすくなります。