
1.YouTubeストーリーで人の声だけ音量を上げる(2/2)まとめ
・Looking to Listenはノイズを完全分離していたがユーザは一部を残す事を好んでいた
・年齢、肌の色、言語、声の高低、話者の顔の視認性により偏りがないようにチェックした
・YouTubeストーリー(iOS)など様々な場面でLooking to Listenを使った新機能が登場予定
2.Looking to Listenの性能
以下、ai.googleblog.comより「Audiovisual Speech Enhancement in YouTube Stories」の意訳です。元記事の投稿は2020年10月1日、Inbar MosseriさんとMichael Rubinsteinさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Anastase Maragos on Unsplash
これらの最適化と改善により、Looking to Listenの実行時間はデスクトップPCを使ったリアルタイム処理で10倍改善され、iPhoneのCPUのみを使用したリアルタイムのパフォーマンスで0.5倍に短縮されました。モデルサイズは120MBから6MBに縮小され、製品展開が容易になりました。
YouTubeストーリーの動画は15秒に制限されているため、ビデオ録画が終了してから数秒以内に動画処理をした結果を利用できます。
最後に、(不必要な計算を避けるために)音声がハッキリしているビデオを処理しないようにするために、ビデオの最初の2秒間だけに対してモデルを実行し、次に声の音量を上げた音声と元の入力音声を比較します。
十分な違いがある場合(モデルが音声を聞き取りやすくした事を意味します)、ビデオの残りの部分全体でも音声強調処理を行います。
ユーザーのニーズの調査
「Looking to Listen」の初期バージョンは、音声をバックグラウンドノイズから完全に分離するように設計されていました。
YouTubeチームと一緒に実施したユーザー調査では、ユーザーは撮影場面の状況がわかるようにし、場面の雰囲気を維持するために、背景音の一部を残す事を好むことがわかりました。このユーザー調査に基づいて、元の音声と生成されたクリーンな音声チャネルの線形結合を行います。
output_audio = 0.1 x original_audio + 0.9 x 分離した音声
以下のビデオは、風景内の様々なレベルの背景音と組み合わせたクリーンなスピーチを示しています。(背景音10%が実際に使用されているバランスです)
以下は、YouTubeストーリーの新しい音声強調機能によって強調された音声結果の追加サンプルです。優れたスピーカーまたはヘッドホンでビデオを視聴することをお勧めします。
公平性の分析
もう1つの重要な要件は、モデルが公正で包括的であることです。さまざまな種類の声、言語、アクセント、およびさまざまな視覚的外観を処理できる必要があります。
この目的のために、様々な視覚的および音声/聴覚属性に関してモデルのパフォーマンスを調査する一連のテストを実施しました。
話者の年齢、肌の色、言語、声の高低、話者の顔の視認性(動画内に顔が写っているフレームは何%か?))、動画内に写っている頭部のポーズ、顔の毛、眼鏡の存在、および動画内のバックグラウンドノイズのレベルなどです。
上記の視覚/聴覚属性のそれぞれについて、学習用データセットとは別の評価用データセットでモデルを実行し、様々な属性値に従って分類された音声強調の精度を測定しました。
一部の属性の結果は、次の図に要約されています。図内の各データは、基準に適合する数百(ほとんどの場合は数千)のビデオを表現しています。
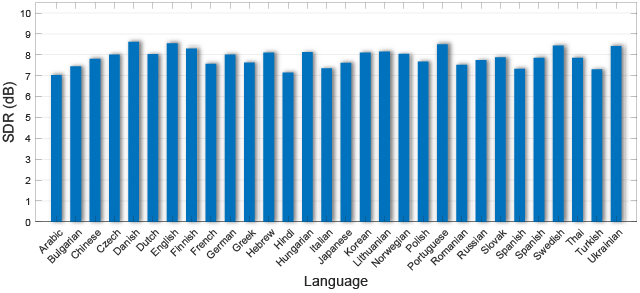
アルファベット順にソートされた、様々な言語での音声強調品質(信号対歪み比、SDR、dB単位)。平均SDRは7.89dBで、標準偏差は0.42dBでした。これは、人間のリスナーにとっては気づきにくいと考えられている偏差です。
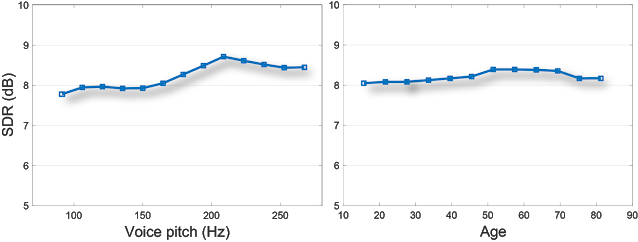
左:話者の声の高さと音声強調品質の関係。成人男性の基本的な音声周波数(声の高低)は通常85~180Hzの範囲であり、成人女性の基本的な音声周波数は165~255Hzの範囲です。
右:話者の予測年齢と音声強調品質の関係
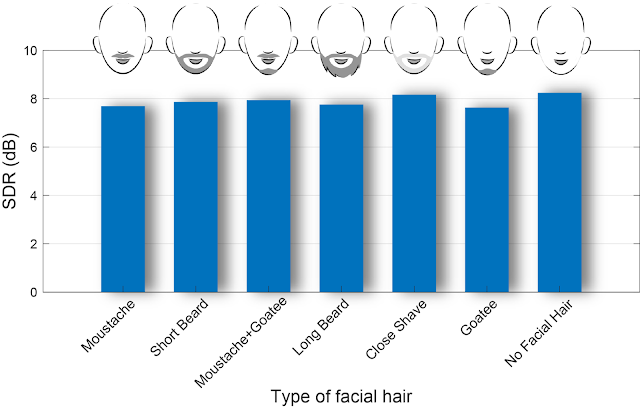
私達の手法では、顔の手がかりと口の動きを利用して音声を分離するため、顔の毛(口ひげ、あごひげなど)がこれらの視覚的な手がかりを妨げ、パフォーマンスに影響を与える可能性があるかどうかをテストしました。私達の評価は、顔に毛が存在する場合でも音声強調の品質が良好に維持されることを示しています。
機能の活用
YouTubeストーリーを作成可能なYouTubeクリエイターは、iOSで動画を録画し、音量調節編集ツールから[音声を強化]を選択できます。
これにより、音声強調がオーディオトラックにすぐに適用され、音量が大きくなった音声がループ再生されます。その後、機能のオンとオフを複数回切り替えて、強化された音声を元の音声と比較することができます。

YouTubeのこの新機能と並行して、本テクノロジーを追加する他の場所も模索しています。
今年後半にはもっと色々な形でこの機能を利用できるようになりますのでお楽しみに!
謝辞
この機能は、Googleの複数のチーム間のコラボレーションです。
主な貢献者は次のとおりです。Research-ILから:Oran Lang、VisCAMから:Ariel Ephrat、Mike Krainin、JD Velasquez、Inbar Mosseri、Michael Rubinstein、Learn2Compressから:Arun Kandoor、MediaPipeから:Buck Bourdon, Matsvei Zhdanovich, Matthias Grundmann、YouTubeから:Andy Poes, Vadim Lavrusik, Aaron La Lau, Willi Geiger, Simona De Rosa, 及び Tomer Margolin。
3.YouTubeストーリーで人の声だけ音量を上げる(2/2)関連リンク
1)ai.googleblog.com
Audiovisual Speech Enhancement in YouTube Stories
2)arxiv.org
Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
3)looking-to-listen.github.io
Looking to Listen at the Cocktail Party:A Speaker-Independent Audio-Visual Model for Speech Separation
4)support.google.com
YouTube Stories for creators

