
1.独自データを使って物体検出モデルの精度を上げる方法(2020年版)まとめ
・2020年に物体検出モデルを再トレーニングしようとした時に取りうる選択肢の概要紹介
・物体検出用データのラベル付け、データ拡張、モデリングなどを具体的に紹介
・物体検出の分野ではAutoMLは取りうる選択肢の一つとして上げられるようになっている
2.2020年の主要なオブジェクト検出(Object Detection)モデル
以下、blog.roboflow.comより「The Ultimate Guide to Object Detection (December 2020)」の意訳です。元記事の投稿は2020年9月14日、Jacob Solawetzさんによる投稿です。
データ整備ツールを扱っているRoboflow社のブログ記事なので多少自社サービスに我田引水的な部分もあるかもしれませんが、現状を俯瞰的にまとめてくれてると思えたので意訳しました。
物体検出モデル以外もそうですが、現在はありがたい事に様々なトレーニング済みモデルが公開されており、そこそこ精度は高いのですが、独自データを扱わせるとイマイチ精度が落ちる場合があってやはり微調整なり転移学習なりをさせたくなり、そうすると独自データに物体検出用のラベルを効率的に付ける現時点で現実的な方法などを知りたくなると思うのですが、そんな時に選択肢を俯瞰するために役立つ内容です。
アイキャッチ画像のクレジットはPhoto by Stellan Johansson on Unsplash
物体検出(Object Detection)は、画像内の物体の場所特定して識別するコンピュータービジョンテクノロジーです。物体検出の応用の広さと多様性により、物体検出AIはここ数年で最も一般的に使用されているコンピュータービジョンテクノロジーになりました。
本の記事では、以下の題材を使用して、物体検出とは何か、および物体検出を自分自身で使用するための具体的な使い方について説明します。
(1)物体検出のしくみ
(2)物体検出の使用事例
(3)物体検出データのラベル付け
(4)物体検出のためのデータ拡張
(5)物体検出問題のモデリング
飛び込みましょう!
(1)物体検出のしくみ
良くある言い間違い
物体検出(Object detection)は、物体認識(object recognition)または物体識別(object identification)と呼ばれる事もあるのですが、これらの概念は同義語です。
ただし、物体検出は、「分類(classification、画像全体に単一のラベルを割り当てる)」、「キーポイント検出(画像内の関心のあるポイントを識別する)」、または「セマンティックセグメンテーション(画像内の物体を領域で切り分ける)」などの他の一般的なコンピュータービジョンテクノロジとは異なります。
使用するコンピュータビジョン用語の他の定義に興味がある場合は、コンピュータビジョン用語集を参照してください。
物体検出タスク
物体検出タスクは、画像内の物体の位置を特定し、これらの物体を分類対象に属するものとしてラベル付けします。
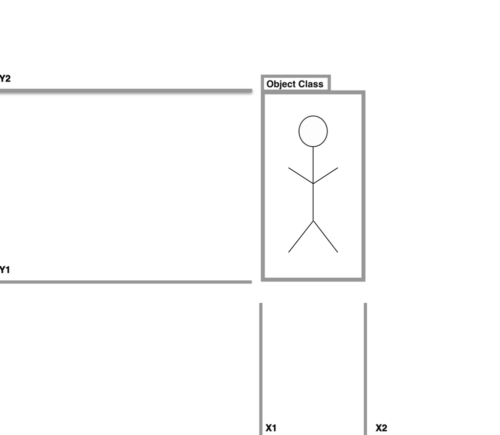
物体検出タスクのイメージ
物体検出モデルは、X1、X2、Y1、Y2座標および物体が属する分類クラスを予測することにより、この目標を達成します。アプリケーションで物体検出を使用するには、画像(またはビデオフレーム)を物体検出モデルに入力し、予測された座標とクラスラベルを含むJSON出力を受信するだけです。
物体検出器のモデリング
これらの予測を行うために、物体検出モデルは入力画像の画素から特徴表現を形成します。
画像の画素から特徴の形成
特徴表現形成後、画像内の画素の特徴表現は深層学習ネットワークに供給されます。
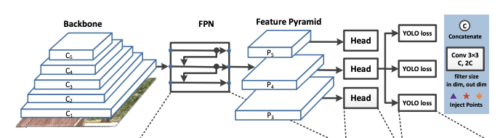
物体検出モデルの図
座標とクラスの予測は、一連のアンカーボックス(Anchor Box)からの差分として取得できます。
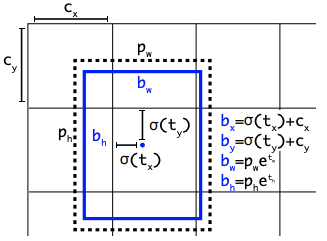
オブジェクト検出の予測は、アンカーボックスに基づいて行われます
物体検出モデルは、見せられたデータから学習します。従って、対象の物体を検出するように物体検出モデルをトレーニングするには、ラベル付きのデータセットを収集することが重要です。
(2)物体検出の使用事例
物体検出は、画像内の物体の位置を特定して識別するためにコンピュータビジョンが必要なあらゆる状況で役立ちます。物体検出は、物体と風景が多かれ少なかれ類似している状況で活躍します。
Roboflow社では、業界地図全体を俯瞰して物体検出の使用事例(ユースケース)を見てきました。以下にいくつかの例があります:
・ガソリン漏れ検出
・雑草検出
・ベルトコンベヤー上の埃検出
・魚の大きさ検出
・安全帽検出
・衛星画像を使った物体検出
・飛行機メンテナンス状態検出
・屋根の補修必要性有無検出
・寿司種別検出
一般的に、物体検出の使用事例は、以下のグループに分類できます。
・空中および地理空間画像からの検出(農業分野など)
・製造品質保証のための規格外製品検出
・異常検出
・安全と監視
・医療画像処理
・物体の数を数える
・自動運転車
その他のインスピレーションと例については、当社のコンピュータービジョンプロジェクトのショーケースをご覧ください。
(3)物体検出データのラベル付け
物体検出モデルをトレーニングするには、対象の物体に境界ボックスとそのボックスが何か説明するラベルが付いた、ラベル付きデータの資料をモデルに見せる必要があります。
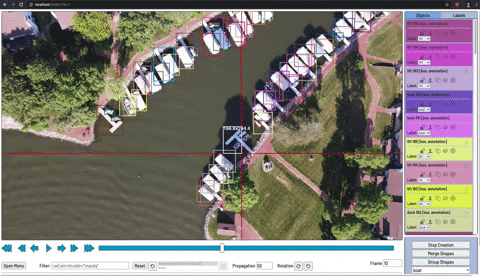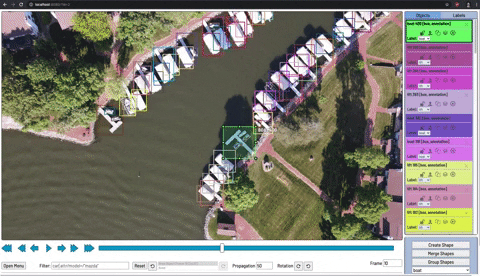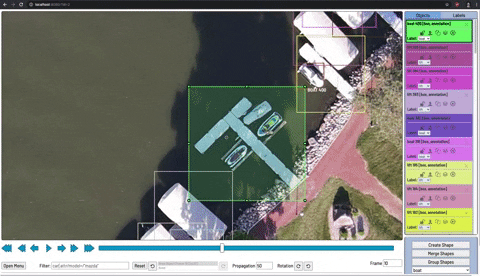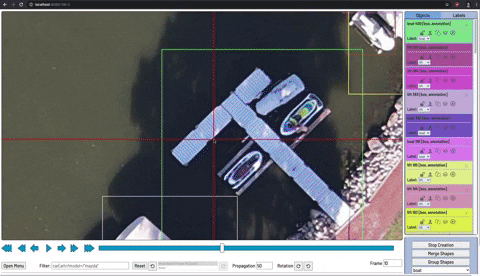
CVATを使った物体検出のための画像への注釈付け
画像への注釈付けは、手動またはサービスを介して実行できます。モデルのトレーニングを開始するためには、少なくとも10〜50枚程度の画像にラベルを付ける必要がある場合があります。ただし、それ以降もラベル付けされたデータを増やす事でモデルのパフォーマンスと一般化可能性が常に向上します。
画像に自分でラベルを付ける
自分で画像にラベルを付けることを選択した場合、活用できる無料のオープンソースのラベル付けツールがいくつかあります。
当社で紹介しているツールとガイドは次のとおりです。
・CVAT入門
・LabelImg入門
・VGG Image Annotator(VIA)入門
・LabelMe入門
・VoTT入門
また、最近、当社は以下のツールを発表した事に興奮しています。
・Roboflow Annotate
CVATまたはRoboflow Annotateをお勧めします。これらは、Webインターフェイスを備えた強力なツールであるため、プログラムをインストールする必要がなく、プラットフォームにすばやくアクセスして画像にラベルを付けることができます。
ラベル付けサービスを利用する
ラベリングサービスは、クラウドワーカーを活用して、データセットにラベルを付けます。あなたが非常に大きなデータにラベル付けする仕事をしているなら、これらの解決策はあなたのためかもしれません。
一部の自動ラベル付けサービスには、次のものが含まれます。
・AWS SageMaker Ground Truth
・Scale
・Labelbox
ラベル付け作業のベストプラクティス
データセットを収集するときは、モデルが将来直面する可能性のある問題を事前に考えることが重要です。
・検出したいすべてのタイプの物体の事例をたくさん含めるようにしてください。
・データセット内の環境の変化を制限することにより、物体検出タスクを簡素化できます。
・関心のある物体の境界ギリギリに境界ボックスを付与します。
・視線が遮蔽された物体であっても物体が完全に表示されているかのように境界ボックスラベルを付けます。
・画像の端で部分的に切り取られている物体にもラベルを付けます。
・始める前に概念化の明示的な仕様と構造(ontology)について考え、すべてのラベル付け作業者同じ視点で作業している事を確認してください。
(4)物体検出のためのデータ拡張
データ拡張(data augmentation)とは、利用可能なデータを水増しする事で、元となるトレーニングデータセットから派生画像を生成することなどが含まれます。

データ拡張を使って物体検出用のデータをより多く生成
当社で紹介しているツールとガイドは次のとおりです。
オブジェクト検出のためのデータ拡張入門
データ拡張戦略には、以下が含まれますが、これらに限定されません。
・画像を反転する事による水増し
・ぼかしを増強する事による水増し
・ランダムな切り抜きによる水増し
・ランダムに回転を加える事による水増し
・モザイクをデータに適用する事による水増し
もっと深く掘り下げたい場合は以下の記事を参照してください
・最先端のモデルでデータ拡張がどのように使用されるか?
(5)物体検出問題のモデリング
物体検出モデル
ラベル付けされたデータセットを取得し、データの水増しを行ったら、物体検出モデルのトレーニングを開始します。トレーニング時には、ラベル付けされたデータをバッチ単位でモデルに与え、モデルが予測を画像にマッピングする方法を繰り返し改善することが含まれます。
ラベリングと同様に、物体検出モデルを使用したトレーニングと推論には、2つのアプローチをとることができます。自分自身をトレーニングして展開するか、トレーニングおよび推論サービスを使用するかです。
独自の物体検出モデルをトレーニングする
Roboflowでは、Roboflow モデル ライブラリをホストしている事を誇りに思っています。モデルライブラリ内には様々なモデルアーキテクチャを使用してカスタムモデルをトレーニングおよびデプロイする方法に関するドキュメントとコードを見つける事ができます。
また、以下を含む独自の物体検出モデルをトレーニングする方法に関する一連の最高クラスの入門チュートリアルも公開しています。2020年11月の時点で、最適な物体検出モデルは次のとおりです。
・YOLOv5をトレーニングする方法
・YOLOv4をトレーニングする方法
・YOLOv3をトレーニングする方法
・Detectron2をトレーニングする方法
・EfficientDetをトレーニングする方法
すぐに使用できるようにするのが最も簡単なため、手始めにYOLOv5をトレーニングして開始することをお勧めします。iPhoneやiPadなどのAppleデバイスに展開する場合は、コードを書かずにトレーニング可能なツールであるCreateMLを試してみることをお勧めします。
独自のモデルをトレーニングすることは、物体検出予測エンジンを実際に使用するための良い方法です。しかし、より迅速に実装したい場合や、モデルのモデリングと展開に関連する無数の様々な作業やフレームワークをアウトソーシングする価値がある場合があります。
AutoMLオブジェクト検出トレーニングおよび推論サービス
物体検出モデルの構築と展開は複雑であるため、アプリケーション開発者は、物体検出プロセスのこの部分をAutoML(自動機械学習)ソリューションにアウトソーシングすることを選択できます。
Roboflowでは、物体検出タスクで一般的なAutoMLソリューションのベンチマークに時間を費やし、以下の記事にまとめました。
・主要ベンダーのCloud Vision AutoMLツールのベンチマーク
以下の製品を含みます。
・AWS Rekognition Custom Labels
・GCP AutoML Vision
・Azure Custom Vision
また、Roboflowで以下の自動トレーニングおよび推論ソリューションを開発しています。
・Roboflow Train
これらのサービスのいずれかを使用して、トレーニング画像を入力し、「トレーニング」ボタンをクリックします。トレーニングが完了すると、サービスは、画像を送信して予測を受信できるエンドポイントを立ち上げます。
エッジで動かす物体検出モデル
多くの使用事例で、物体をリアルタイム(例えば、30FPS以上の場合)で検出することがますます重要になっています。
エッジコンピューティングで物体検出モデルを実行する必要性をめぐって、次のような多くのハードウェアソリューションが登場しました。
・NVIDIA Jetson Nano
・Intel Neural Compute Stick
・OpenCV AI Kit
また、当社ではカスタムオブジェクト検出モデルをエッジにデプロイするためのガイドをいくつか公開しています。
・LuxonisOAK-1にカスタムモデルをデプロイ
・Luxonis OAK-Dにカスタムモデルをデプロイ
・YOLOv5を30FPSのJetsonXavierNXにデプロイ

ビデオ画像入力に行われる物体検出
コンピュータビジョンワークフロー
チームがコンピュータービジョンワークフローを標準化するために使用できるコンピュータービジョンパイプラインを設定することが重要です。これにより、注釈形式の変換、データセット品質の分析、画像の前処理、バージョン管理、 データセットを配布します。
幸い、Roboflowは、これらすべてを生成するコンピュータービジョンデータセット管理プラットフォームであるため、データ、ドメイン、およびモデルに固有の固有の課題に集中できます。
クラウドベースのコンピュータービジョンワークフローツールを無料で開始できます。
結論
物体検出は、画像内の物体の位置を特定して識別する強力な最先端のコンピュータービジョンテクノロジーです。
本記事では、画像のラベル付けから、画像の拡張、物体検出モデルのトレーニング、推論のための物体検出モデルの展開まで、物体検出ツールとテクノロジーの全範囲について説明しました。
私たちはあなたが楽しんだことを願っています。そしていつものように、幸せな検出を!
また、新しいモデルとテクニックが利用可能になると、この投稿を継続的に更新します。
また、このタイプのコンテンツにもっと興味がある場合は、コンピュータービジョンのビデオとチュートリアルのYouTubeチャンネルに登録してください。
3.独自データを使って物体検出モデルの精度を上げる方法(2020年版)関連リンク
1)blog.roboflow.com
The Ultimate Guide to Object Detection (December 2020)

