
1.GANのトレーニングに役立つ10のヒントまとめ
・GANのトレーニングが突然不安定になっても品質に留意しつつ続ける事が望ましい
・モード崩壊は低い学習率でトレーニングを最初からやり直すと上手く行く事がある
・スペクトル正規化はGANトレーニングの安定性に大いに役立つことが示されている
2.敵対的生成ネットワークのトレーニングを容易にするコツ
以下、towardsdatascience.comより「10 Lessons I Learned Training GANs for one Year」の意訳です。元記事の投稿は2019年7月29日、Marco Pasiniさんによる投稿です。
私を含むGAN、すなわち敵対的生成ネットワークのモード崩壊でお悩みの方向けのお話ですが、GANの入門者の方も先に読んで知っておくと非常に時間の節約になるありがたいお話です。モード崩壊を何度か経験すると早期停止したくなる病にかかるのは皆が通る道なのだと思います。
GANのモード崩壊をイメージしたアイキャッチ画像のクレジットはPhoto by Micah Williams on Unsplash
前書き
1年前、私はGenerative Adversarial Networks(GAN、敵対的生成ネットワーク)の世界への旅を始めることにしました。ディープラーニングに興味を持ち始めて以来、主にGANが生み出すことができる素晴らしい結果のために、私は常に彼らに興味をそそられてきました。
人工知能という言葉を思い浮かべると、GANは最初に頭に浮かぶ言葉の1つです。

GANによって生成された顔(StyleGAN)
しかし、最初のトレーニングを開始してすぐに、この興味深いアルゴリズムの両面を発見しました。GANのトレーニングは非常に困難です。はい、私は自分自身で試す前に、論文や自分より前に試した他の人々からそれを聞いていました。しかし、私はいつも、小さく簡単に克服できる問題を誇張しているのだと思っていました。
私は間違っていました。
入門者向けデータであるMNISTのサンプルとは異なるものを生成しようとするとすぐに、GANに影響を与える巨大な不安定性の問題が見つかり、解決策を見つけるために費やす時間が増えるにつれて、非常に煩わしくなってきます。
今、数え切れないほどの日を費やして既知の解決策を研究し、新しい解決策を考え出そうとした試行錯誤した結果、最終的に、私はGANプロジェクトの収束の安定性を少なくともより細かく制御できるようになったと言えます。そして、あなたもそうすることができます。
完全な収束(またはゲーム理論の言葉で言えば、ナッシュ均衡)を実現する10分間の解決策をお約束するものではありません。皆さんのプロジェクトで、GANの探求を少し簡単にし、時間もかからず、何よりも煩わしさを軽減するためのヒントとテクニックを紹介したいと思います。
2019年時点でのGAN
GANの誕生とその結果としての安定性の問題の発覚以来、多くの研究が行われてきました。現在、私達は収束を安定させる方法を提案している多くの論文を読む事ができますが、それらに加えて長くて難しい数学的証明があります。
更に、いくつかの実用的な手法と経験則的な手法がディープラーニングの世界で見いだされました。数学的な思考が背後にないこれらの証明されていないトリックは驚くほど非常に効果的であり、破棄してはならないことに気付きました。
安定性の向上に伴い、生成された画像のリアリズムにも大きな飛躍がありました。NvidiaのStyleGANとGoogleのBigGANの結果を見るだけで、GANがどこまで進んだかを実際に理解できます。

BigGANによって生成された画像
論文を読み、実践し、理論と実践の両方からこれらのテクニックの多くを読んで試したので、GANをトレーニングするときに考慮すべき、また考慮すべきではないヒントのリストを以下にまとめました。この複雑で退屈なテーマについて少しでも視点を深められることを望んでいます。
(1)安定性とモデル容量
最初の独立したGANプロジェクトを開始するとすぐに、トレーニングプロセスの早い段階で、ジェネレーターの損失が非常に高いのに、ディスクリミネーターの敵対的損失がゼロになることに気付きました。私はすぐに、一方のネットワークにはもう一方のネットワークに追いつくのに十分な「モデル容量(capacity)」(またはパラメーターの数)がないと結論付けました。そのため、畳み込み層にフィルターを追加するためにジェネレーターのアーキテクチャを急いで変更しましたが、驚いたことに、何も変わりませんでした。
ネットワークの容量の変化がトレーニングの安定性に与える影響をもう少し調べたところ、明らかな相関関係は見つかりませんでした。確かに何らかのつながりはありますが、始めたときに思っているほど重要ではありませんでした。
従って、トレーニングプロセスのバランスが崩れていて、容量の点で明らかに他のネットワークを上回っているネットワークがない場合は、主要なソリューションとしてフィルターを追加または削除することはお勧めしません。当然な事ですが、ネットワーク容量について強い確信が持てない場合、同じようなケースのシナリオで使用されているアーキテクチャの事例がないかをネット上で探してみる事ができます。
(2)早期停止
GANのトレーニングでよくあるもう1つの間違いは、ジェネレーターまたはディスクリミネーターの損失が急激に増加または減少するのを確認したらすぐにトレーニングを停止(Early Stopping)する事です。
私も何度もやりました。損失が急劇に増えるのを見てすぐに、トレーニング全体が台無しになったと感じ、それはハイパーパラメータが完全に調整されていない事が原因だと思いました。
後になってようやく、損失がほぼランダムに増減することがよくあり、それは何も悪いことではないことに気づきました。ジェネレーターの損失がディスクリミネーターの損失よりもはるかに高くても、いくつかの素晴らしい迫真に迫った結果を達成しました。これは完全に正常です。従って、トレーニングプロセスが突然不安定になった場合は、トレーニング中に生成された画像の品質に注意しながら、トレーニングをもう少し続けることをお勧めします。視覚的な理解は、損失の数値よりも意味がある場合が多いためです。
(3)損失関数の選択
GANのトレーニングに使用する損失関数は何を選択するのがベストでしょうか?
この質問は、すべての異なる損失関数がベンチマークされ、比較された最近の論文によって取り組まれました。いくつかの非常に興味深い結果が現れました。どうやら、どの損失関数を選択するかは実際には問題ではありません。他の関数よりも絶対的に優勢な関数はなく、GANはさまざまなケースで学習することができました。
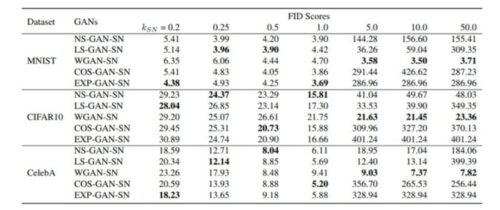
論文「How does Lipschitz Regularization Influence GAN Training?」より
従って、私の推奨事項は、最も単純な損失関数から始めて、より「限定的な手法」もしくは「最先端の手法」を選択肢として後回しにする事です。私達が文献から知る事が出来るように、それらを用いるとより悪い結果に終わる可能性が非常に高いためです。
(4)ジェネレーターとディスクリミネーターの重みの更新のバランス
多くのGANの論文、特に初期の論文では、実装のセクションで、著者がディスクリミネーターが1回更新するまでにジェネレーターが2回または3回更新するようにした事を読むことは珍しくありません。
私は最初の試みで、不均衡なトレーニングに気づきました。ディスクリミネーターネットワークがほぼ毎回もう一方を上回って(損失が大幅に減少している)いました。そして、有名な論文の著者でさえ同様の問題を抱えており、それを克服するために信じられないほど簡単な解決策を実行したことを読んで、私がやっている事は正しいと確信しました。
残念ながら、様々なネットワークのトレーニングのバランスを重みの更新を通じて取ることは、私の意見では非常に近視眼的な解決策です。
私のトレーニングを安定させるための最終的な解決策として、ジェネレータの重み更新頻度を変更しなければならなかった事はほとんどありませんでした。これにより「不安定性」を先送り出来る事もありましたが、収束に至る事はできませんでした。
この手法に効果がないことに気付いたとき、2つのネットワーク損失の現在の状態に基づいて重みの更新スケジュールを変更し、より動的にしようとさえ試みていました。後になってようやく、私はそのルートを登ろうとしているのは私だけではなく、他の多くの人たちと同じような事を試みて、不安定さを克服する事ができていなかった事がわかりました。
後述する他の手法が、トレーニングの安定性の向上にはるかに大きな影響を与えることを後で理解しました。
(5)モード崩壊と学習率
GANを扱っている場合は、モード崩壊(Mode Collapse)が何であるかを確実に知ることができます。
これは、ジェネレーターが崩壊する事であり、入力として供給される可能性のある全ての潜在ベクトルに対して常に単一の画像を生成します。これはGANトレーニングではかなり一般的な障害であり、場合によっては非常に煩わしいものになる可能性があります。

モード崩壊の例
このような状況に陥った場合に推奨する最も簡単な解決策は、GANの学習率を調整することです。私の個人的な経験では、この特定のハイパーパラメータを変更することで、この障害を常に克服できます。
経験則として、モード崩壊を処理するときは、低い学習率を使用して、トレーニングを最初からやり直してください。
学習率は、最も重要ではないにしても、最も重要なハイパーパラメータの1つです。これは、わずかな変化でもトレーニング中に根本的な変化を引き起こす可能性があるためです。通常、より大きなバッチサイズを使用すると、より高い学習率が利用可能になりますが、私の経験では、ほとんどの場合、保守的な選択肢を選んだ方が安全でした。
モード崩壊と戦う他の方法があります。例えば特徴一致(Feature Matching)やミニバッチ識別(Minibatch Discrimination)などです。私はいつも別の方法を見つけていたので、自分自身のコードにこれらを実装した事はありませんが、必要に応じて少し気にかけてください。
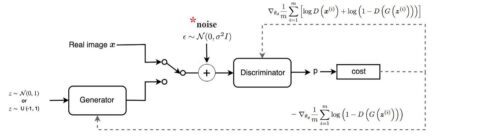
(6)ノイズの追加
ディスクリミネーターのトレーニングをより困難にすることが、全体的な安定性に有益であることはよく知られています。
ディスクリミネーターのトレーニングの複雑さを増すための最もよく知られている方法の1つは、実際のデータと合成データ(例えば、ジェネレーターによって生成された画像)の両方にノイズを追加することです。
数学的観点からは、これは2つの競合するネットワークのデータ分布にある程度の安定性を与えるのに役立つため、機能するはずです。これは、セットアップに最小限の労力しか必要とせずに、実際には非常にうまく機能するため(発生する可能性のある不安定性の問題を魔法のように解決しない場合であっても)、実際に試すことをお勧めする単純なソリューションです。そうは言っても、私はこのテクニックを使い始めた後にしばらくしてそれを断念し、私の意見ではより効果的に思えるテクニックを好んで使っています。
(7)ラベルスムージング
同じ目標を達成するためのもう1つの方法は、ラベルの平滑化(Label Smoothing)です。これは、理解と実装がさらに簡単です。実際の画像に設定されたラベルが1の場合、0.9などの低い値に変更します。この解決法は、ディスクリミネーターがその分類について自信過剰になること、言い換えれば、画像が本物か偽物かを判断するために非常に限られた特徴表現のセットに依存することを思いとどまらせます。
実際に非常にうまく機能することが示されているため、この小さなトリックを完全に支持します。コード内の1文字または2文字を変更するだけで済みます。
(8)マルチスケールグラディエント
MNIST内の画像のような小さい画像ではなくある程度大きな画像を扱う場合は、マルチスケールグラディエント(Multi Scale Gradient)を考慮する必要があります。
これは、2つのネットワーク間の複数のスキップ接続のおかげで、ディスクリミネーターからジェネレーターへ勾配フローを作成する特別なGAN実装です。セマンティックセグメンテーションに従来使用されていたU-Netで行われている事と同様です。
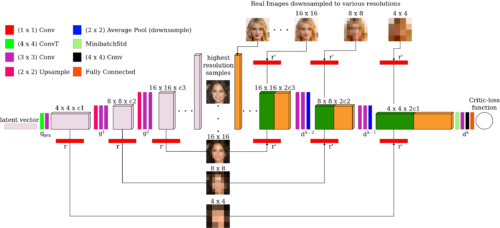
MSG-GANの概要
マルチスケールグラディエントに関する論文の著者は、GANをトレーニングして、特定の障害(モード崩壊など)なしで高解像度1024×1024画像を直接生成する事ができましたが、従来はこれは、徐々に成長するGAN(NvidiaによるProGAN)でのみ可能でした。
私は自分のプロジェクトのためにそれを自分で実装しました、そして私はより安定したトレーニングと説得力のある結果に気づきました。詳細については論文「MSG-GAN: Multi-Scale Gradients for Generative Adversarial Networks」をチェックして試してみてください!
(9)TTUR
私がTwo Time-Scale Update Rule(TTUR)と言えば、貴方はGANのトレーニングで採用されている複雑で理論整然とした手法について話していると思うかもしれませんが、それはまったく間違っています。
TTURは、ジェネレーターとディスクリミネーターに異なる学習率を選択する事だけで構成されており、それだけです。TTURが最初に紹介された論文で、著者はナッシュ均衡への収束の数学的証明を提供し、様々な学習率を使用して有名なGAN(DCGAN、WGAN-GP)を実装すると最先端の結果が得られることを示しました。
しかし、「異なる学習率を使用する」とは、実際にはどういう意味なのでしょうか?
一般には、ディスクリミネーターには高い学習率を選択し、ジェネレーターには低い学習率を選択することをお勧めします。
このようにする事で、ジェネレーターは、ディスクリミネーターをだますために小さなステップを多数踏む必要が出て来るため、敵対的なゲームに勝つために、速くとも正確でなく、現実的でない解決策を選択しなくなります
実際の例を挙げると、ディスクリミネーターに0.0004、ジェネレーターに0.0001を選択することがよくありますが、これらの値が一部のプロジェクトでうまく機能することがわかりました。TTURを使用すると、ジェネレータの損失が大きくなる可能性があることに注意してください。
(10)スペクトルの正規化
SAGAN(またはSelf Attention GAN)を紹介する論文など、多くの論文で、畳み込みカーネルに適用される特定の種類の正規化であるスペクトル正規化がトレーニングの安定性に大いに役立つことが示されています。
最初はディスクリミネーターでのみ使用されましたが、後でジェネレーターの畳み込み層でも使用すると効果的であることが示されました。この決定は完全に支持することができます。
私のGAN探索は、スペクトル正規化の発見と実装により、探索の方向性が変わったと言っても過言ではありません。率直に言って、自分で使用しない理由はありません。劇的に改善されることはほぼ間違いありません。ディープラーニングプロジェクトの他のより楽しい側面に集中できるようにしながら、より安定したトレーニングを提供します。(詳細については、論文How does Lipschitz Regularization Influence GAN Training?を参照してください)
結論
他の多くのトリック、より洗練された技術と設計がGANトレーニングの問題に終止符を打つことを約束します。本記事では、私が遭遇した障害を克服するために私が個人的に見つけて実装した方法について説明したいと思いました。
従って、ここに示されている各方法とトリックについて理解しているときに行き詰まった場合は、他に調査すべき資料がたくさんあります。数え切れないほどの時間を費やして、GANに関連する問題のすべての可能な解決策を研究して試した後、私は自分のプロジェクトにはるかに自信を持っており、あなたが同じことをできることを本当に望んでいます。
最後になりましたが、この記事を読んで注目していただき、誠にありがとうございます。
あなたが何かためになるものを獲得していただければ幸いです。
どうもありがとうございました、そしてあなたのGANの冒険を楽しんでください!
3.GANのトレーニングに役立つ10のヒント関連リンク
1)towardsdatascience.com
10 Lessons I Learned Training GANs for one Year
2)arxiv.org
Spectral Normalization for Generative Adversarial Networks
MSG-GAN: Multi-Scale Gradients for Generative Adversarial Networks
How does Lipschitz Regularization Influence GAN Training?

